







 该博客围绕Hadoop中YARN展开,主要介绍其整体架构以及生命周期相关内容,属于大数据开发领域,对了解YARN在Hadoop中的运行机制有重要意义。
该博客围绕Hadoop中YARN展开,主要介绍其整体架构以及生命周期相关内容,属于大数据开发领域,对了解YARN在Hadoop中的运行机制有重要意义。
http://www.aboutyun.com/thread-6756-1-1.html
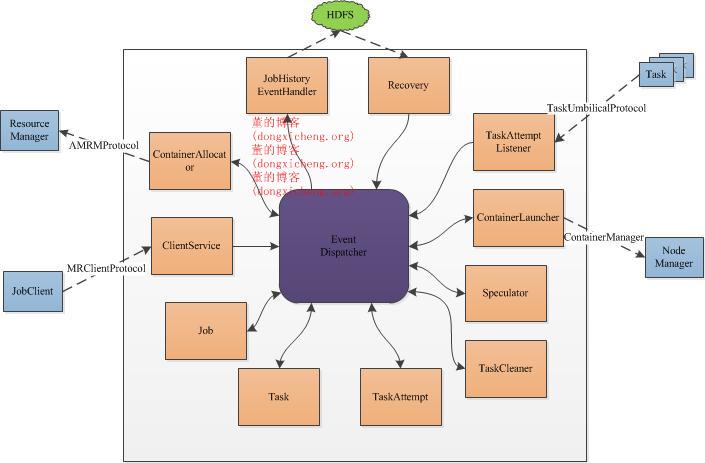
| 本帖最后由 howtodown 于 2014-1-31 16:00 编辑 整体架构 MRAppMaster是MapReduce的ApplicationMaster实现,它使得MapReduce计算框架可以运行于YARN之上。在YARN中,MRAppMaster负责管理MapReduce作业的生命周期,包括创建MapReduce作业,向ResourceManager申请资源,与NodeManage通信要求其启动Container,监控作业的运行状态,当任务失败时重新启动任务等。
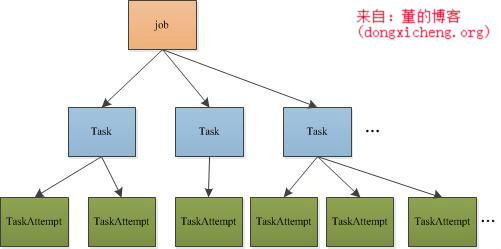
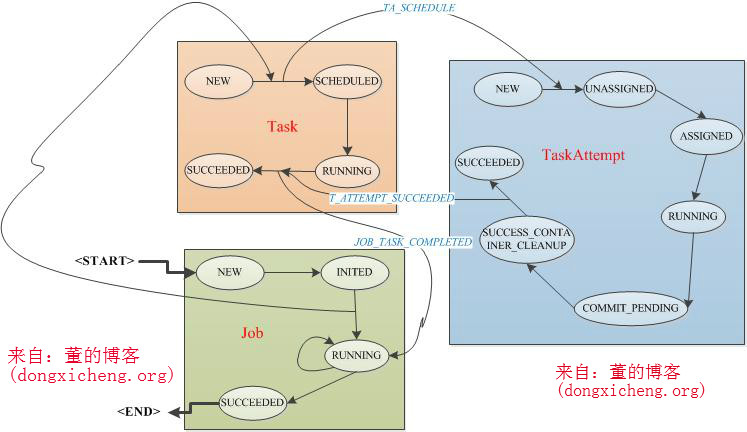
YARN使用了基于事件驱动的异步编程模型,它通过事件将各个组件联系起来,并由一个中央事件调度器统一将各种事件分配给对应的事件处理器。在YARN中,每种组件是一种事件处理器,当MRAppMaster启动时,它们会以服务的形式注册到MRAppMaster的中央事件调度器上,并告诉调度器它们处理的事件类型,这样,当出现某一种事件时,MRAppMaster会查询<事件,事件处理器>表,并将该事件分配给对应的事件处理器。 接下来,我们分别介绍MRAppMaster各种组件/服务的功能。 ContainerAllocator与ResourceManager通信,为作业申请资源。作业的每个任务资源需求可描述为四元组<Priority, hostname,capability,containers>,分别表示作业优先级、期望资源所在的host,资源量(当前仅支持内存),container数目。ContainerAllocator周期性通过RPC与ResourceManager通信,而ResourceManager会为之返回已经分配的container列表,完成的container列表等信息。 ClientServiceClientService是一个接口,由MRClientService实现。MRClientService实现了MRClientProtocol协议,客户端可通过该协议获取作业的执行状态(而不必通过ResourceManager)和制作业(比如杀死作业等)。 Job表示一个MapReduce作业,与MRv1的JobInProgress功能一样,负责监控作业的运行状态。它维护了一个作业状态机,以实现异步控制各种作业操作。 Task表示一个MapReduce作业中的某个任务,与MRv1中的TaskInProgress功能类似,负责监控一个任务的运行状态。它为花了一个任务状态机,以实现异步控制各种任务操作。 TaskAttempt表示一个任务运行实例,同MRv1中的概念一样。 TaskCleaner清理失败任务或者被杀死任务产生的结果,它维护了一个线程池,异步删除这些任务产生的结果。 Speculator完成推测执行功能。当一个任务运行速度明显慢于其他任务时,Speculator会为该任务启动一个备份任务,让其同慢任务一同处理同一份数据,谁先计算完成则将谁的结果作为最终结果,另一个任务将被杀掉。该机制可有效防止“拖后腿”任务拖慢整个作业的执行进度。 ContainerLauncher与NodeManager通信,要求其启动一个Container。