







🤔️ 你有没有想过,为什么ChatGPT、Sora这些AI应用能够如此“聪明”,仿佛真的理解了我们的意图?它们是如何从海量数据中提取关键信息,并给出令人惊艳的回答或创作?
🔑 答案就藏在“大模型”这三个字背后。今天,我们就来一起揭开大模型神秘的面纱,特别是其中最核心的两个概念:Attention机制和Transformer。
别担心,我们会用最通俗易懂的方式,让你彻底搞懂这些听起来高大上的技术!就像当年我们搞懂“互联网+”一样,这次,我们要搞懂“AI+”的核心驱动力!💪
1. 为什么我们要关注大模型?
想象一下,你是一位将军,需要根据战场上的各种信息(敌军位置、地形、天气等)做出决策。
* 传统方法: 你可能需要逐一听取每个侦察兵的报告,然后自己分析、判断。效率低,还容易遗漏重要信息。😫
* 大模型方法: 你拥有了一个超级参谋团,他们不仅能快速收集所有信息,还能自动筛选出最重要的情报,并给出建议。你只需要做最后的决策。😎
大模型就是这样的“超级参谋团”。它通过对海量数据的学习,能够:
* 理解你的意图: 不再需要死板的关键词,大模型能理解你自然、口语化的表达。
* 找到关键信息: 自动从大量数据中提取最重要的内容,节省你的时间和精力。
* 做出智能决策: 提供建议、生成内容、甚至进行预测,辅助你做出更优决策。
这就像给你的工作和生活装上了一个“加速器”,让你能够更高效、更智能地应对各种挑战。🚀

2. Attention机制:大模型的“注意力”从何而来?
在深入了解Attention机制之前,让我们先来做一个小游戏。请快速浏览下面的句子:
“昨天我买了一台新电脑,它的性能非常强大,运行速度很快,而且外观也很漂亮。”
现在,请你回忆一下,这句话中哪些词最重要?
你可能会注意到“新电脑”、“性能强大”、“运行速度快”、“外观漂亮”这些词。因为它们直接描述了这台电脑的特点。
这就是Attention机制的核心思想:让模型学会“关注”输入信息中最重要的部分。2.1 深度学习中如何引入Attention 机制
在Attention机制出现之前,传统的深度学习模型(如RNN、LSTM)在处理长文本时,往往会遇到“遗忘”的问题。就像你听一段很长的演讲,可能只记得最后几句话,而忽略了前面的重要内容。
Attention机制的引入,就像给模型配备了一双“慧眼”,让它能够:
