




 本文介绍了梯度下降法在寻找代价函数最小值时的原理和过程,包括沿着负梯度方向搜索、非凸函数的局部最优及鞍点问题。通过代码展示了梯度下降法的实现,并解释了随机梯度下降法如何解决鞍点问题,通过不断随机选取样本更新权重。最后,代码实现随机梯度下降法时未能体现其随机性,指出在大量数据下随机梯度下降的优势。
本文介绍了梯度下降法在寻找代价函数最小值时的原理和过程,包括沿着负梯度方向搜索、非凸函数的局部最优及鞍点问题。通过代码展示了梯度下降法的实现,并解释了随机梯度下降法如何解决鞍点问题,通过不断随机选取样本更新权重。最后,代码实现随机梯度下降法时未能体现其随机性,指出在大量数据下随机梯度下降的优势。
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
一、优化问题
求代价函数最小值

沿着负梯度的方向寻找最小值:
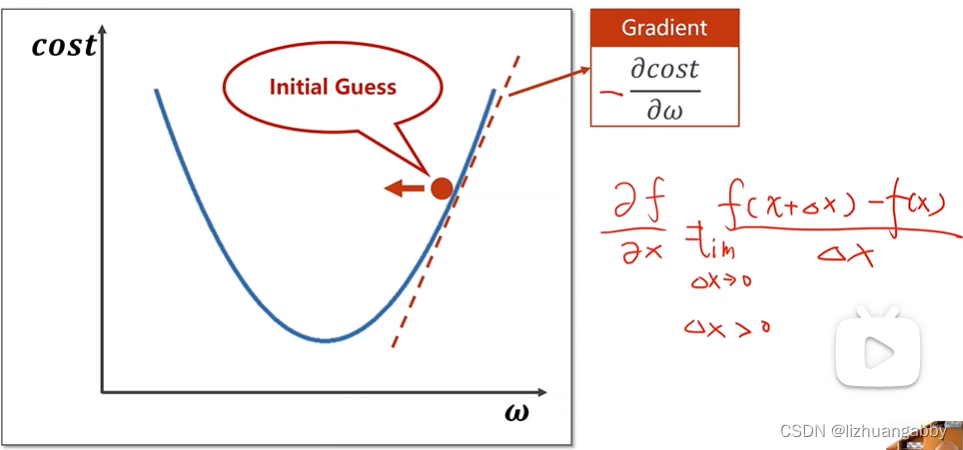
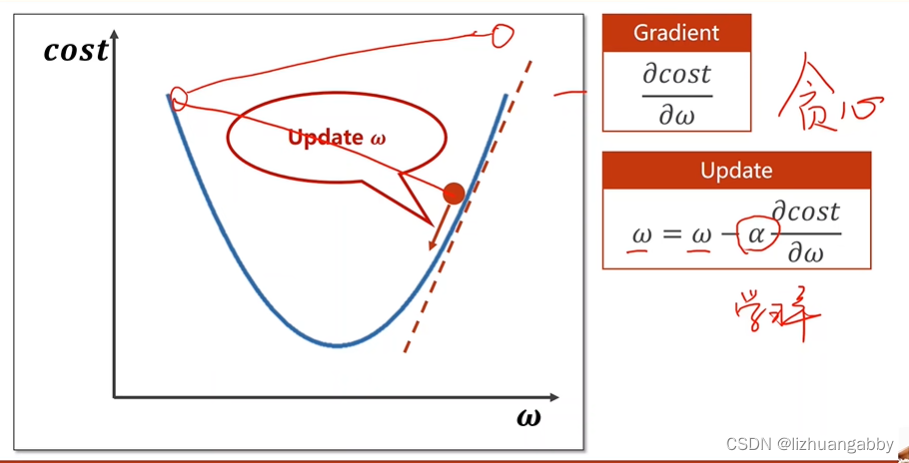
寻找过程类似贪心算法:
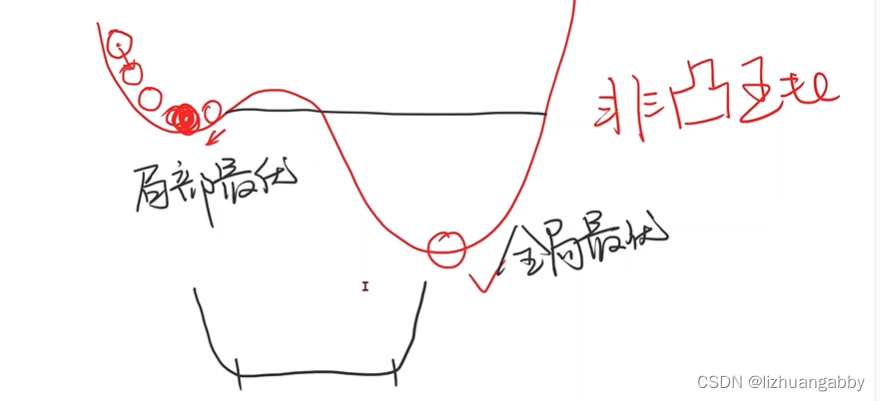
对于非凸函数,存在局部最优:
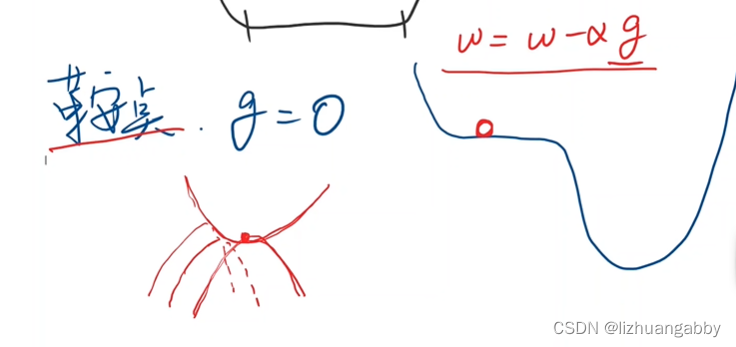
甚至有时会陷入鞍点:
梯度计算:


