







 提出了一种新的深度残差学习框架,解决了随着网络深度增加而出现的退化问题,通过残差学习和快捷恒等映射,成功构建了152层的深度残差网络,在ILSVRC2015分类任务中取得优异成绩。
提出了一种新的深度残差学习框架,解决了随着网络深度增加而出现的退化问题,通过残差学习和快捷恒等映射,成功构建了152层的深度残差网络,在ILSVRC2015分类任务中取得优异成绩。
ResNet
摘要
本文提出的残差网络有152层,该网络结构以3.57% 错误率赢得了ILSVRC 2015 分类任务的第一名。
1.介绍
随着深度的增加,梯度消失和梯度爆炸问题就出现了,但这些问题可以通过标准初始化和中间标准化层解决大部分。
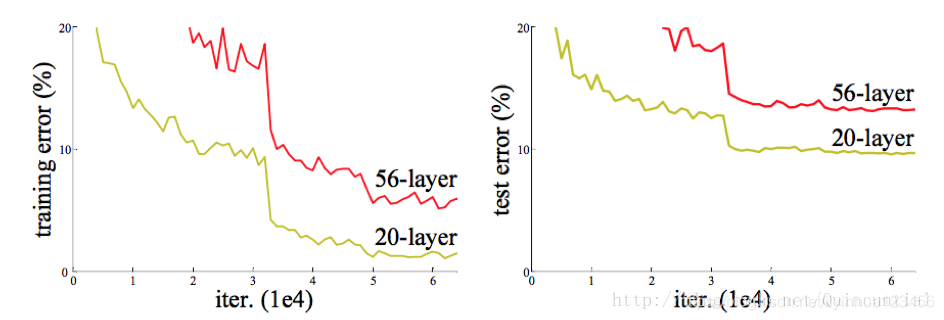
当更深的网络开始收敛时,就暴露出了一个问题:随着网络深度的增加,准确率开始饱和,然后急剧下降。意外的是,这种下降不是由过拟合引起的,并且在适当的深度模型上添加更多的层会导致更高的训练误差,如上图所示,随着网络深度增加,训练错误率和测试错误率都在下降。
准确率的退化表明并不是所有的系统都那么容易优化,本文提出了一个方法可以解决这个问题:通过构建得到更深层模型的解决方案,添加的层是浅层的映射,其他层是从学习到的较浅模型的拷贝。 采用此种方案后结果显示,较深的模型不应该产生比其对应的较浅模型更高的训练误差。
在本篇论文中,为解决退化问题,我们提出了一个新的深度残差学习框架,如下图,令H(x)=F(x)+x
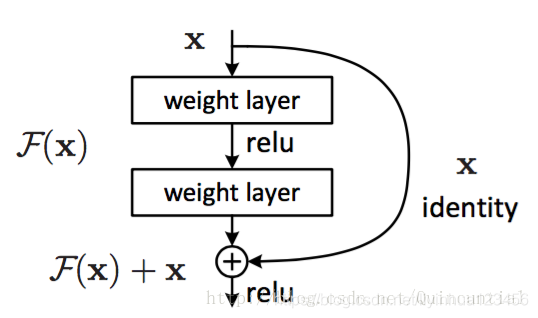
公式F(x)+x可以通过快捷连接实现,快捷连接意思是跳过一层或者多层的连接。在我们的例子中,快捷连接仅仅实现了恒等映射,然后把恒等映射结果加到堆叠层的结果中,如上图所示。恒等快捷连接不添加额外的参数和计算量,整个网络仍然可以由带有反向传播的SGD进行端到端的训练。
我们在ImageNet上实验表明:
1)我们的深度残差网络更容易优化,但是当深度增加时,对应的简单网络(简单堆叠层)即(plain nets)显示出更大的错误率,
2)我们的深度残差网络在深度增加时,更容易获得正确率的提升。
我们的152层深度残差网络远比VGG简单,并且在ImageNet测试集上有3.57%的top-5错误率。赢得了ILSVRC2015分类比赛的第一名,随后在ILSVRC & COCO 2015竞赛中的又赢得了ImageNet检测,定位,COCO检测,COCO分割的第一名。
2.相关工作
文中提到一些网络把中间层直接连接到辅助分类器上,用于解决梯度消失和梯度爆炸问题,这也属于快捷连接。
