ElasticSearch 是基于Lucene 的,Lucene将数据存储在磁盘上,磁盘的IO就是 ElasticSearch 的瓶颈所在。 Elasticsearch 默认的数据存储路径是在 Elasticsearch 安装目录下的 data 子目录中。不过,这个路径是可以配置的,具体的默认路径可能因操作系统和安装方式的不同而有所差异。 对于不同的操作系统,Elasticsearch 的默认数据路径通常是:
Linux :/usr/share/elasticsearch/datamacOS :/usr/local/var/lib/elasticsearch/dataWindows :C:\ProgramData\Elasticsearch\data **配置数据存储路径:**可以在 elasticsearch.yml 配置文件中设置 path.data 属性。例如: path.data : /var/lib/elasticsearch/data
注意事项
Elasticsearch 允许你配置多个数据路径,以便于实现数据的冗余存储和负载均衡。这可以通过在 path.data 后面跟上多个路径实现,路径之间用逗号分隔。 确保 Elasticsearch 进程对该路径有读写权限。 建议不要将数据存储在系统盘上,以避免系统盘空间不足导致的问题。 使用 SSD,性能远高于机械磁盘。 使用 RAID 0,条带化 RAID 会提高磁盘 I/O,代价显然就是当一块硬盘故障时整个就故障了。不要使用镜像或者奇偶校验 RAID 因为副本已经提供了这个功能。 使用多块硬盘,并允许 Elasticsearch 通过多个 path.data 目录配置把数据条带化分配到它们上面。 不要使用远程挂载的存储,比如 NFS 或者 SMB/CIFS。这个引入的延迟对性能来说完全是背道而驰。 数据规模 :估算你存储的数据总量,并参考每个分片的最佳大小(通常在10GB到50GB之间)。这样可以确保分片既不会过大导致恢复时间过长,也不会过小导致资源开销增加。并发量和负载分布 :考虑查询的并发性,更多的分片可以分散查询负载。但是,分片数量过多会导致管理开销增加,每个搜索请求都会调度到索引的每个分片中,如果分片分散在不同的节点上问题不大,但如果分片开始竞争相同的硬件资源时,性能便会逐步下降。硬件资源 :每个节点上可以存储的分片数量与可用的堆内存大小成正比关系。一个经验法则是,确保对于节点上已配置的每个GB,将分片数量保持在20以下。例如,如果节点有30GB的堆内存,那么最多可以有600个分片。但是,从8.3版本开始,Elasticsearch减少了每个分片的堆使用量,因此这个经验法则也进行了更新,请根据实际情况调整。数据增长趋势 :考虑数据集的增长趋势,避免为未来可能的数据量做过多分配。如果你担心数据的快速增长,可以将分片最大容量限制为30GB,然后再对分片数量做合理估算。例如,如果你的数据能达到200GB,推荐最多分配7到8个分片。查询性能 :对于需要频繁更新或删除的数据,较小的分片(10GB-20GB)可能更合适,因为这样可以减少段合并的开销。对于静态数据或只增加不修改的数据,更大的分片(接近50GB)通常更有效。集群扩展性 :随着数据量的增加,可以通过增加分片数和机器数来扩展集群。Elasticsearch会自动迁移分片以重新平衡集群。索引和分片的资源开销 :每个索引和分片都会产生一定的资源开销。因此,合理规划分片数量和大小对于集群的性能至关重要。综上所述,合理设置分片数量需要根据具体的业务需求、数据增长预测、集群资源和性能目标来综合考虑。通常,一个平衡的做法是保持每个分片在10GB到50GB之间,并根据节点的堆内存大小来合理配置分片数量,同时考虑到高可用性和吞吐量的需求。 对于节点瞬时中断的问题,默认情况,集群会等待一分钟来查看节点是否会重新加入,如果这个节点在此期间重新加入,重新加入的节点会保持其现有的分片数据,不会触发新的分片分配。这样就可以减少 ES 在自动再平衡可用分片时所带来的极大开销。 通过修改参数 delayed_timeout,可以延长再均衡的时间,可以全局设置也可以在索引级别进行修改: PUT / _all/ _settings
{
"settings" : {
"index.unassigned.node_left.delayed_timeout" : "5m"
}
}
