







一、Scrapy框架安装
Scrapy的简介
Scrapy 是用纯python实现的为了爬取网络数据的,提取结构性数据而编写的应用型框架;Scrapy 使用了twisted异步网络框架来处理网络通信可以加快下载速度,不用自己去实现异步框架;并且包含了各种中间件接口 可以灵活地完成各种需求。
安装scrapy框架时,首先在终端下输入
pip install scrapy命令安装,提示:Faile building wheel for Twisted ; 用命令在终端下安装不成功可以安装whl格式的包
下载scrapy的whl的包:https://www.lfd.uci.edu/~gohlke/pythonlibs/
安装wheel的安装包需要安装wheel的库.在终端下运行
pip install wheelscrapy 依赖twisted所以要先安装twisted
安装twisted 下载地址:http://www.lfd.uci.edu/~gohlke/pythonlibs/
进入wheel包的文件夹,执行如下命令
pip install Twisted-17.1.0-cp36-cp64-win_and64.whl
scrapy还依赖lxml包 安装lxml 在终端下输入
pip install lxml二、scrapy爬虫命令行工具
首先在编译器中建一个文件夹scrapy,然后找到scrapy的路径并复制,打开命令终端输入cd加上刚复制scrapy的路径
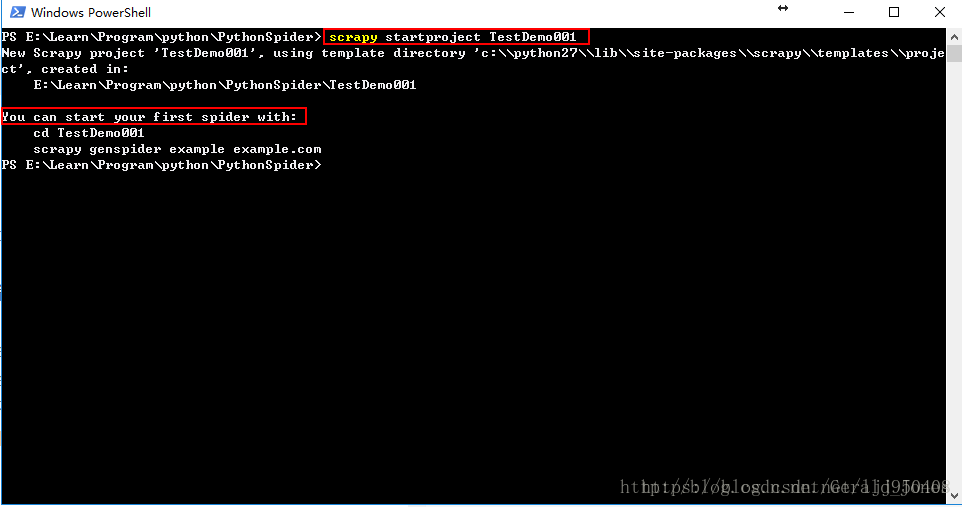