1. 分解输入: 将输入的句子分解成一个个单词(或其他更小的部分)。
2. 挑选重要的部分: 计算每个部分与当前任务的相关性。
3. 分配重要性: 给每个部分打分,重要的部分得分高,不重要的部分得分低。
4. 集中注意力: 根据得分高低,决定对每个部分投入多少“注意力”。
5. 加权求和: 将所有信息汇总,但重要的信息权重更大。
这样,模型就能像人一样,抓住重点,忽略次要信息,从而做出更准确的判断。
2.2 Attention 机制如何起作用?
Attention机制的核心就是“加权求和”。
还是用上面的句子为例:
“昨天我买了一台新电脑,它的性能非常强大,运行速度很快,而且外观也很漂亮。”
假设我们要判断这台电脑是否值得购买。Attention机制会这样工作:
1. 分解: 将句子分解成一个个单词。
2. 挑选: 计算每个单词与“是否值得购买”这个问题的相关性。
3. 分配: “性能强大”、“运行速度快”、“外观漂亮”这些词得分高,“昨天”、“我”、“了”这些词得分低。
4. 集中: 更多地关注得分高的词。
5. 加权: 将所有信息汇总,但“性能强大”、“运行速度快”、“外观漂亮”这些词的权重更大。
最终,模型会得出结论:这台电脑非常值得购买!👍
2.3 全局注意力与局部注意力
* 全局注意力: 就像你阅读一篇文章时,会关注所有的段落和句子。
* 局部注意力: 就像你只关注文章的标题、摘要和结论。
全局注意力能够捕捉更全面的信息,但计算量大;局部注意力计算量小,但可能会遗漏重要信息。
2.4 软注意力与硬注意力
* 软注意力: 就像你对每个信息都给予一定的关注,只是关注程度不同。
* 硬注意力: 就像你只关注最重要的一两个信息,完全忽略其他信息。
软注意力更平滑,更容易训练;硬注意力更“果断”,但训练难度大。
3. Transformer:大模型的“骨架”
如果说Attention机制是大模型的“眼睛”,那么Transformer就是大模型的“骨架”。它提供了一种全新的、更高效的模型架构。
3.1 Transformer模型
Transformer模型主要由两部分组成:
* 编码器(Encoder): 负责理解输入序列。
* 解码器(Decoder): 负责生成输出序列。
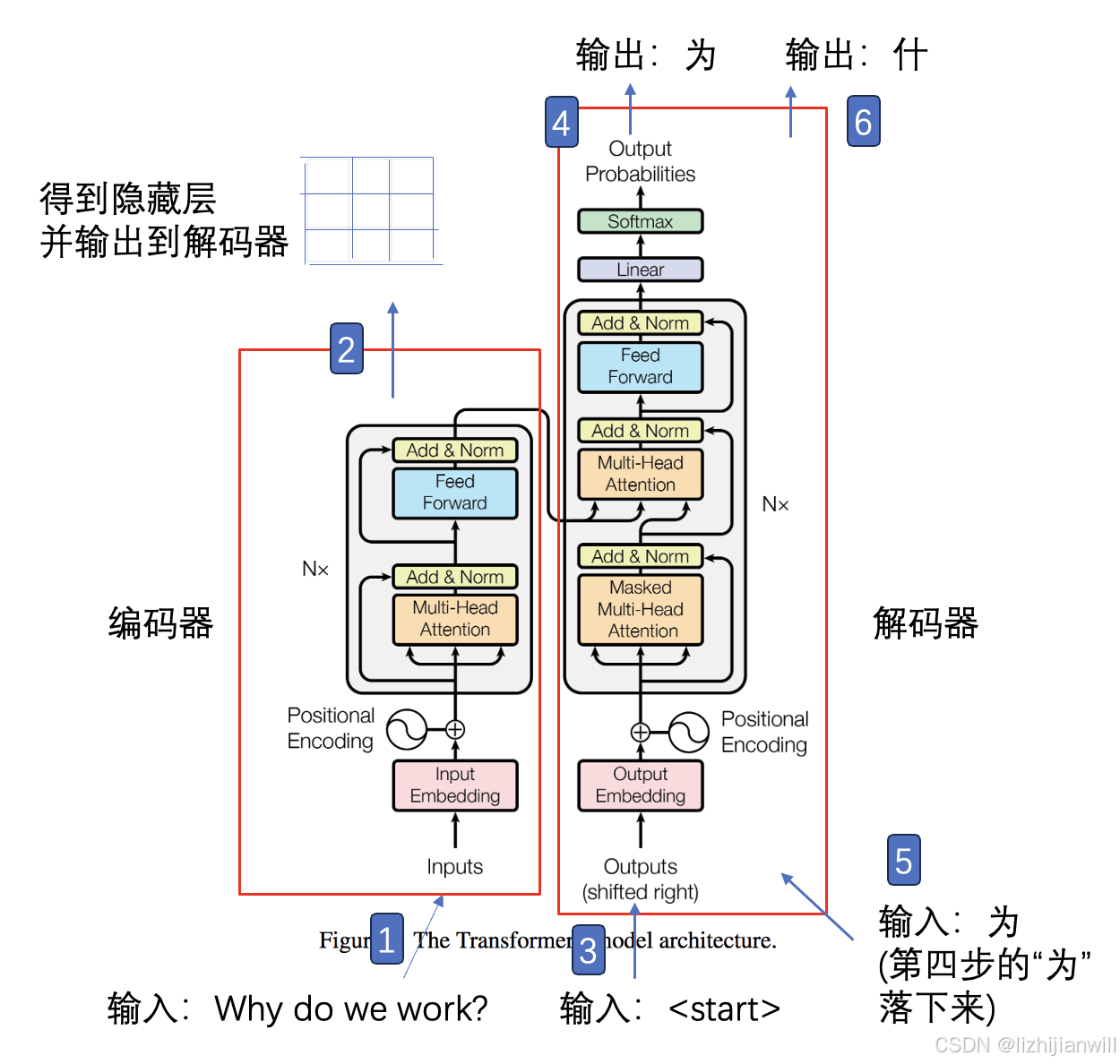
它们之间通过Attention机制连接起来。
3.2 Transformer 工作流程
以机器翻译为例:
1. 输入嵌入(Input Embedding): 将输入的句子转换成计算机能理解的向量表示。
2. 位置编码(Positional Encoding): 由于Transformer模型本身不包含位置信息,需要通过位置编码来告诉模型每个词在句子中的位置。
3. 编码器: 通过多层自注意力(Self-Attention)和前馈网络(Feed-Forward Network),对输入序列进行编码。
4. 解码器: 结合编码器的输出和已生成的部分输出序列,通过自注意力和编码器-解码器注意力(Encoder-Decoder Attention),生成下一个词。
5. 重复: 重复第4步,直到生成完整的输出序列。