**自适应副本选择(Adaptive Replica Selection,ARS):**是一个用于提高搜索性能的功能,它允许副本分片参与搜索请求,而不需要主分片的参与。ARS在7.0版本中引入默认开启,用于减少跨节点搜索的网络开销。 启用自适应副本选择 :自适应副本选择默认是启用的,但如果需要确认或启用该功能,可以在elasticsearch.yml配置文件中设置以下参数,这个设置允许Elasticsearch在执行搜索时考虑远程副本分片。search.remote_cluster_aware : true
配置集群名称 :为了使用自适应副本选择,需要确保所有参与的Elasticsearch集群都配置了相同的cluster.name。这可以在elasticsearch.yml文件中设置:cluster.name : my- application
配置副本分配 :如果需要,可以配置副本分片的分配策略,以确保副本分片被分配到不同的节点或机架上,从而提高搜索的效率和可靠性。这个例子中,副本分片将被分配到具有rack_id为1或2的节点上。PUT / _cluster/ settings
{
"persistent" : {
"cluster.routing.allocation.replicas.include.rack_id" : "1,2"
}
}
**路由公式:**shard_num = hash(_routing) % num_primary_shards。 减少查询分片数 :通过指定routing参数,查询可以被限制在特定的分片上执行,而不是遍历所有的分片。这样可以减少查询的分片数量,从而提高查询效率。避免协调节点二次排序 :在没有指定routing的情况下,查询请求会分发到所有分片,然后协调节点需要对所有分片返回的结果进行排序和聚合,这会增加额外的性能开销。而指定routing后,可以直接在目标分片上完成搜索,避免了协调节点的二次排序。提高查询速度 :使用Routing信息查找的效率很高,因为可以直接定位到目标分片,避免了多余的查询,从而加快了查询速度。优化数据布局 :通过合理地使用Routing,可以控制数据的物理布局,将相关的文档路由到相同的分片上,这样可以减少跨分片查询的需要,提高查询性能。确保数据一致性 :自定义路由可以确保对具有相同路由值的文档的读取和写入操作都在同一个分片上执行,从而减少数据不一致的风险。提高查询效率 :在设计Elasticsearch Mapping时,合理利用Routing信息可以提升查询的效率。例如,可以将城市ID作为Routing的条件,让同一个城市的数据落在相同的分片中,这样查询时可以直接指定Routing,提高查询效率。索引文档时指定路由值 当索引一个新文档时,可以在请求中包含routing参数来指定路由值。
通过指定routing=user123,告诉Elasticsearch将文档路由到与user123哈希值对应的分片上。 如果以后需要检索或更新这个文档,也需要在请求中包含相同的路由值。 # 创建索引
PUT my_index_2
# 创建文档
PUT / my_index_2/ _doc/ 1 ? routing= user123
{
"user_id" : "user123" ,
"title" : "My first blog post"
}
# 返回
{
"_index" : "my_index_2" ,
"_type" : "_doc" ,
"_id" : "1" ,
"_version" : 1 ,
"result" : "created" ,
"_shards" : {
"total" : 2 ,
"successful" : 1 ,
"failed" : 0
} ,
"_seq_no" : 0 ,
"_primary_term" : 1
}
在执行查询时,也可以指定路由值来限制查询只在特定的分片上执行。
此搜索请求将仅在与“user1”和“user2”路由值关联的分片上执行。 GET my_index_2/ _search? routing= user1, user2
{
"query" : {
"match" : {
"title" : "document"
}
}
}
对于使用routing写入的文档,在进行GET、UPDATE或DELETE操作时如果不指定routing参数会出现异常。 Elasticsearch提供了一个索引mapping级别的设置_routing.required,来强制用户在INDEX、GET、DELETE、UPDATE一个文档时必须使用routing参数。 POST my_index_2/ _doc
