




MySQL45讲
1. 一条SQL查询语句怎么运行的
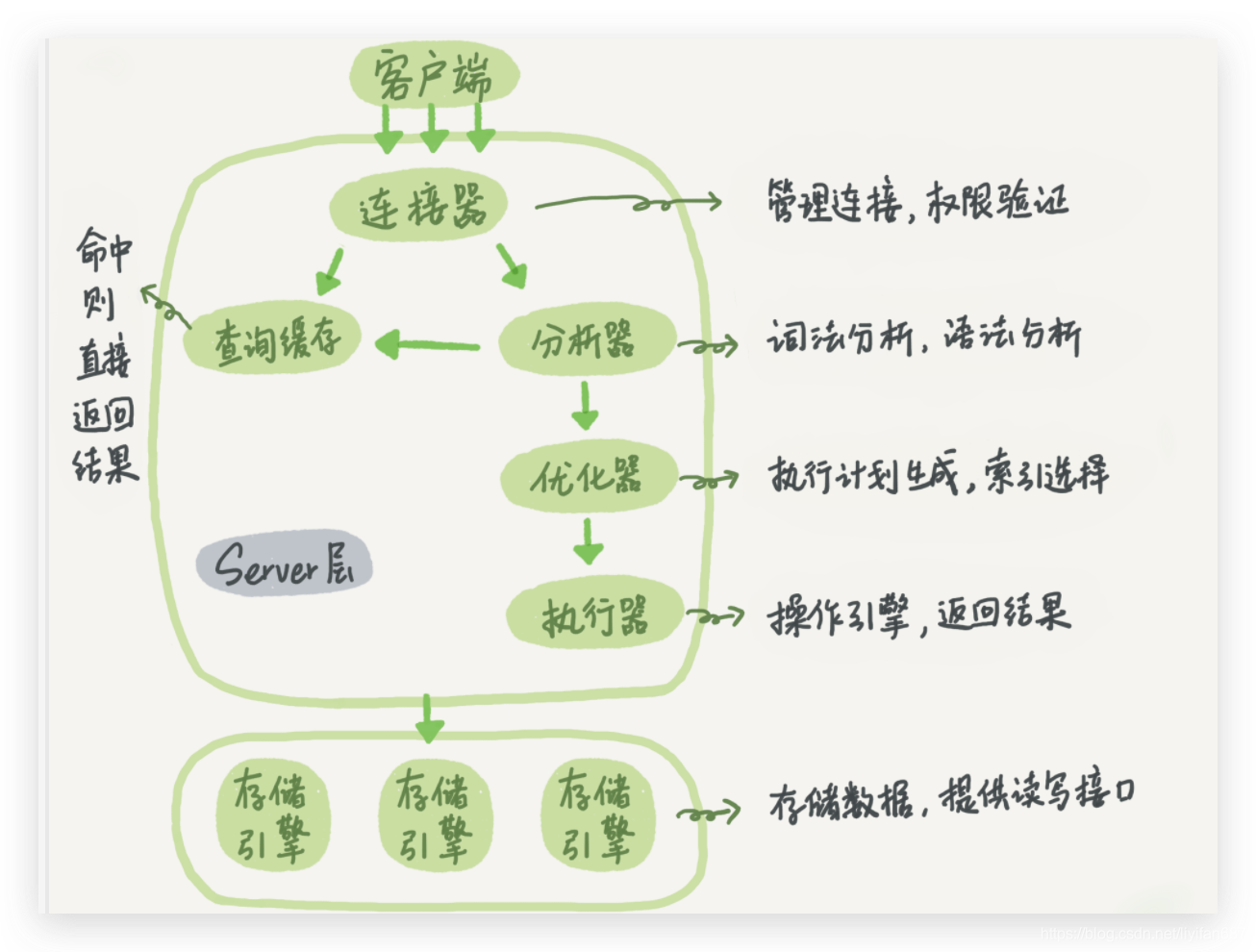
但是大多数情况下我会建议你不要使用查询缓存,为什么呢?因为查询缓存往往弊大于利。
- 查询缓存的失效非常频繁,只要有对一个表的更新,这个表上所有的查询缓存都会被清空。
2. 一条SQL更新语句怎么运行
MySQL 里经常说到的 WAL 技术,WAL 的全称是 Write-Ahead Logging,它的关键点就是先写日志,再写磁盘,也就是先写粉板,等不忙的时候再写账本。
redo log(粉板)
当有一条记录需要更新的时候,InnoDB 引擎就会先把记录写到 redo log(里面,并更新内存,这个时候更新就算完成了。在适当的时候,将这个操作记录更新到磁盘里面,而这个更新往往是在系统比较空闲的时候做,这就像打烊以后掌柜做的事。
- 大小固定,循环写
- crash-safe
binlog
- redo log 是innoDB引擎特有的,server 层的叫 binlog(归档日志)
- redolog 是物理日志,记录“在某个数据页上做了什么修改”;binlog 是逻辑日志,是语句的原始逻辑,比如“给 ID=2 这一行的 c 字段加 1 ”
- redolog循环写,binlog追加
对于语句 update T set c=c+1 where ID=2;
- 执行器先找引擎取 ID=2 这一行。ID 是主键,直接用树搜索找到。如果 ID=2 这一行所在数据页就在内存中,就直接返回给执行器;否则,需要先从磁盘读入内存,再返回。
- 执行器拿到引擎给的行数据,把这个值加上 1,N+1,得到新的一行数据,再调用引擎接口写入这行新数据。
- 引擎将这行新数据更新到内存中,同时将这个更新操作记录到 redo log 里面,此时 redo log 处于 prepare 状态。然后告知执行器执行完成了,随时可以提交事务。
- 执行器生成这个操作的 binlog,并把 binlog 写入磁盘。
- 执行器调用引擎的提交事务接口,引擎把刚刚写入的 redo log 改成提交(commit)状态,更新完成