首先,创建项目命令——startproject,示例scrapy startproject TestDemo001;进入到相应的文件目录下,输入以上命令,则会在相应的文件目录下建立一个项目,如图:
genspider——通过模板生成scrapy爬虫,比如:scrapy genspider -d basic
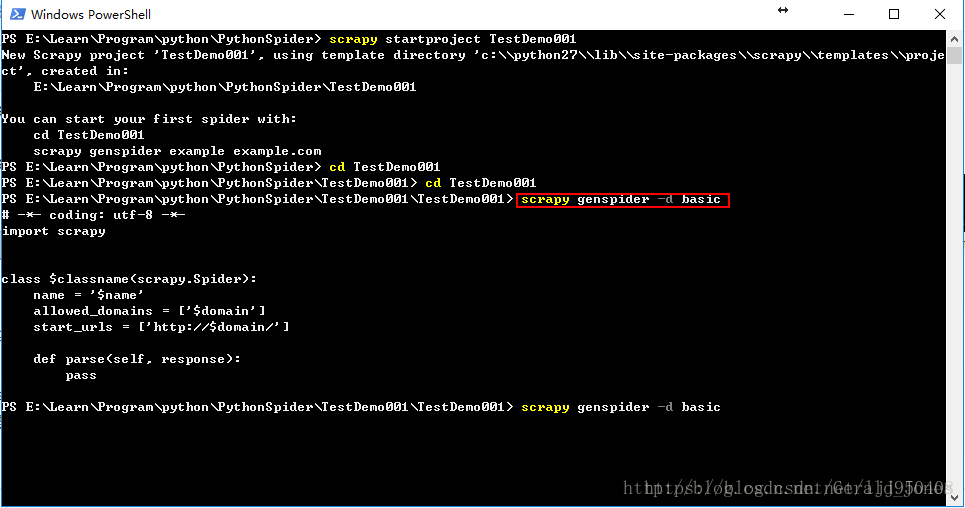
创建spider.py命令:scrapy genspider -t basic ytl yetianlian.com
![]()
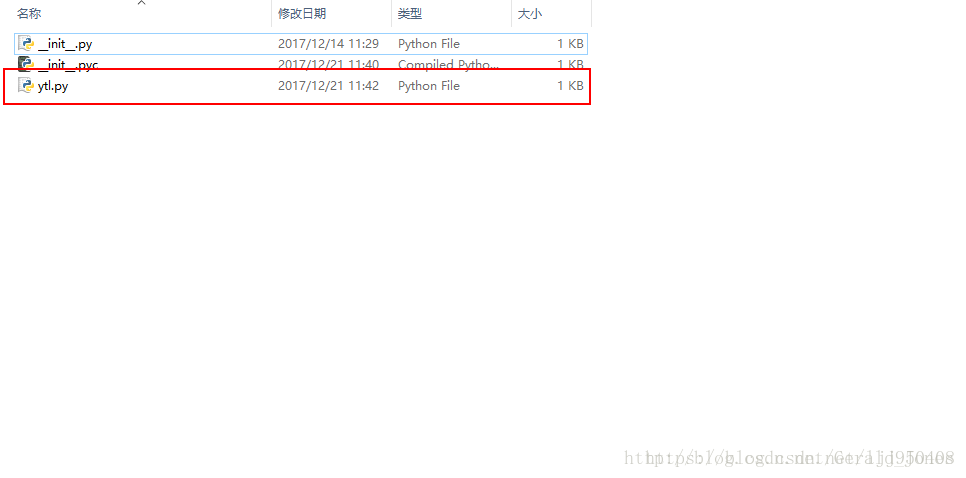
文件目录如图所示:
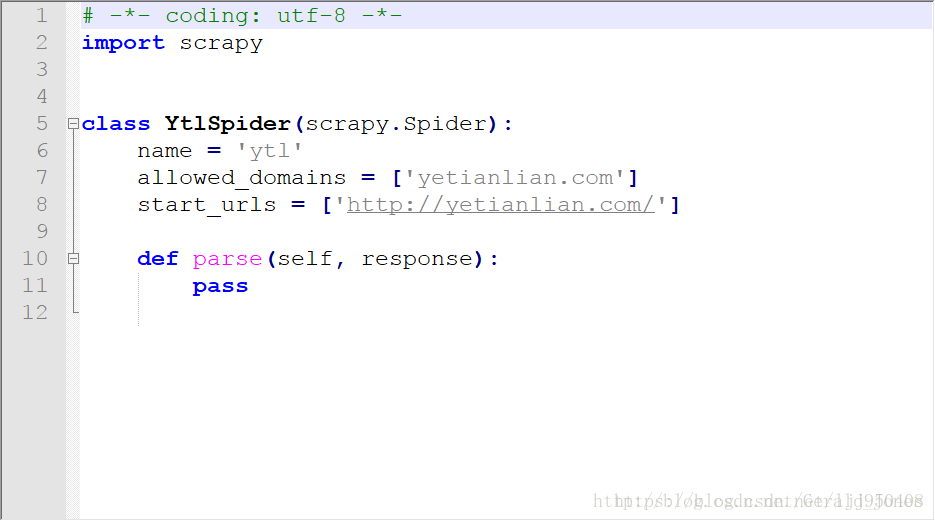
自动生成的代码如图所示:
crawl——启动爬虫命令,比如:scrapy crawl ytl 启动命名为ytl的爬虫,需要cd进入相应的文件目录下,运行该命令。
check——检查爬虫完整性,比如:scrapy check ytl,前提需要项目存在。
fetch——显示爬取过程,比如:scrapy fetch "http://www.yetianlian.com",命令其实是在标准输出中显示调用一个爬虫来爬 取指定的url的全过程。
bench——硬件测试命令,比如:scrapy bench

















 64万+
64万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