{
"mappings" : {
"_routing" : {
"required" : true
}
}
}
**使用 Bulk API:**支持批量操作,提高写入效率。 **批量提交数据量:**默认不超过 100M,单次批处理数据大小从 5MB 到 15MB 逐渐增加,直到性能不再提升。 减少副本数量 :在大量写入过程中,减少副本数量可以提升写入性能,写入后再恢复原来的副本数量。修改现有索引的副本数量 :对于活动的索引库,副本数量可以随时修改。可以通过以下命令将副本数量设置为0PUT my_index/ _settings
{
"index" : {
"number_of_replicas" : 0
}
}
PUT / _all/ _settings
{
"index" : {
"number_of_replicas" : 0
}
}
设置索引模板 :如果希望之后创建的索引默认副本数量为0,可以设置一个索引模板。PUT / _template/ default_template
{
"index_patterns" : [ "*" ] ,
"settings" : {
"number_of_replicas" : 0
}
}
PUT my_index
{
"settings" : {
"index" : {
"number_of_replicas" : 0
}
}
}
index.translog.flush_threshold_period
这个参数控制了Flush时间间隔。默认值是 30 m,加大此参数可以减少数据写入磁盘的频率,从而减少磁盘I/O频率。 PUT / _cluster/ settings
{
"persistent" : {
"index.translog.flush_threshold_period" : "120m"
}
}
index.translog.flush_threshold_size
这个参数控制了Translog达到多大时会触发flush操作。默认值通常是512MB。增加这个值可以减少flush操作的频率,从而可能提高写入性能。 PUT / your_index/ _settings
{
"index.translog.flush_threshold_size" : "1gb"
}
index.translog.sync_interval
这个参数控制了Translog多久同步一次到磁盘。默认是 5 秒。增加这个值可以减少磁盘I/O,从而可能提高写入性能。 PUT / your_index/ _settings
{
"index.translog.sync_interval" : "30s"
}
**注意:**调整这些参数可能会影响数据的安全性和查询性能。 动态调整Refresh间隔
Elasticsearch默认的Refresh间隔是1秒,这意味着每秒索引会刷新一次,使得新的文档可以被搜索到。在数据导入阶段,可以增加这个间隔,例如设置为30秒,以减少Refresh操作对性能的影响。 PUT / my_index/ _settings
{
"index.refresh_interval" : "30s"
}
- 数据导入完成后,可以再将Refresh间隔调回原来的值,比如1秒:
PUT / my_index/ _settings
{
"index.refresh_interval" : "1s"
}
临时禁用Refresh :
在进行大量数据写入时,可以暂时禁用自动刷新,待批量索引完成后再启用。这可以通过将Refresh间隔设置为-1来实现,表示不自动刷新: PUT / my_index/ _settings
{
"index.refresh_interval" : "-1"
}
- 完成批量索引后,再重新启用Refresh:
PUT / my_index/ _settings
{
"index.refresh_interval" : "1s"
}
- **<font style="color:rgba(0, 0, 0, 0.9);">不超过物理内存的 50%:</font>**文件系统缓存用于处理I/O操作,建议至少将物理机一半的内存分配给文件系统缓存。例如,如果物理机内存为64GB,则至少分配32GB给文件系统缓存。
- **最大不超过32GB:**这是因为超过32GB后,JVM会启用压缩指针,导致性能下降。
