







一、背景介绍
从用户体量上看,我们公司日活2kw,从机器角度看,大大小小加起来几百个微服务同时运行, 在没有灰度平台之前, 或者说依托传统基于Nginx等代理服务器灰度粒度较粗,无法在出现问题时做到精细化控制,导致大批量用户流量进入异常节点,随着业务发展,服务发版带来的业务影响是越来越不可接受的,到回滚结束,所付出的代价是线性甚至几何增加的

介于该背景下,我们C端平台开始着手从精细化控制服务流量角度出发去规避上线带来的影响, 依托灰度平台结合不同的业务场景进行使用
尽管我们也有测试同学,但是由于测试环境数据的局限性,以及来自用户操作不确定性或者代码对NPE等问题校验不充分,仍然会存在未能在测试、预发场景下复现的case
二、架构图
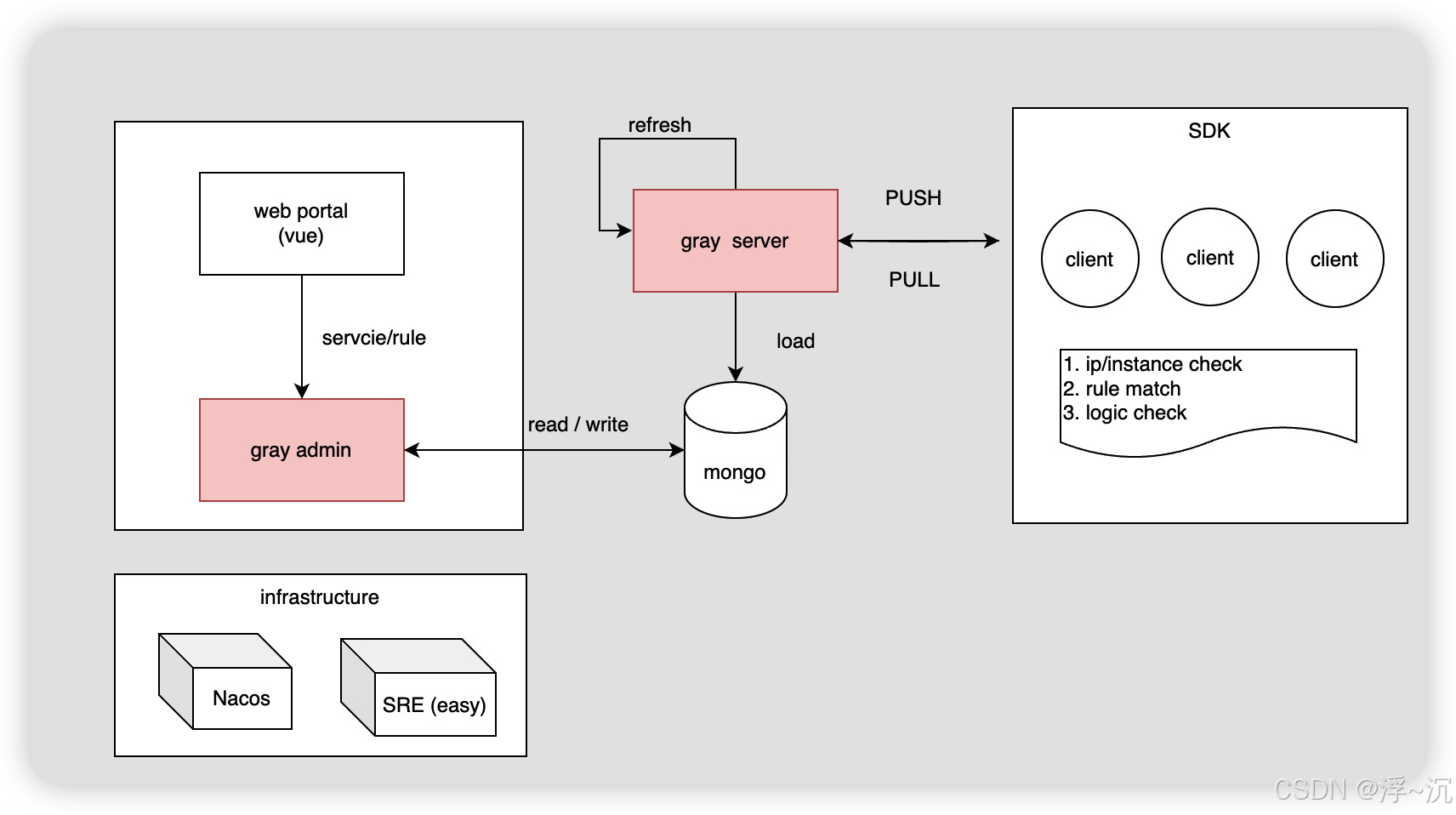
交互解释:
