










一、BEiT 简介
BEiT(BERT Pre-Training of Image Transformers)是一种借鉴 BERT 预训练范式的视觉模型,它将图像切分为若干 Patch,并在这些 Patch 上进行遮盖和预测任务(类似于 MLM)以进行表征学习。BEiT 主要用于图像分类、分割等下游任务,在 ImageNet 等多个数据集上表现优异。
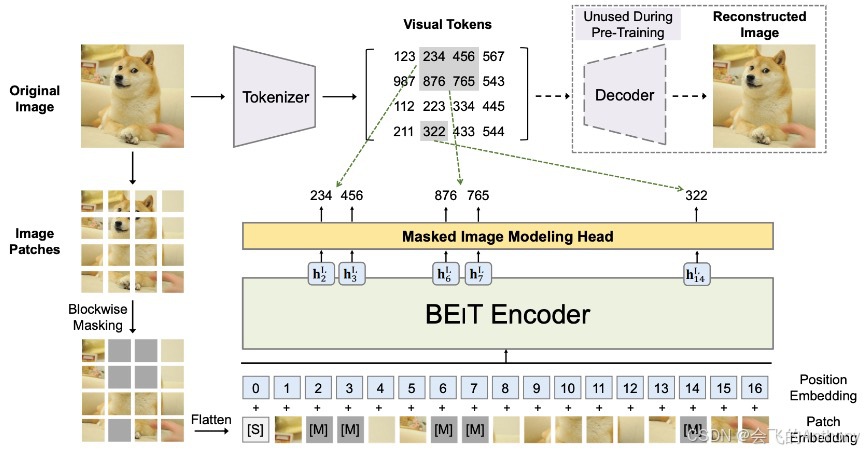
BEiT 的核心是使用 ViT 架构,将图像转化为 Patch 的 Token 序列,再使用 BERT 风格的 Masked Patch Prediction 进行预训练。
架构如下图所示:
二、环境准备与数据加载
import torch
import numpy as np
import matplotlib.pyplot as plt
from torchvision.datasets import MNIST
from torchvision.transforms import ToTensor, Grayscale
from torch.utils.data import DataLoader, random_split
# 设置设备
device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu")
print("Using device", device)
# 加载 MNIST,并转换为 3 通道图像
transform = Grayscale(num_output_channels=3)
full_dataset = MNIST(root='./data/', train=True, download=True, transform=transform)
train_size = int(0.8 * len(full_dataset))
val_size = len(full_dataset) - train_size
train_set, val_set = random_split(full_dataset, [train_size, val_size])
test_set = MNIST(root='./data/', train=False, download=True, transform=transform)
train_loader = DataLoader(train_set, batch_size=16, shuffle=True)
val_loader = DataLoader(val_set, batch_size=16)
test_loader = DataLoader(test_set, batch_size=16)
三、BEiT 模型构建
完整模型代码较长,核心结构包括:
-
Patch Embedding:使用卷积或线性层将图像划分为 Patch
-
Transformer Encoder:堆叠多个 Block,每个 Block 包含 Attention 和 Feedforward
-
Classification Head:最终取出 [CLS] token 送入线性层进行分类
Patch Embedding 模块
class PatchEmbed(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
x = self.proj(x)
x = x.flatten(2).transpose(1, 2) # [B, C, H, W] -> [B, N, D]
return x
BEiT 模型主体结构
class BEiT(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_chans=3, num_classes=10,
embed_dim=768, depth=12, num_heads=12, mlp_ratio=4.):
super().__init__()
self.patch_embed = PatchEmbed(img_size, patch_size, in_chans, embed_dim)
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.pos_drop = nn.Dropout(p=0.1)
self.blocks = nn.Sequential(*[
Block(embed_dim, num_heads, mlp_ratio) for _ in range(depth)
])
self.norm = nn.LayerNorm(embed_dim)
self.head = nn.Linear(embed_dim, num_classes)
def forward(self, x):
x = self.patch_embed(x)
cls_token = self.cls_token.expand(x.size(0), -1, -1)
x = torch.cat((cls_token, x), dim=1)
x = self.pos_drop(x)
x = self.blocks(x)
x = self.norm(x)
return self.head(x[:, 0])
四、训练与评估流程
import time
import torch.nn as nn
import torch.optim as optim
from tqdm.auto import tqdm
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.01)
训练与验证函数
def train(model, dataloader, optimizer, criterion, device):
model.train()
total_loss, correct = 0, 0
for x, y in tqdm(dataloader):
x, y = x.to(device), y.to(device)
optimizer.zero_grad()
preds = model(x)
loss = criterion(preds, y)
loss.backward()
optimizer.step()
total_loss += loss.item()
correct += (preds.argmax(1) == y).sum().item()
return total_loss / len(dataloader), correct / len(dataloader.dataset)
def evaluate(model, dataloader, criterion, device):
model.eval()
total_loss, correct = 0, 0
with torch.no_grad():
for x, y in tqdm(dataloader):
x, y = x.to(device), y.to(device)
preds = model(x)
loss = criterion(preds, y)
total_loss += loss.item()
correct += (preds.argmax(1) == y).sum().item()
return total_loss / len(dataloader), correct / len(dataloader.dataset)
训练主循环
best_valid_loss = float('inf')
train_losses, valid_losses = [], []
num_epochs = 5
for epoch in range(num_epochs):
start_time = time.time()
train_loss, train_acc = train(model, train_loader, optimizer, criterion, device)
valid_loss, valid_acc = evaluate(model, val_loader, criterion, device)
train_losses.append(train_loss)
valid_losses.append(valid_loss)
end_time = time.time()
mins, secs = divmod(int(end_time - start_time), 60)
print(f"Epoch {epoch+1:02} | Time: {mins}m {secs}s")
print(f" Train Loss: {train_loss:.3f} | Train Acc: {train_acc*100:.2f}%")
print(f" Valid Loss: {valid_loss:.3f} | Valid Acc: {valid_acc*100:.2f}%")
五、可视化训练结果
import matplotlib.pyplot as plt
plt.plot(train_losses, label='Train Loss')
plt.plot(valid_losses, label='Valid Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
六、最终测试评估
test_loss, test_acc = evaluate(model, test_loader, criterion, device)
print(f"Test Loss: {test_loss:.3f} | Test Acc: {test_acc*100:.2f}%")
七、对比 BERT 与 BEiT
| 模型 | 领域 | 输入单位 | 训练目标 |
|---|---|---|---|
| BERT | NLP | Token(词片段) | Masked Language Modeling |
| BEiT | CV | Patch(图像块) | Masked Image Modeling |
BEiT 本质上是把 NLP 的 BERT 迁移到了视觉世界,借助掩码学习、上下文对齐等机制,极大提升了图像编码器在预训练阶段的泛化能力。
八、小结
本篇文章基于 PyTorch 实现了 BEiT 模型在 MNIST 数据集上的训练与测试,并详细分析了其结构、训练流程及和 BERT 的异同。
你可以基于该实现,扩展到 CIFAR10、ImageNet 等更复杂的数据集,进一步发挥 BEiT 的能力。
敬请期待下一篇:《基于 Python 的自然语言处理系列(76):CLIP》。
如果你觉得这篇博文对你有帮助,请点赞、收藏、关注我,并且可以打赏支持我!
欢迎关注我的后续博文,我将分享更多关于人工智能、自然语言处理和计算机视觉的精彩内容。
谢谢大家的支持!



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