- **初始堆内存和最大堆内存相同:**在`jvm.options`配置文件中设置Xms和Xmx参数,确保初始堆内存和最大堆内存相同,减少垃圾回收开销。
- **综上所述:**对于128GB内存的机器,建议配置两个Elasticsearch节点,每个节点的堆内存设置为31GB。
-Xms31g
-Xmx31g
确保操作系统不会将Elasticsearch进程swap出去,这会极大降低Elasticsearch的索引速度。可以通过执行sudo swapoff -a命令来禁用swap。 确保每个索引分片能获得至少512M的缓存,即indices.memory.index_buffer_size设置为512M。超过512M没有更多提升效果。 使用Elasticsearch提供的API监控内存使用情况,例如GET _cat/nodes?h=name,*heap*,*memory*,*Cache*&format=json和GET _cat/indices/*?h=*memory*&format=json。 Elasticsearch 应用时会使用各种缓存,而缓存是加快数据检索速度的王道。接下来,我们将着重介绍以下三种缓存:
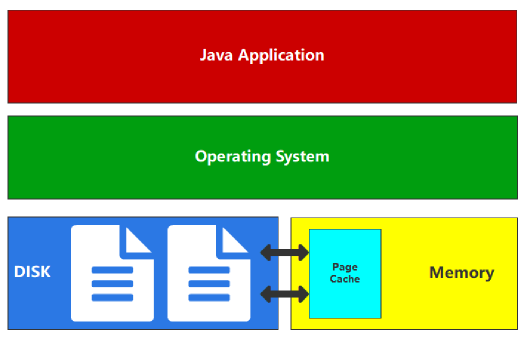
为了数据的安全、可靠,常规操作中,数据都是保存在磁盘文件中的。所以对数据的访问,绝大数情况下其实就是对文件的访问,为了提升对文件的读写的访问效率,Linux 内核会以页大小(4KB)为单位,将文件划分为多个数据块。当用户对文件中的某个数据块进行读写操作时,内核首先会申请一个内存页(称为 PageCache 页缓存)与文件中的数据块进行绑定。
页缓存的基本理念是从磁盘读取数据后将数据放入可用内存中,以便下次读取时从内存返回数据,而且获取数据不需要进行磁盘查找。所有这些对应用程序来说是完全透明的,应用程序发出相同的系统调用,但操作系统可以使用页缓存而不是从磁盘读取。 Java 程序是跨平台的,所以没有和硬件(磁盘,内存)直接交互的能力,如果想要和磁盘文件交互,那么必须要通过 OS 操作系统来完成文件的读写,我们一般就称之为用户态转换为内核态。而操作系统对文件进行读写时,实际上就是对文件的页缓存进行读写。所以对文件进行读写操作时,会分以下两种情况进行处理:
当从文件中读取数据时,如果要读取的数据所在的页缓存已经存在,那么就直接把页缓存的数据拷贝给用户即可。否则,内核首先会申请一个空闲的内存页(页缓存),然后从文件中读取数据到页缓存,并且把页缓存的数据拷贝给用户。 当向文件中写入数据时,如果要写入的数据所在的页缓存已经存在,那么直接把新数据写入到页缓存即可。否则,内核首先会申请一个空闲的内存页(页缓存),并且把新数据写入到页缓存中。对于被修改的页缓存,内核会定时把这些页缓存刷新到文件中。 页缓存对 Elasticsearch 来说意味着什么?与访问磁盘上的数据相比,通过页缓存可以更快地访问数据。这就是为什么建议的 Elasticsearch 内存通常不超过总可用内存的一半,这样另一半就可用于页缓存了。这也意味着不会浪费任何内存。 如果数据本身发生更改,页缓存会将数据标记为脏数据,并将这些数据从页缓存中释放。由于 Elasticsearch 和 Lucene 使用的段只写入一次,因此这种机制非常适合数据的存储方式。段在初始写入之后是只读的,因此数据的更改可能是合并或添加新数据。在这种情况下,需要进行新的磁盘访问。另一种可能是内存被填满了。在这种情况下,缓存数据过期的操作为 LRU。 对一个或多个索引发送搜索请求时,搜索请求首先会发送到 ES 集群中的某个节点,称之为协调节点;协调节点会把该搜索请求分发给其他节点并在相应分片上执行搜索操作,我们把分片上的执行结果称为“本地结果集”,之后,分片再将执行结果返回给协调节点;协调节点获得所有分片的本地结果集之后,合并成最终的结果并返回给客户端。Elasticsearch 会在每个分片上缓存了本地结果集,这使得频繁使用的搜索请求几乎立即返回结果。这里的缓存,称之为 Request Cache, 全称是 Shard Request Cache,即分片级请求缓存。 ES 能够保证在使用与不使用 Request Cache 情况下的搜索结果一致,那 ES 是如何保证的呢?这就要通过 Request Cache 的失效机制来了解啦。