3.深度残差学习
3.1残差学习
3.2快捷恒等映射
每隔几个堆叠层,我们就是用一个残差学习,残差块如上图所示,我们把残差块定义为:
y=F(x,Wi)+x (1)
x为输入,y为输出,以上图的两层为例,函数F(x,Wi) 表示要学习的残差映射,F = W2σ(W1x), σ是relu激活函数,
然后使用F+x,再最后在进行一次relu。
该等式表示的快捷连接既没有引入额外的参数也没有增加计算复杂度。所以它不仅仅具有实践意义,而且在与plain netwoks比较中也有重要的意义。我们可以公平地比较同时具有相同数量的参数,相同深度,宽度和计算成本的简单/残差网络(除了不可忽略的元素加法之外)。
但是在等式(1)中x和F必须有相同的维度。如果不是这样(当改变输入或输出的维度),我们可以通过快捷连接执行线性投影Ws 来匹配维度: y=F(x,Wi)+Ws x. (2)
实验表明,恒等映射足以解决退化问题,因此Ws仅仅用来匹配维度。
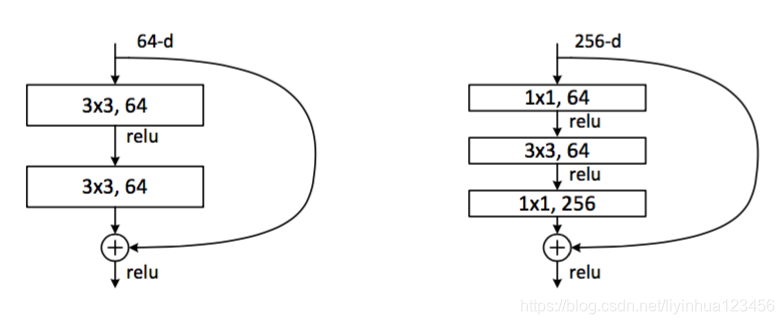
残差函数F是可变的,在本文的实验中包括两层或者三层的函数F,如下图,但是更多层也是可能的。如果只有一层的话,等式(1)就变成一个线性层,F=W1x+x,我们没有看到其中的优势。
3.3网络结构
我们简单(plain)的网络主要参照VGG(如下中间)。卷积层大多采用3*3卷积核,并且遵循两个原则:
(1):对于相同的特征图的输出,层有相同数量的滤波器
(2):如果特征图大小减半,则滤波器的数量加倍来保持时间复杂度相同。
通过步长为2的卷积层直接执行下采样(缩小图片)。网络以全局平均池化层和具有softmax的1000维全连接层结束
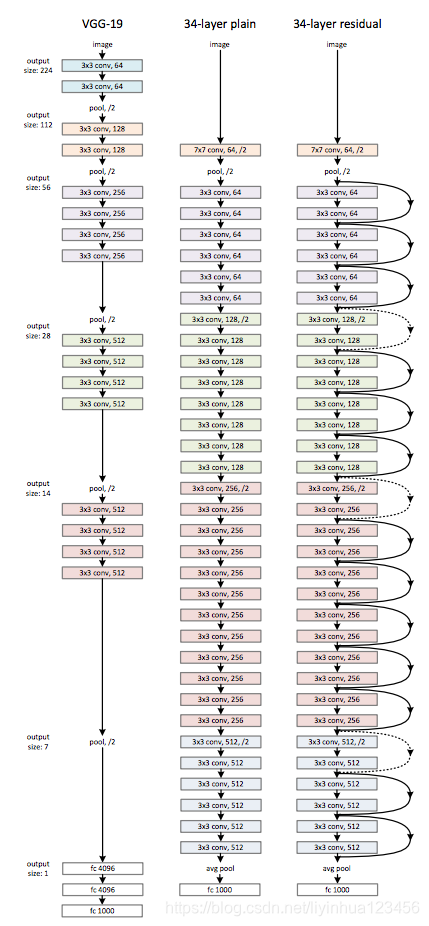
基于中间的plain网络,我们插入了快捷连接,则变成了右边的残差版本。当输入和输出维度相同时,我们使用恒等快捷连接,如上图3右边图中的实线表示,当维度增加时,可以使用两种方法:(1)仍然使用恒等映射,额外填充0来增加维度。这种方法没有多余的参数增加。(2)等式(2)的投影快捷连接用于匹配维度(用1*1卷积来完成)。对于这两个选项,当快捷连接跨越两种尺寸的特征图时,它们执行时步长为2。
3.4补充
调整图片大小,使短的边在[256,480]间随机取样,224×224裁剪是从图像或其水平翻转中随机采样,并逐像素减去均值。
在卷积之后,激活之前使用批量归一化。。我们使用批大小为256的SGD方法。学习速度从0.1开始,当误差稳定时学习率除以10。我们使用的权重衰减为0.0001,动量为0.9 。我们不使用dropout.