对于redo log 是有两阶段的:commit 和 prepare
如果不使用“两阶段提交”,数据库的状态就有可能和用它的日志恢复出来的库的状态不一致.
- 先r后b:binlog丢失,少了一次更新,恢复后仍是0。
- 先b后r:多了一次事务,恢复后是1.
undolog
Undo log的存在保证了事务的原子性,MVCC就是依赖它来实现,当对任何行做了修改的时候都会在undo log里面记录,大量的undo log构成行的历史版本记录,在需要的时候可以回退(rollback)到任何版本;
3.事务隔离
ACID(Atomicity、Consistency、Isolation、Durability,即原子性、一致性、隔离性、持久性)
SQL标准隔离级别:
- 读未提交: 一个事务还没提交时,它做的变更就能被别的事务看到。
- 读提交: 一个事务提交之后,它做的变更才会被其他事务看到。
- 可重复读: 一个事务执行过程中看到的数据,总是跟这个事务在启动时看到的数据是一致的。当然在可重复读隔离级别下,未提交变更对其他事务也是不可见的。
- 串行化: 顾名思义是对于同一行记录,“写”会加“写锁”,“读”会加“读锁”。当出现读写锁冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行
避免使用长事务,set autocommit=1, 通过显式语句的方式来启动事务。
information_schema 库的 innodb_trx 中可以查询长事务。
4-5. 索引
基于B+树。
- 主键索引的叶子节点存的是整行数据。 InnoDB 里,也被称为聚簇索引(clustered index)。
- 非主键索引的叶子节点内容是主键的值。在 InnoDB 里,非主键索引也被称为二级索引。
- 非主键索引查询会回表。
- 自增id可以避免维护B+树时的分裂、合并问题。
索引维护。
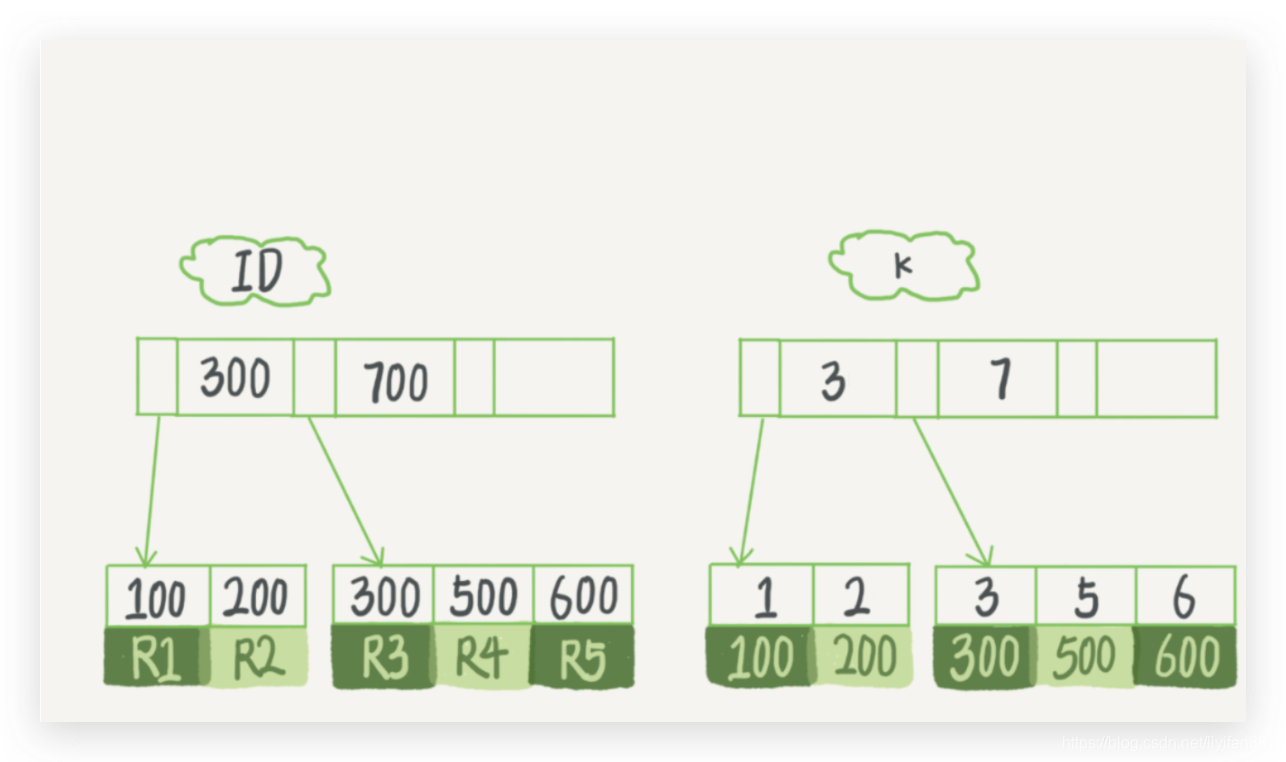