| client、sdk | 运行的微服务实例 or 节点 |
| infrastructure | 注册中心、运维平台 |
| gray server | 灰度服务端,承接来自客户端规则请求,由于有本地缓存,无需保障高可用 |
| gray admin | 灰度管理端,负责灰度规则持久化、API操作注册中心,查询运维平台实例信息 |
| web portal | 灰度界面UI,包括灰度管理、权限管理、操作日志 |
三、能力拆解
通过对现有上线问题进行集中反馈,我们将流量控制分为两类:业务灰度 和 流量灰度
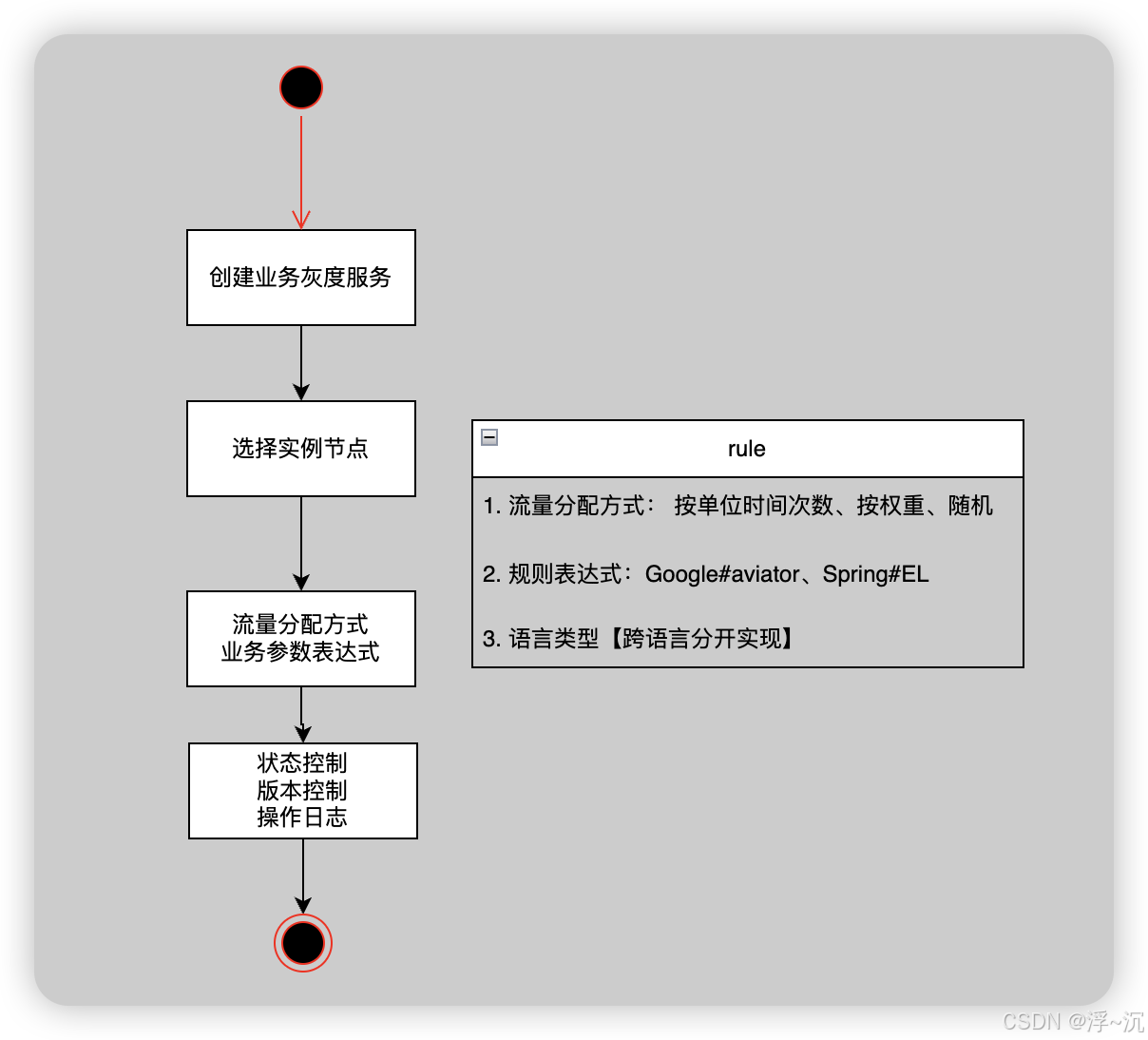
2.1 业务灰度
解决业务迭代过程中新老版本的兼容问题,比如我们最常见的就是A方法增加或者移除了一块逻辑,尽管有测试同学可以如何保证增量逻辑,按传统方式