在测试阶段,我们采用标准的10-crop测试,对于最好的结果,我们采用全连接形式,并在多尺度上对分数进行平均(图像归一化,短边位于{224, 256, 384, 480, 640}中)。
4.实验
4.1ImageNet分类实验
我们在ImageNet2012分类数据集上评估,该数据集有1000个类别,该模型在128万训练图片上训练,在5万丈验证图片上评估。并在10万张图片上测试,我们评估了top-1,top-5错误率。
plain 网络:我们首先评估了18层和34层plain网络,18层的plain网络与34层的网络结构类似,如下图:
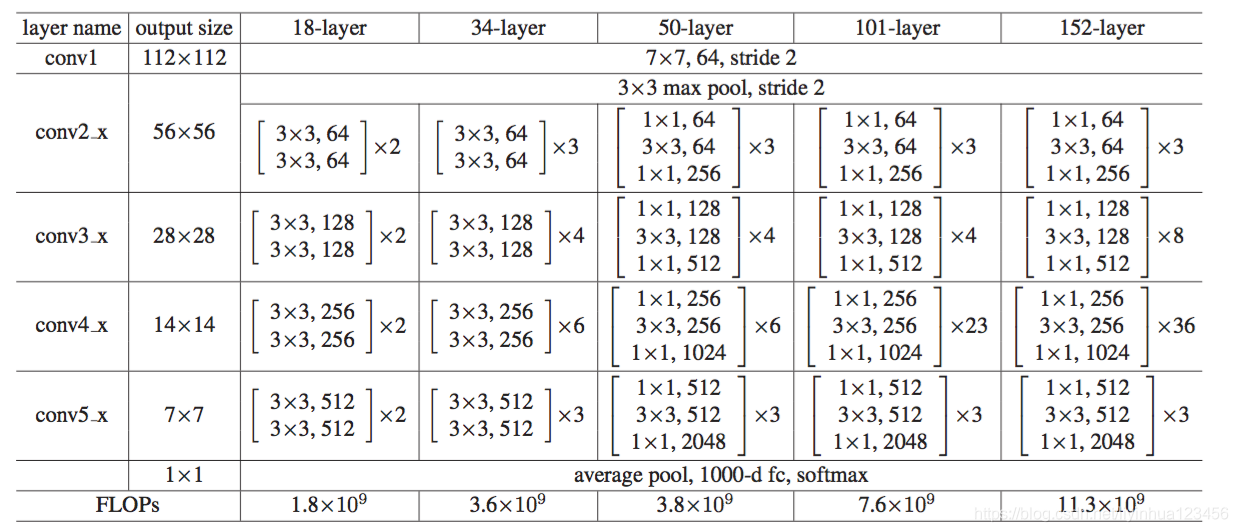
下图是训练误差图:较深的34层简单网络比较浅的18层简单网络有更高的验证误差。
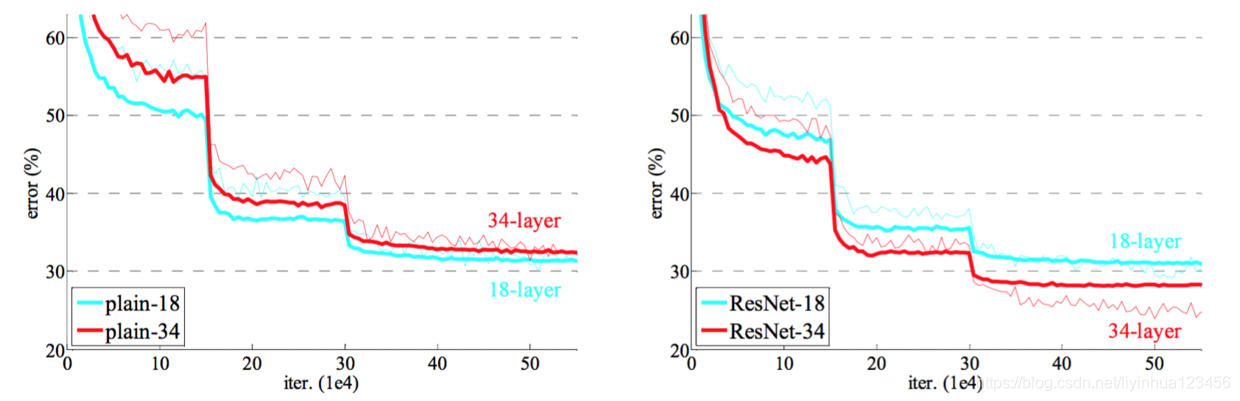
下图为:ImageNet验证集上的Top-1错误率(%,10个裁剪图像测试)。对于resNet我们没有引入额外的参数,对于维度不匹配问
题,采用了0填充。 这种比较证实了在极深系统中残差学习的有效性。
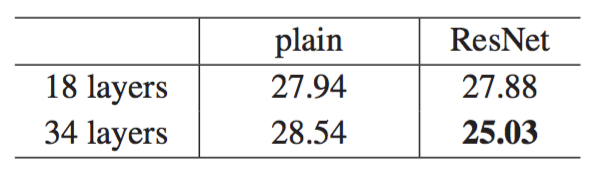