- B+ 树为了维护索引有序性,在插入新值的时候需要做必要的维护。以上面这个图为例,如果插入新的行 ID 值为 700,则只需要在 R5 的记录后面插入一个新记录。如果新插入的 ID 值为 400,就相对麻烦了,需要逻辑上挪动后面的数据,空出位置。
- 更糟情况是,如果 R5 所在的数据页已经满了,根据 B+ 树的算法,这时候需要申请一个新的数据页,然后挪动部分数据过去。这个过程称为页分裂。在这种情况下,性能自然会受影响。
- 除了性能外,页分裂操作还影响数据页的利用率。原本放在一个页的数据,现在分到两个页中,整体空间利用率降低大约 50%。
- 当然有分裂就有合并。当相邻两个页由于删除了数据,利用率很低之后,会将数据页做合并。合并的过程,可以认为是分裂过程的逆过程。
覆盖索引
- 即:where 非主键查询,但只查询ID,ID在非主键索引树上了,不需要回表。
联合索引
- 最左前缀
索引下推
- 对于where 条件,如果索引中包含了该字段信息,会直接进行过滤,不会再回表比对。
6. 全局锁和表锁
根据加锁的范围,MySQL 里面的锁大致可以分成全局锁、表级锁和行锁三类
- 全局锁的典型使用场景是,做全库逻辑备份
- Flush tables with read lock (FTWRL):其他线程的以下语句会被阻塞:数据更新语句(数据的增删改)、数据定义语句(包括建表、修改表结构等)和更新类事务的提交语句。
- 相较于readOnly,本命令在客户端异常后会自动释放锁。
- 表级锁(表锁和数据锁)
表锁的语法是 lock tables … read/write
另一类表级的锁是 MDL(metadata lock)。在 MySQL 5.5 版本中引入了 MDL,当对一个表做增删改查操作的时候,自动加 MDL 读锁;当要对表做结构变更操作的时候,加 MDL 写锁。- 读写锁、写锁之间互斥
MDL会导致该表结构时阻塞,online DDL可以看下。
7.行锁
MySQL 的行锁是在引擎层由各个引擎自己实现的。MyISAM 不支持行锁。不支持行锁意味着并发控制只能使用表锁,同张表上只能有一个更新在执行,这就会影响到业务并发度。
两阶段锁
在 InnoDB 事务中,行锁是在需要的时候才加上的,但并不是不需要了就立刻释放,而是要等到事务结束时才释放。这个就是两阶段锁协议。
