





 本文介绍如何使用Word2Vec算法训练文本数据集,包括模型的保存与加载,以及如何通过TSNE降维和绘图展示词向量的关系。
本文介绍如何使用Word2Vec算法训练文本数据集,包括模型的保存与加载,以及如何通过TSNE降维和绘图展示词向量的关系。
训练并保存模型
def train_savemodel():
model = Word2Vec(PathLineSentences(directory), size=400, window=5, min_count=5, workers=multiprocessing.cpu_count(),
sg=1, # 使用 skip-gram算法
hs=1, # 使用分层softmax
negative=0) # 不使用负采样和噪音
model.save(modelpath)
model.wv.save_word2vec_format(wv_path, binary=True)
加载模型
def loadmodel():
en_wiki_word2vec_model = Word2Vec.load(modelpath)
return en_wiki_word2vec_model
加载wv,如果不需要再次训练模型,那么只需要恢复wv就可以了,wv是去除了model中的权重参数和损失等细节的,可以直接用于查询。
def loadwv():
word_vectors = KeyedVectors.load_word2vec_format(wv_path, binary=True)
return word_vectors
打印每一个词以及他的相近的词
most_similars_pre = {word : md.wv.most_similar(word) for word in md.wv.index2word}
for i, (key,word) in enumerate(most_similars_pre.items()):
if i == 10:
break
print(key,word)
使用TSNE降维(这个操作很费时间),打印关系图:
def reduce_dimensions(model):
num_dimensions=2
vectors =[]
labels = []
for word in model.wv.vocab:
vectors.append(model.wv[word])
labels.append(word)
vectors=np.asarray(vectors)
labels =np.asarray(labels)
#使用t-sne降低维度
vectors=np.asarray(vectors)
tsne =TSNE(n_components=num_dimensions, random_state=0)
vectors = tsne.fit_transform(vectors)
x_vals =[v[0] for v in vectors]
y_vals =[v[1] for v in vectors]
return x_vals,y_vals,labels
def plot_with_plotly(x_vals, y_vals, labels, plot_in_notebook=True):
from plotly.offline import init_notebook_mode,iplot,plot
import plotly.graph_objs as go
trace =go.Scatter(x=x_vals,y=y_vals,mode='text',text=labels)
data = [trace]
if plot_in_notebook:
init_notebook_mode(connected=True)
iplot(data,filename='word-embedding-plot')
else:
plot(data, filename='word-embedding-plot.html')
def plot_with_matplotlib(x_vals, y_vals, labels):
import matplotlib.pyplot as plt
import random
random.seed(0)
plt.figure(figsize=(12,12))
plt.scatter(x_vals,y_vals)
indices =list(range(len(labels)))
selected_indices = random.sample(indices,25)
for i in selected_indices:
plt.annotate(labels[i], (x_vals[i],y_vals[i]))
plt.show()
x_vals, y_vals, labels =reduce_dimensions(md)
try:
get_ipython()
except Exception:
plot_function = plot_with_matplotlib
else:
plot_function = plot_with_plotly
plot_function(x_vals,y_vals,labels)
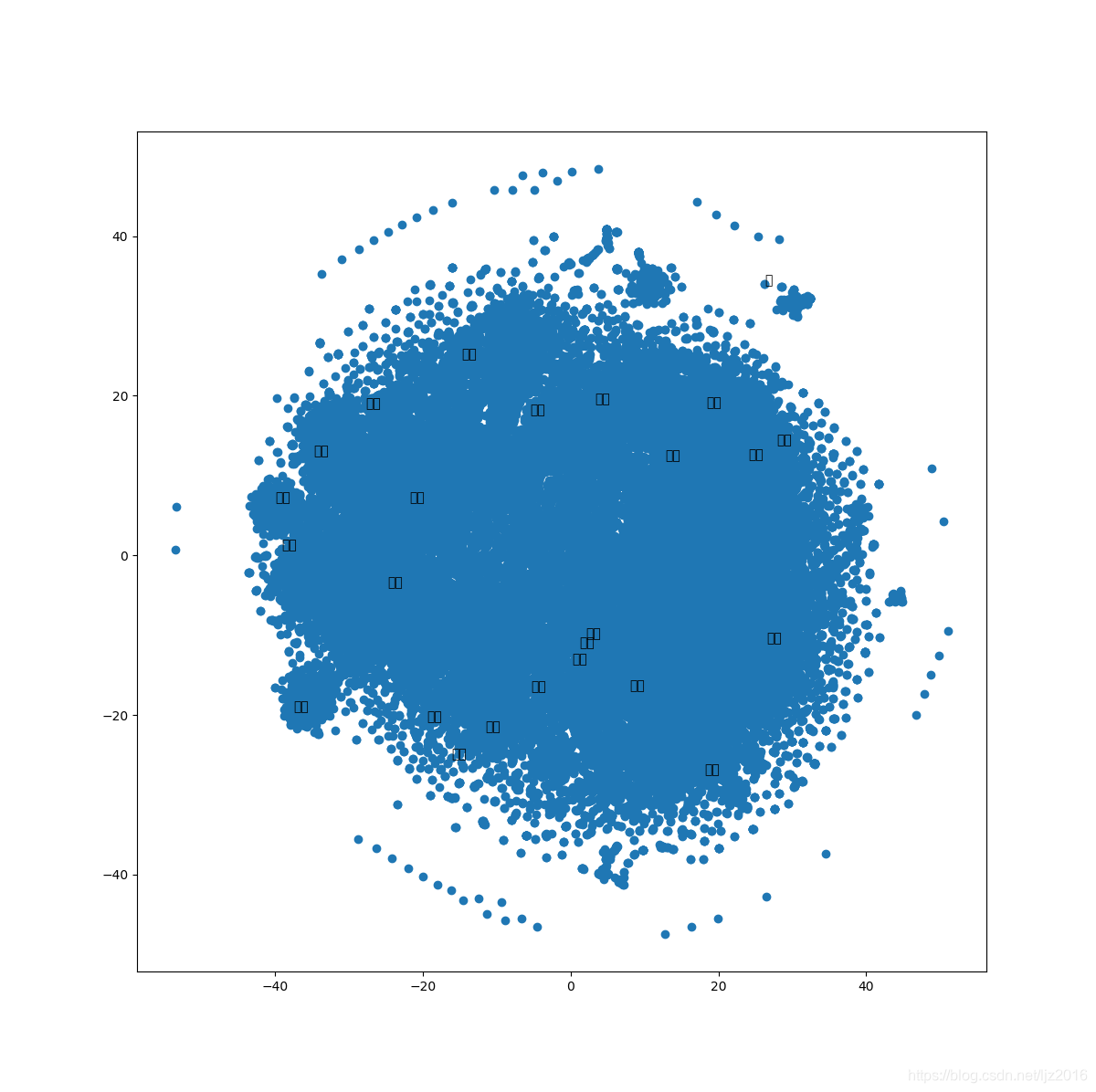
跑了半个小时的一张图

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