全局梯度下降->随机梯度下降
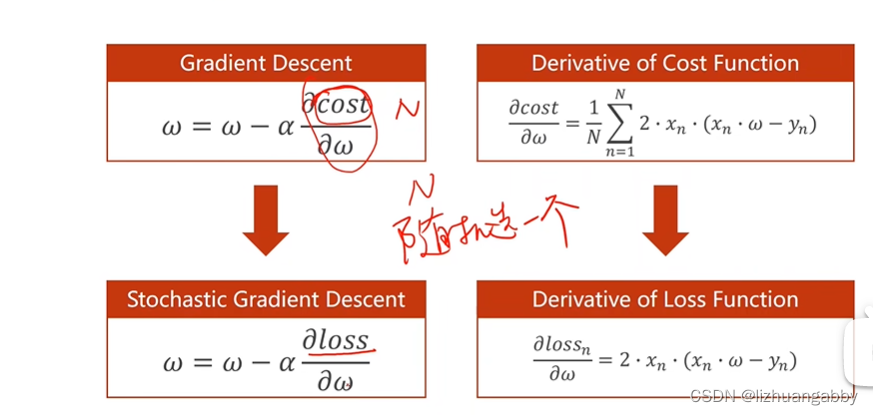
全局梯度下降:
随机梯度下降:
随机梯度下降主要是为了解决在机器学习过程中在遇到“鞍点”(即总体所有点的梯度和为0,导致w=w-0.01*0,w不会改变)而导致不能继续进行的问题。可以采用随机梯度下降,即随机的取一组(x,y)的梯度,作为梯度下降的依据,而不用总体所有点的梯度和,作为梯度下降的依据。

随机梯度下降法在神经网络中被证明是有效的。它的特点在于效率较低(时间复杂度较高),学习性能较好。
二、代码练习
梯度下降
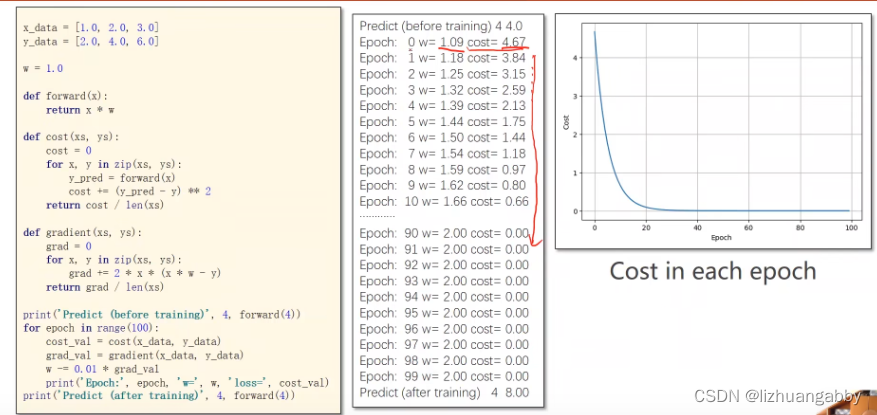
import numpy as np
import matplotlib.pyplot as plt
x_data = [1.0,2.0,3.0]
y_data = [2.0,4.0,6.0]
w = 1.0
# 前馈计算
def forward(x):
return x * w
#代价函数
def cost(xs,ys):
cost = 0
for x,y in zip(xs,ys):
y_pred = forward(x)
cost+= (y_pred-y) **2
return cost/len(xs)
# 梯度计算
def gradident(xs,ys):
grad = 0
for x,y in zip 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 833
833

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









