










在前面多篇文章中,我们深入探讨了 Transformer 在自然语言处理中的应用,例如 BERT、GPT、T5 等模型。然而,Transformer 架构的强大之处并不仅限于文本数据。本文我们将目光投向图像领域,介绍一个将 Transformer 成功应用于计算机视觉任务的模型:Vision Transformer(ViT)。
一、ViT 简介
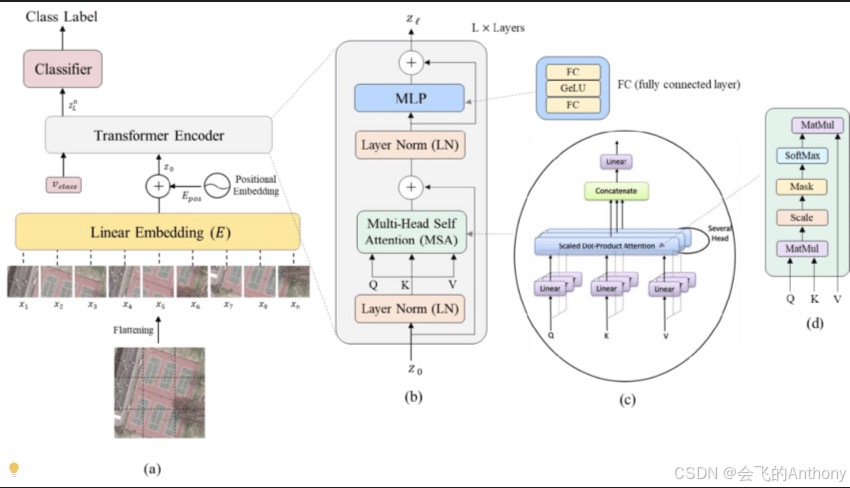
Vision Transformer(ViT)是 Google Research 于 2020 年提出的一个开创性模型,其核心思想是:将图像划分为小 patch,每个 patch 类似于一个“词”,然后将这些 patch 输入到标准的 Transformer 中进行建模。这种方法打破了传统基于卷积神经网络(CNN)的视觉模型架构,开启了计算机视觉领域的新篇章。
ViT 的论文题目为《An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale》,已被广泛引用和应用于多个图像识别任务中。
二、ViT 与 CNN 的对比
| 模型特点 | CNN | Vision Transformer |
|---|---|---|
| 局部 vs 全局 | 强调局部感受野 | 强调全局依赖建模 |
| 权重共享 | 局部卷积核共享 | 多头注意力权重不共享 |
| 可扩展性 | 局部特征堆叠逐步建模 | Transformer 可一次建模全局关系 |
| 数据需求 | 可在中小数据集训练 | 通常需要大规模预训练 |
三、ViT 架构解析
Vision Transformer 的核心结构与原始的 Transformer 编码器结构非常相似,主要包括以下几个步骤:
1. 图像划分为 patch
首先将输入图像(如 224x224)划分为固定大小的 patch(如 16x16),相当于将图像变成了 N 个 patch,每个 patch 展平成一个向量,相当于 NLP 中的词向量:
patch_size = 16
num_patches = (img_height // patch_size) * (img_width // patch_size)
2. Patch Embedding + 位置编码
每个 patch 会通过一个线性层映射为一个 d 维向量,并加上可学习的位置编码:
x = Linear(patch_dim, hidden_dim)(patches)
x = x + pos_embedding
3. 加入 CLS Token
在 patch 序列前加入一个 [CLS] token,其对应的输出将用于图像的分类任务:
cls_token = learnable_token
x = torch.cat([cls_token, x], dim=1)
4. 多层 Transformer 编码器
ViT 使用标准的 Transformer 编码器结构,即多头自注意力(Multi-Head Attention)+ 前馈网络(FeedForward)+ 残差连接与 LayerNorm:
for block in transformer_blocks:
x = block(x)
5. 分类头
取最终输出中 [CLS] token 对应的向量,送入一个 MLP Head 进行图像分类:
logits = MLPHead(x[:, 0])
四、ViT 实现(PyTorch 简洁版)
以下是 Vision Transformer 的简洁实现:
class PatchEmbedding(nn.Module):
def __init__(self, img_size, patch_size, in_chans, embed_dim):
super().__init__()
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
x = self.proj(x) # [B, D, H', W']
x = x.flatten(2).transpose(1, 2) # [B, N, D]
return x
class ViT(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_chans=3, num_classes=1000, embed_dim=768, depth=12, num_heads=12):
super().__init__()
self.patch_embed = PatchEmbedding(img_size, patch_size, in_chans, embed_dim)
num_patches = (img_size // patch_size) ** 2
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim))
encoder_layer = nn.TransformerEncoderLayer(embed_dim, num_heads, dim_feedforward=embed_dim*4)
self.transformer = nn.TransformerEncoder(encoder_layer, num_layers=depth)
self.head = nn.Linear(embed_dim, num_classes)
def forward(self, x):
x = self.patch_embed(x)
B, N, _ = x.shape
cls_tokens = self.cls_token.expand(B, -1, -1)
x = torch.cat((cls_tokens, x), dim=1)
x = x + self.pos_embed
x = self.transformer(x)
cls_out = x[:, 0]
return self.head(cls_out)
五、ViT 的优势与挑战
优势:
-
全局建模能力强:相较于 CNN,Transformer 更容易捕捉远距离依赖关系。
-
架构更通用:ViT 与 NLP 的 Transformer 架构统一,便于跨模态迁移学习。
挑战:
-
对数据量敏感:ViT 模型通常需要大量数据预训练(如 ImageNet-21K),在小数据集上容易过拟合。
-
缺少归纳偏置:ViT 不具备 CNN 的平移不变性等 inductive bias。
六、ViT 在 NLP 中的启发
尽管 ViT 本质上是图像模型,但它的提出对 NLP 也产生了许多启发:
-
NLP 模型也可考虑更灵活的 patch 级输入,比如在长文本处理上按段切片。
-
ViT 的成功再次印证了 Transformer 架构的通用性,也推动了多模态模型的发展(如 CLIP、BLIP)。
七、总结
本文介绍了 Vision Transformer(ViT)的原理与实现,展示了 Transformer 在图像领域的强大能力。虽然 ViT 最初是为视觉任务设计,但其思想对 NLP 模型设计亦有启示意义。未来多模态模型的发展,ViT 将继续扮演重要角色。
下一篇文章,我们将深入介绍 BEIT,进一步探索语言与视觉之间的融合建模。
敬请期待!
如果你觉得这篇博文对你有帮助,请点赞、收藏、关注我,并且可以打赏支持我!
欢迎关注我的后续博文,我将分享更多关于人工智能、自然语言处理和计算机视觉的精彩内容。
谢谢大家的支持!



















 565
565

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