- 发布单台实例观察,实际对于你的业务属性:用户、城市来说 从全局看改单台承载仍然是100%业务流量,因此粒度太粗,影响太大
特别是你按用户、城市、商户来分表 那么在异常后你要修复的数据的话改有多么恐怖 ,当然如果是一些管理后台或者访问频次低的项目这么做是合理的
- 依托注册中心例如Nacos#Metadata、或者Nginx等做流量分配,依赖运维,沟通繁琐
可行,但是回到现实场景来看,这些操作一般来说不会交给研发管理,由sre统一维护,试想这么多微服务,如果每次上线都依赖运维同学,且不说人员资源是否足够,例如集中上线日多个实例需要灰度,一次两次好说,时间久了 沟通协作难免受挫
灰度平台的做法是: 通过实例启动内置SDK向灰度服务端查询灰度规则,再和本地业务逻辑进行匹配,通过则走新逻辑,不通过继续走老逻辑,在分配上规则可以支持从秒级到天级别的请求数控制,例如10分钟触发1次、 2个小时触发10次等,当然也支持权重
有人也许提出质疑,从你的架构中也需要依赖运维同学?
是的,但是我们只在项目设计之处沟通1次,即他们向我们提供API查询即可,在如今CI/CD场景下这类都不需要他们二次开发,一定存在这样的能力,所以我们只需要拿过来用,唯一需要注意调用频次即可,实际上从灰度使用过程中来看这个频次远远小于我们日常工作请求运维平台,所以都是可闭环的
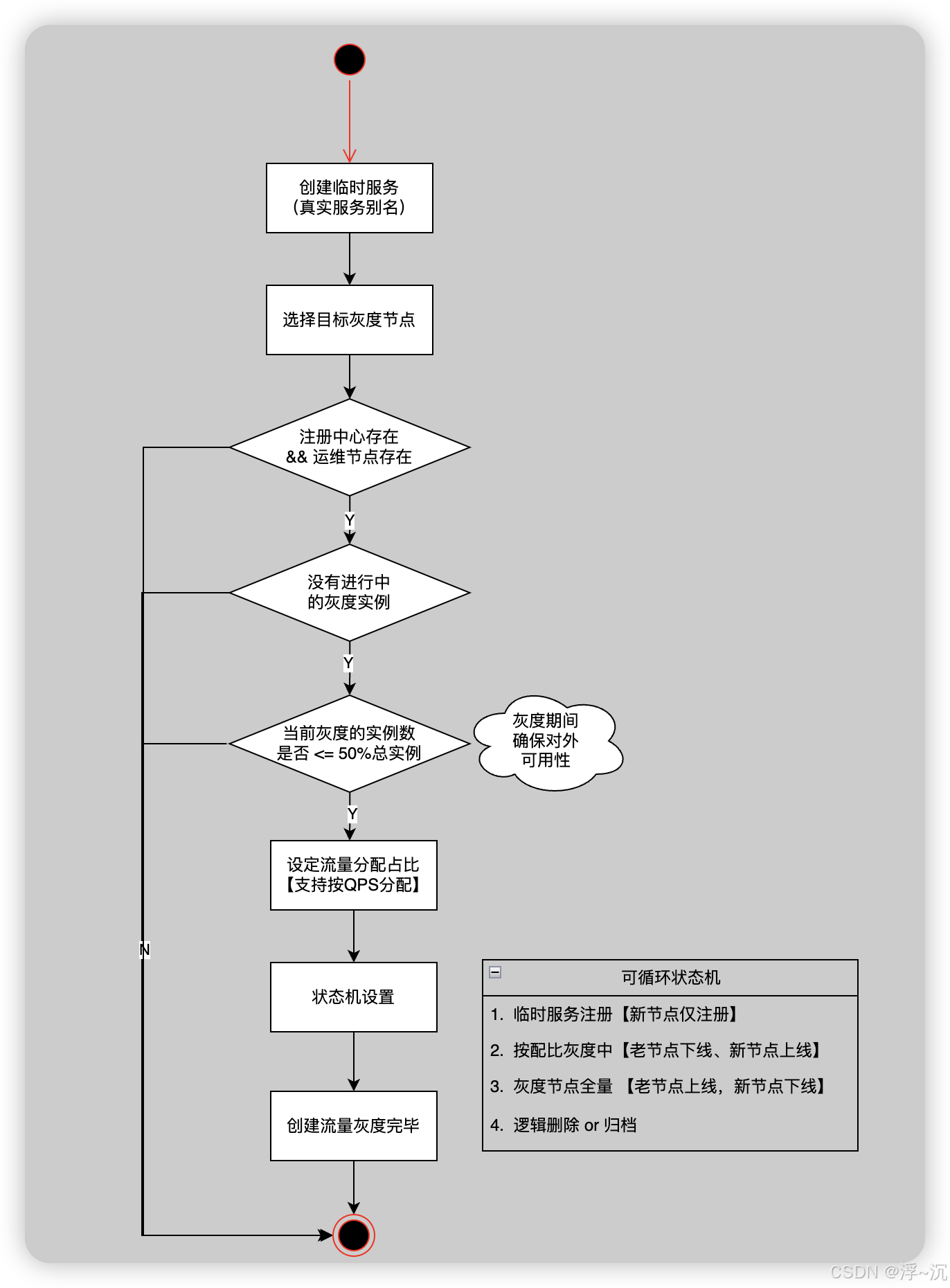
2.2 流量灰度
非业务场景的升级迭代,例如底层技术组件变更:Redis从单节点扩容到集群、某个节点连接的MySQL主从切换等等 ,这种改动多半都会对全局流量造成波动,且该场景出现的问题导致系统不可用的风险是最高的
