 Spark中的map,flatMap与reduceByKey在WordCount应用,
Spark中的map,flatMap与reduceByKey在WordCount应用,





 文章详细介绍了Spark中map和flatMap操作,以及在WordCount例子中如何使用reduceByKey进行数据聚合。通过实例展示了如何对相同key的value进行求和或取最大值等操作,强调了预聚合优化和reduceByKey的shuffle过程。
文章详细介绍了Spark中map和flatMap操作,以及在WordCount例子中如何使用reduceByKey进行数据聚合。通过实例展示了如何对相同key的value进行求和或取最大值等操作,强调了预聚合优化和reduceByKey的shuffle过程。
spark map和flatMap
val rdd = sc.parallelize(List("coffee panda","happy panda","happiest panda party"))
(1)map
rdd.map(_.split(" ")).collect
// 等价于 rdd.map(x => x.split(" ")).collect
map结果
Array[Array[String]] = Array(Array(coffee, panda), Array(happy, panda), Array(happiest, panda, party))
(2)flatMap
rdd.flatMap(_.split(" ")).collect
// 等价于 rdd.flatMap(x => x.split(" ")).collect
flatMap结果
Array[String] = Array(coffee, panda, happy, panda, happiest, panda, party)
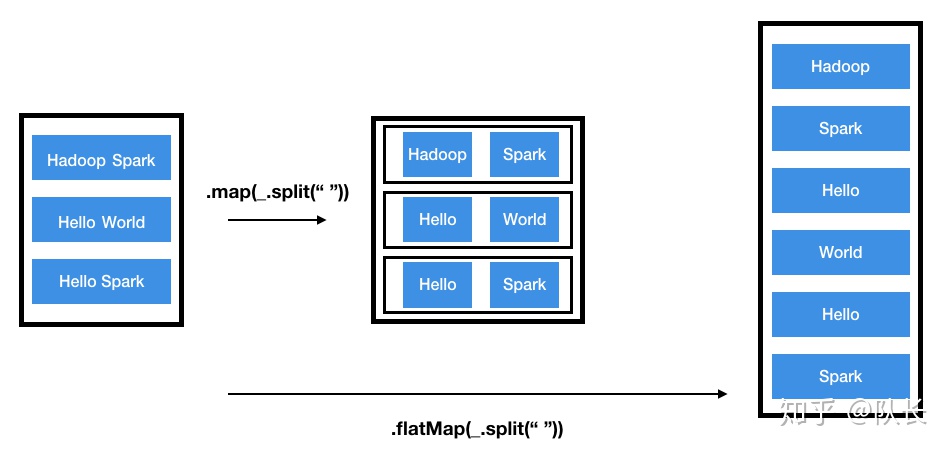
应用:Word Count
val rdd = sc.parallelize(List("coffee panda","happy panda","happiest panda party"))
val wordWithCount1 = rdd.flatMap(_.split(" ")).map(x=>(x,1))
wordWithCount1.collect
// Array[(String, Int)] = Array((coffee,1), (panda,1), (happy,1), (panda,1), (happiest,1), (panda,1), (party,1))
// map(x=>(x,1)) 等价于 map((_, 1))
val wordCounts = wordWithCount1.reduceByKey((x, y) => (x + y)).collect
// Array[(String, Int)] = Array((coffee,1), (happiest,1), (panda,3), (party,1), (happy,1))
// reduceByKey((x, y) => (x + y)) 等价于 reduceByKey(_+_)
// x,y代表同一个key的两个不同value
Scala允许使用”占位符”下划线”_”来替代一个或多个参数,只要这个参数值函数定义中只出现一次,Scala编译器可以推断出参数。
reduceByKey的用法
Spark的RDD的reduceByKey是使用一个相关的函数来合并每个相同key的value值的一个算子。要求前一步传入的数据必须是(key,value)类型。
Merge the values for each key using an associative and commutative reduce function. This will also perform the merging locally on each mapper before sending results to a reducer, similarly to a “combiner” in MapReduce.
https://blog.youkuaiyun.com/dong_lxkm/article/details/103125693
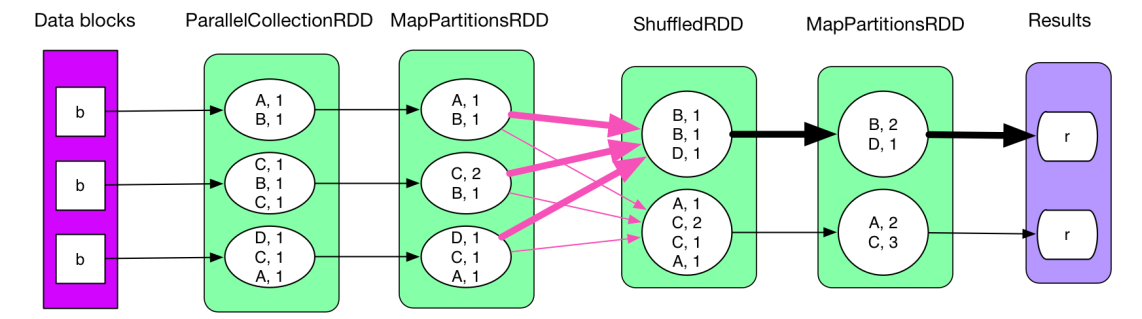
我理解的reduceByKey((x, y) => (x + y)),就是对于相同key的两个value,暂且将其命名为x和y,定义这两个value之间的计算关系为求和。(注意:聚合都是两两聚合的,超过两个会报错)
reduceByKey的shuffle: 相同的key移到同一个分区
MapPartitionsRDD是预聚合(groupByKey没有这种预聚合操作,所以速度慢)
同样的,比如改成reduceByKey((x, y) => if (x > y) x else y),那么就是两个value之间取max,最终得到的结果是对于相同的多个key,只取得了它们的values中最大的那个。
// 定义映射表的数组mp
val mp:Array[(String, Int)] = Array(
"coffee"->4,
"panda"->3,
"panda"->2,
"happiest"->2,
"panda"->1,
"happiest"->1)
val wordCounts = sc.parallelize(mp)
wordCounts.reduceByKey((x, y) => if (x > y) x else y).collect
// Array[(String, Int)] = Array((coffee,4), (happiest,2), (panda,3))


















 1549
1549

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