- 如果事务中需要锁多个行,要把最可能造成锁冲突、最可能影响并发度的锁尽量往后放。
死锁
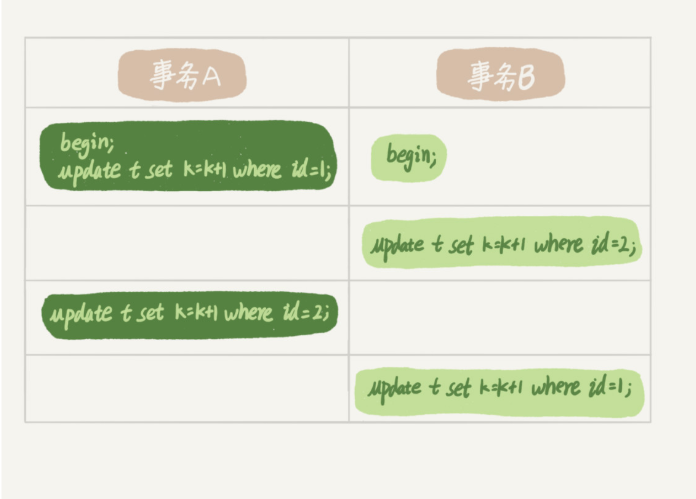
这样就互相等待了。(1互斥、占有且等待、不可剥夺、循环等待)
死锁后:
- 等待,设置超时时间
- 死锁检测,主动回滚某个事务(推荐且默认)。
- 但并发过多时,死锁检测耗费CPU过多。
- 保证不出现,关闭检测。
- 控制并发度
- 但并发过多时,死锁检测耗费CPU过多。
8. 事务到底是不是隔离的
- begin/start transaction 命令并不是一个事务的起点,在执行到它们之后的第一个操作 InnoDB 表的语句,事务才真正启动。
- 在可重复读隔离级别下,事务在启动的时候就“拍了个快照”。注意,这个快照是基于整库的。
- 数据表中的一行记录,其实可能有多个版本 (row),每个版本有自己的 row trx_id,每个事务或者语句有自己的一致性视图。
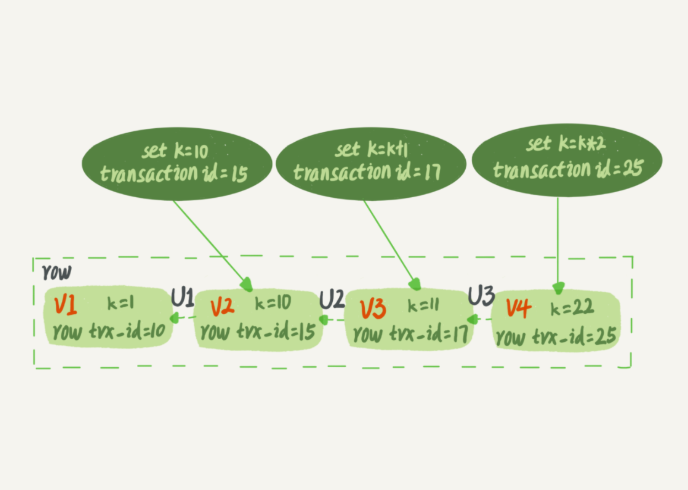
三个虚线箭头,就是 undo log;而 V1、V2、V3 并不是物理上真实存在的,每次需要时根据当前版本和 undo log 计算的。如需要 V2时,就通过 V4 依次执行 U3、U2 算出来。
- InnoDB 为每个事务构造了一个数组,用来保存这个事务启动瞬间,当前正在“活跃”的所有事务 ID。“活跃”指的就是,启动了但还没提交。事务 ID 的最小值记为低水位,当前系统里面已经创建过的事务 ID 的最大值加 1 记为高水位。
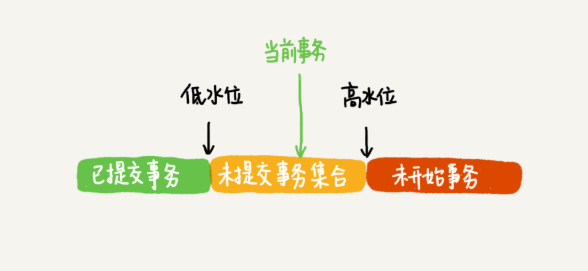
绿色可见,红色不可见。黄色中,如果在数组中,是未提交的事务生成的,不可见。否则可见。
**InnoDB 利用了“所有数据都有多个版本”的这个特性,实现了“秒级创建快照”的能力。**
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5877
5877




 到【灌水乐园】发言
到【灌水乐园】发言







