






 本文介绍了一个基于Hadoop MapReduce的大数据处理程序,用于统计网站独立访客数(UV)。通过解析日志文件,该程序实现了从原始日志数据中提取城市ID和用户标识符,并利用MapReduce框架对数据进行聚合,最终输出各个城市的UV计数。
本文介绍了一个基于Hadoop MapReduce的大数据处理程序,用于统计网站独立访客数(UV)。通过解析日志文件,该程序实现了从原始日志数据中提取城市ID和用户标识符,并利用MapReduce框架对数据进行聚合,最终输出各个城市的UV计数。
大数据MapReduce 模板编写UV程序
* 1. 几个网站基本指标*
(1)PV(Page View):页面点击(浏览)量
(2)UV(Unique Vistor):独立访客数
(3)VV(Visit View):访客数,记录所有访客访问次数,打开网站到关闭网站为一次访问,同一访客多次访问会被记录多次。
(4)IP(IP数):使用不同IP地址的用户访问网站的数量,同一IP无论访问了几个页面,独立IP数均为1。
2. MapReduce执行过程
-》input:默认从hdfs读取数据:TextInputFormat -》mapper
-》输入:input的输出
-》map:方法,一行调用一次map方法
-》设计输出,构造输出的keyvalue
-》对每一行内容进行分割
-》输出
-》shuffle:分区,分组,排序
-》reduce:每一条keyvalue调用一次reduce方法
-》output
输出:默认将reduce的输出写入hdfs统计每个城市的UV数
思路:
map
key:城市id Text
value:guid Text
shuffle
key:城市id
value:{uuid1,uuid1,uuid3……}
reduce
key:城市id
value:不同uuid的个数(uv)
output
key:城市id
value:uv数
代码实现如下:
package com.huadian.bigdata.hadoop.mapreduce;
import java.io.IOException;
import java.util.HashSet;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class WebLogUvMr extends Configured implements Tool {
public static class WebLogUVMapper extends Mapper<LongWritable, Text, Text, Text>{
private Text outputKey = new Text();
private Text outputValue = new Text();
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
//分割每一行的内容
String line = value.toString();
String[] items = line.split("\t");
if (36<=items.length) {
if (StringUtils.isBlank(items[5])) {
return;
}
this.outputKey.set(items[23]);
this.outputValue.set(items[5]);
context.write(outputKey, outputValue);
}else{
return;
}
}
}
public static class WebLogUVReduce extends Reducer<Text, Text, Text, IntWritable>{
@Override
protected void reduce(Text key, Iterable<Text> values,Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
HashSet<String> a = new HashSet<>();
for(Text value:values){
a.add(value.toString());
}
context.write(key, new IntWritable(a.size()));
}
}
@Override
public int run(String[] arg0) throws Exception {
// TODO Auto-generated method stub
//job
Job job = Job.getInstance(this.getConf(),"uvtest");
job.setJarByClass(WebLogUvMr.class);
//input
FileInputFormat.setInputPaths(job, new Path(arg0[0]));
//map
job.setMapperClass(WebLogUVMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//reducer
job.setReducerClass(WebLogUVReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setNumReduceTasks(2);
//output
FileOutputFormat.setOutputPath(job, new Path(arg0[1]));
return job.waitForCompletion(true)?0:1;
}
public static void main(String[] args){
Configuration conf = new Configuration();
try {
int status = ToolRunner.run(conf, new WebLogUvMr(),args);
System.exit(status);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
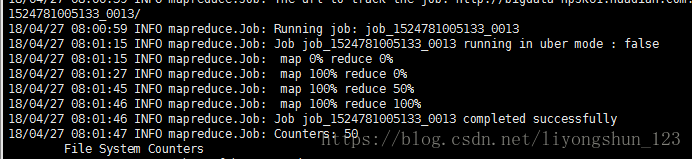
执行jar,进行数据分析
bin/yarn jar uv.jar com.huadian.bigdata.hadoop.mapreduce.WebLogUvMr /user/huadian/mapreduce/wordcount/input
/2015082818 /user/huadian/mapreduce/wordcount/output211
“`
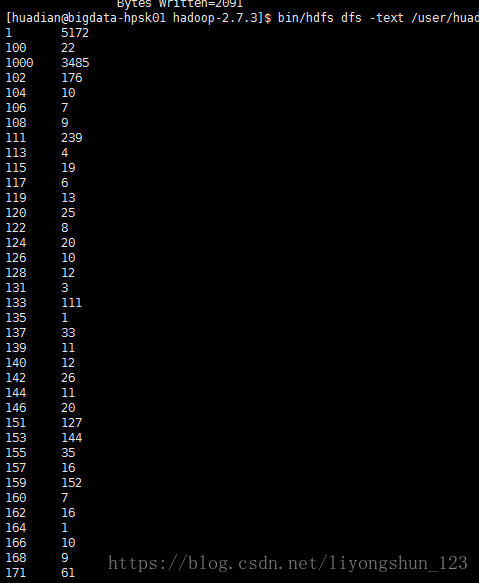
运行结果:

















 728
728

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