当ResourceManager为作业分配资源后,ContainerLauncher会将资源信息封装成container,包括任务运行所需资源、任务运行命令、任务运行环境、任务依赖的外部文件等,然后与对应的节点通信,要求其启动container。 TaskAttemptListener管理各个任务的心跳信息,如果一个任务一段时间内未汇报心跳,则认为它死掉了,会将其从系统中移除。同MRv1中的TaskTracker类似,它实现了TaskUmbilicalProtocol协议,任务会通过该协议汇报心跳,并询问是否能够提交最终结果。 JobHistoryEventHandler对作业的各个事件记录日志,比如作业创建、作业开始运行、一个任务开始运行等,这些日志会被写到HDFS的某个目录下,这对于作业恢复非常有用。当MRAppMaster出现故障时,YARN会将其重新调度到另外一个节点上,为了避免重新计算,MRAppMaster首先会从HDFS上读取上次运行产生的运行日志,以恢复已经运行完成的任务,进而能够只运行尚未运行完成的任务。 Recovery当一个MRAppMaster故障后,它将被调度到另外一个节点上重新运行,为了避免重新计算,MRAppMaster首先会从HDFS上读取上次运行产生的运行日志,并恢复作业运行状态。 -------------------------------------------------------------------------------------------------------------------------------------------------------------------- 作业生命周期 在正式讲解作业生命周期之前,先要了解MRAppMaster中作业表示方式,每个作业由若干干Map Task和Reduce Task组成,每个Task进一步由若干个TaskAttempt组成,Job、Task和TaskAttempt的生命周期均由一个状态机表示,具体可参考https://issues.apache.org/jira/browse/MAPREDUCE-279(附件中的图yarn-state-machine.job.png,yarn-state-machine.task.png和yarn-state-machine.task-attempt.png)
作业的创建入口在MRAppMaster类中,如下所示:
(1)作业/任务初始化 JobImpl会接收到.JOB_INIT事件,然后触发作业状态从NEW变为INITED,并触发函数InitTransition(),该函数会创建MapTask和 ReduceTask,代码如下:
这之后,所有Map Task和Reduce Task各自负责各自的状态变化,ContainerAllocator模块会首先为Map Task申请资源,然后是Reduce Task,一旦一个Task获取到了资源,则会创建一个运行实例TaskAttempt,如果该实例运行成功,则Task运行成功,否则,Task还会启动下一个运行实例TaskAttempt,直到一个TaskAttempt运行成功或者达到尝试次数上限。当所有Task运行成功后,Job运行成功。一个运行成功的任务所经历的状态变化如下(不包含失败或者被杀死情况):
【总结】 本文分析只是起到抛砖引入的作用,读者如果感兴趣,可以自行更深入的研究以下内容: (1)Job、Task和TaskAttempt状态机设计(分别在JobImpl、TaskImpl和TaskAttemptImpl中) (2)在以下几种场景下,以上三个状态机的涉及到的变化: 1) kill job 2) kill task attempt 3) fail task attempt 4) container failed 5) lose node |

















 850
850

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