恒等和投影快捷连接:实验已经证明恒等快捷连接确实对训练有帮助,之后我们调查了投影快捷连接(等式2), 在下表中我们比较了三个选项:A:零填充快捷连接来增加维度,没有参数的增加。B:投影快捷连接来增加维度,其他连接是恒等的。C:所有的连接都是投影快捷连接。对于ResNet50/101/152层仅使用了选择B
由上表比较可知,ResNet确实比相对应的plain好。B比A略好,我们认为这是因为A中的零填充确实没有残差学习。C比B略好,我们把它归功于C全部使用的投影连接引入的参数学习。但A,B,C带来的错误率仅仅只有很小的差别,所以我们认为投影快捷连接对于解决退化问题不是至关重要的。所以在本文的剩下阶段我们不再采用选项C,以减少内存/时间复杂性和模型大小。恒等快捷连接对于不增加下面介绍的瓶颈结构的复杂性尤为重要。
更深的瓶颈结构:接下来我们介绍在ImageNet上使用的更深层的网络结构,鉴于时间的考虑,我们把之前的构建块改为瓶颈设 计:对于每一个残差函数F,我们使用3个堆叠层代替两个,如下图:

这三层包括1*1,3*3,1*1卷积,其中1*1卷积用于减少和增加维度,使得3×3层成为具有较小输入/输出维度的瓶颈。
无参数的恒等快捷对于瓶颈结构尤为重要,如果上图中的恒等连接被投影连接代替,由于快捷连接是连接到两个高维端,可以看出时间复杂度和模型尺寸会加倍。所以恒等快捷连接对瓶颈设计更有效