3.3 小故事讲解
让我们用一个更简单的例子来理解:
假设你要把“I love you”翻译成中文。
1. 输入嵌入: 将“I”、“love”、“you”转换成向量。
2. 位置编码: 告诉模型“I”在第一个位置,“love”在第二个位置,“you”在第三个位置。
3. 编码器: 理解这句话的含义。
4. 解码器: 先生成“我”,然后结合“我”和编码器的输出,生成“爱”,最后生成“你”。
5. 完成: 得到翻译结果“我爱你”。
3.4 Transformer 的发展历程
从2017年Transformer的提出,到2018年ELMo、GPT-1、BERT等模型的出现,再到2020年GPT-3的惊艳亮相,Transformer的发展可谓日新月异。

3.5 Transformer的提出对seq2seq模型的影响:
摒弃了RNN结构、引入自注意力机制、位置编码、编码器-解码器架构的改进、训练效率的提升、在NLP领域的广泛应用、促进了预训练模型的发展。
3.6 迁移学习
Transformer模型在预训练后,可以在多种下游任务中进行微调(fine-tuning),而无需从头开始训练。这种迁移学习的方式大大减少了特定任务所需的数据量和训练时间,使得模型能够在资源有限的场景下也能取得良好的性能。
4. Transformer vs CNN vs RNN
| 特征 | Transformer | CNN | RNN |
| ------------ | ---------------------------- | ---------------------------- | ---------------------------- |
| 计算复杂度 | O(n^2 * d) | O(k * n * d^2) | O(n * d^2) |
| 并行性 | 高 | 高 | 低 |
| 最长学习距离 | O(1) | O(n/k) 或 O(logk(n)) | O(n) |
| 可解释性 | 较好(通过注意力分布) | 较差 | 较差 |
5. 输入嵌入(Input Embedding)
词嵌入(Word Embedding):nn.Embedding层权重矩阵的两种常见选择:(1)使用预训练(Pre-trained) 的Embeddings并固化 (2)对其进行随机初始化(当然也可以选择预训练的结果)并设为可训练的(Trainable)。
位置编码(Position Embedding)是Transformer模型中用来引入序列中词语位置信息的一种机制,因为Transformer本身不包含循环和卷积结构,无法直接捕捉序列顺序。
总结
大模型时代已经到来,掌握Attention机制和Transformer,就如同掌握了打开AI宝藏的钥匙。🔑
希望这篇文章能够帮助你更好地理解这些关键概念,并在未来的学习和工作中,充分利用大模型的强大能力,创造更多价值!
互动
你对大模型还有哪些疑问?🤔️ 你希望在哪些领域应用大模型?🚀 欢迎在评论区留言,一起交流!💬



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