Request Cache 缓存失效是自动的,当索引 refresh 时就会失效,也就是说在默认情况下, Request Cache 是每 1 秒钟失效一次,但需要注意的是,只有在分片的数据实际上发生了变化时,刷新分片缓存才会失效。也就是说当一个文档被索引 到 该文档变成 Searchable 的这段时间内,不管是否有请求命中缓存该文档都不会被返回。 所以我们可以通过 index.refresh_interval 参数来设置 refresh 的刷新时间间隔,刷新间隔越长,缓存的数据越多,当缓存不够的时候,将使用 LRU 最近最少使用策略删除数据。 当然,我们也可以手动设置参数 indices.request.cache.expire 指定失效时间(单位为分钟),但是基本上我们没必要去这样做,因为缓存在每次索引 refresh 时都会自动失效。 Request Cache 的使用
默认情况下,Request Cache 是关闭的,我们可以在创建新的索引时启用。 curl - XPUT 服务器 IP : 端口/ 索引名 - d
'{
"settings" : {
"index.requests.cache.enable" : true
}
} '
- 也可以通过动态参数配置来进行设置:
curl - XPUT 服务器 IP : 端口/ 索引名/ _settings - d '{
"index.requests.cache.enable" : true
} '
- 开启缓存后,需要在搜索请求中加上 request_cache=true 参数,才能使查询请求被缓存
curl - XGET '服务器 IP:端口/索引名/_search?request_cache=true&pretty' - H 'Content-Type: application/json' - d
'{
"size" : 0 ,
"aggs" : {
"popular_colors" : {
"terms" : {
"field" : "colors"
}
}
}
} '
- 两个注意事项:
* 第一:参数 size:0 必须强制指定才能被缓存,否则请求是不会缓存的,即使手动的设置 request_cache=true
* 第二:在使用 script 脚本执行查询时,由于脚本的执行结果是不确定的(比如使用random 函数或使用了当前时间作为参数),一定要指定 request_cache=false 禁用 Request Cache 缓存。
Request Cache 的设置
Request Cache 作用域为 Node,在 Node 中的 Shard 共享这个 Cache 空间。默认最大大小为 JVM 堆内存的 1%。可以使用以下命令在 config/elasticsearch.yml 文件中进行更改: indices.requests.cache.size : 1%
- Request Cache 是以查询的整个 DSL 语句做为 key 的,所以如果要命中缓存,那么查询生成的 DSL 一定要一样,即使修改了一个字符或者条件顺序,都不能利用缓存,需要重新生成 Cache。
这种缓存的工作方式也与其他缓存有着很大的不同。页缓存方式缓存的数据与实际从查询中读取的数据量无关。当使用类似查询时,分片级请求缓存会缓存数据。查询缓存更精细些,可以缓存在不同查询之间重复使用的数据。 Elasticsearch 具有 IndicesQueryCache 类。这个类与 IndicesService 的生命周期绑定在一起,这意味着它不是按索引,而是按节点的特性 — 这样做是有道理的,因为缓存本身使用了 Java 堆。这个索引查询缓存占用以下两个配置选项。 indices.queries.cache.count:缓存条目总数,默认为 10, 000
indices.queries.cache.size:用于此缓存的 Java 堆的百分比,默认为 10%
查询缓存已进入下一个粒度级别,可以跨查询重用!凭借其内置的启发式算法,它只缓存多次使用的筛选器,还根据筛选器决定是否值得缓存,或者现有的查询方法是否足够快,以避免浪费任何堆内存。这些位集的生命周期与段的生命周期绑定在一起,以防止返回过时的数据。一旦使用了新段,就需要创建新的位集。



























 5890
5890

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