50层ResNet:我们用3层瓶颈块替换34层网络中的每一个2层块,得到了一个50层ResNet 。我们使用选项B来增加维度
101层ResNet和152层ResNet:通过使用更多的3层瓶颈块构建101层和152层ResNet,尽管你层数大大增加,152层的ResNet的复杂度始终远远低于VGG.50/101/152层的ResNet比34层更加的准确。我们没有观察到退化问题。
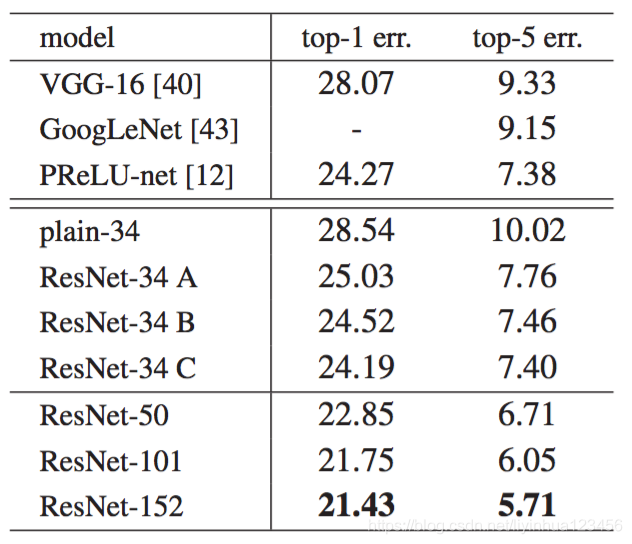
与最先进的方法比较:在下表中我们与以前最好的单一模型进行比较,我们的152层单个模型取得了top-5验证集4.49%的错误率。
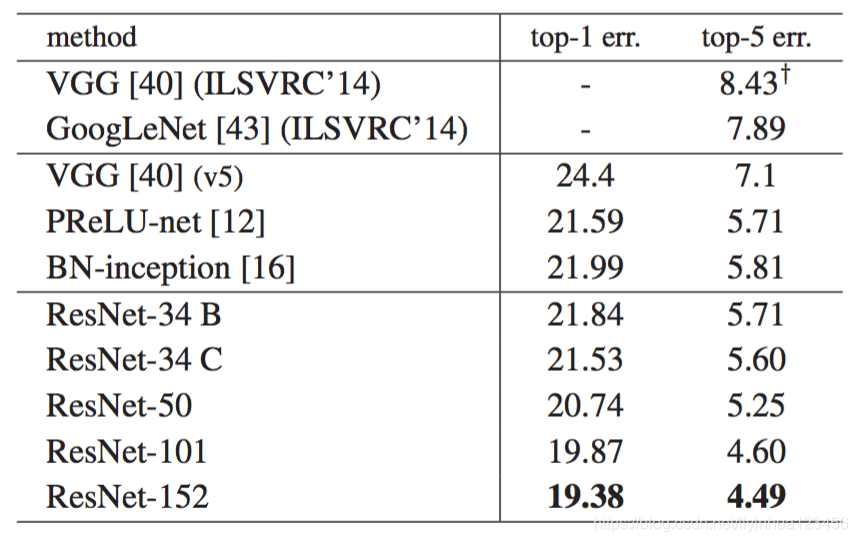
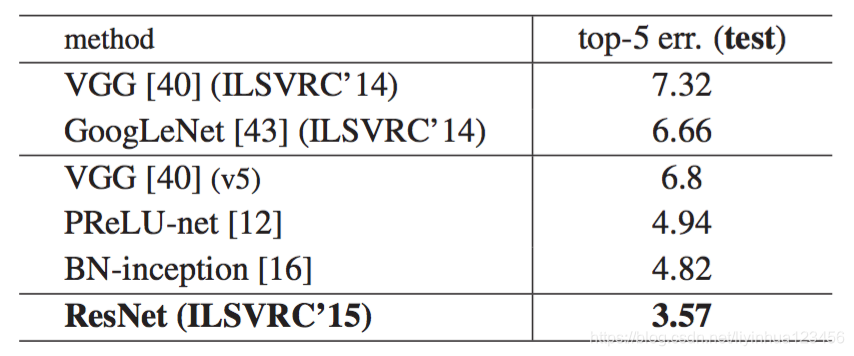
我们结合了六种不同深度的模型,形成一个集合(在提交时仅有两个152层)。这在测试集上得到了3.5%的top-5错误率。这次提交在2015年ILSVRC中荣获了第一名。
4.2. CIFAR-10和分析

















 572
572

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