灰度平台也和传统做法类似但灵活度更高,我们将流量操作收敛到研发手中,可以自由指定流量分配比例,提升服务部署的自由度和便捷性,也是提效的关键
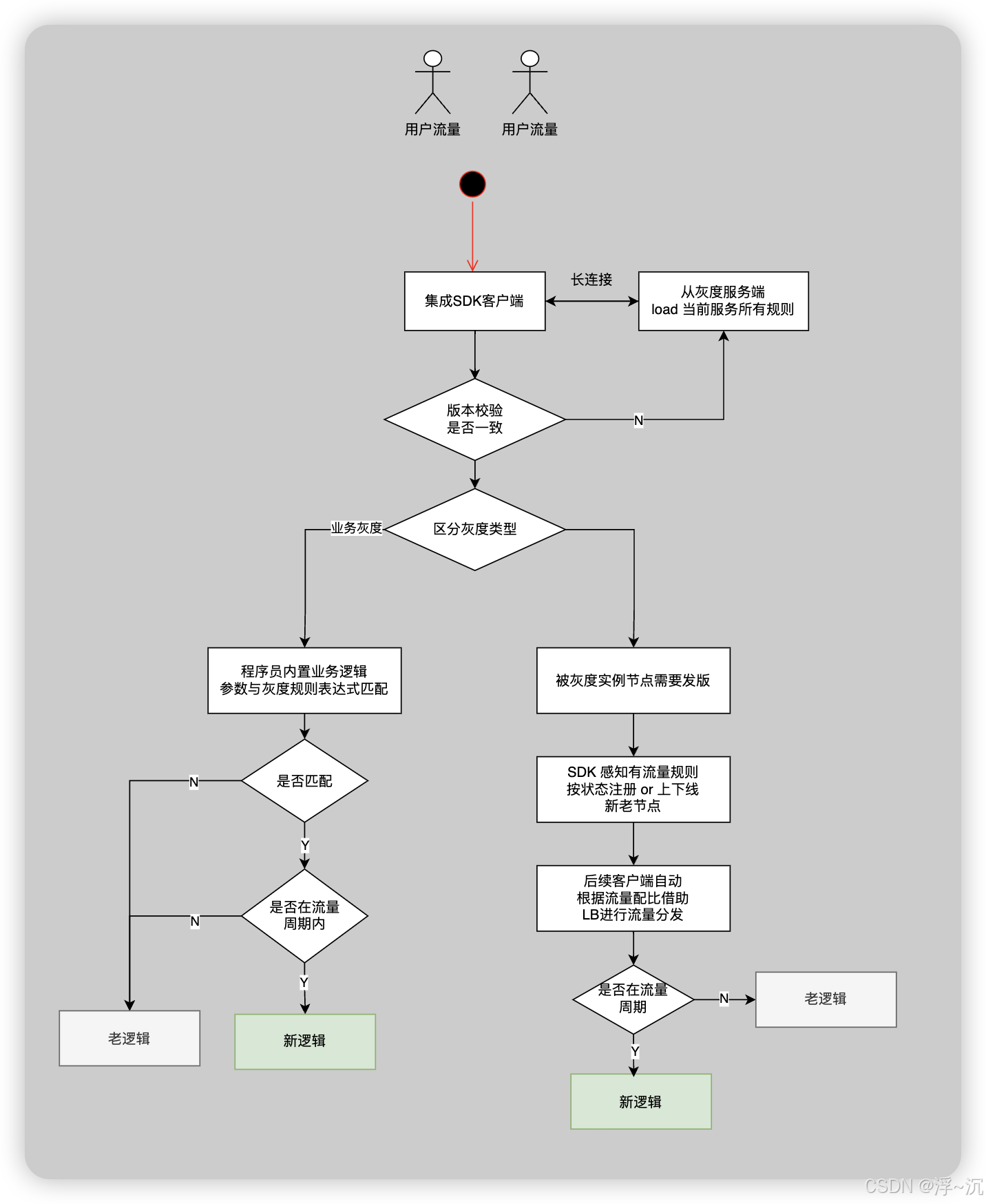
客户端流程
四、落地注意
- 流量灰度有一定操作风险,一方面是本身是牺牲一台or指定几台节点流量去做新逻辑验证,因此使用前最好确保其余节点承载压力,建议是低峰期操作
- 注册中心一般来说大家都会选择Nacos,迟迟不提该组件的原因无外乎两点:出于通用架构考虑 、Nacos OpenAPI 文档过于模糊且存在一定bug,笔者曾有幸全淌了一遍,感兴趣可以看看:「前车之鉴」Nacos OpenAPI 1.x操作各项踩坑专辑,你遇到过几个?-优快云博客


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









