







 本文介绍了MySQL的备份方法,包括热备份、温备份和冷备份的区别,以及InnoDB的MVCC机制。重点讨论了mysqldump和Xtrabackup的实现原理,mysqldump依赖MVCC获取一致性视图,而Xtrabackup通过物理拷贝表空间和redo_log保证备份完整性。两者在备份速度、文件尺寸及是否影响数据库运行等方面各有优劣。
本文介绍了MySQL的备份方法,包括热备份、温备份和冷备份的区别,以及InnoDB的MVCC机制。重点讨论了mysqldump和Xtrabackup的实现原理,mysqldump依赖MVCC获取一致性视图,而Xtrabackup通过物理拷贝表空间和redo_log保证备份完整性。两者在备份速度、文件尺寸及是否影响数据库运行等方面各有优劣。
Mysql的备份之mysqldump与Xtrabackup
备份的分类
首先从备份时能否进行相应的读写操作进行分类为:
1.热备份:备份过程中数据库可以进行读写操作;
2.温备份:备份过程中数据库只能进行读操作,无法进行写操作;
3.冷备份:备份过程中数据库无法进行读写操作。
从执行引擎来说,Innodb支持三种类型的备份,其中热备份由MVCC机制支持,而MyISAM只支持温备份和冷备份。
从备份的性质或者说备份的结果来说又分为
1.逻辑备份:mysqldump就是一种逻辑备份,是SQL级别下的备份机制,将数据表导成SQL脚本。
2.物理备份:Xtrabackup是一种物理备份,简单理解就是直接备份数据文件。
备份之前应了解的概念
redo_log与bin_log
redo_log概述
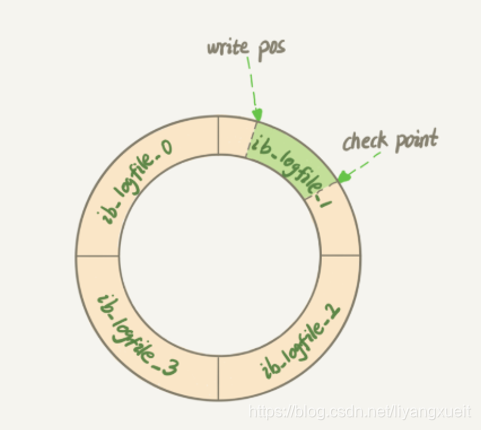
redo_log是Mysql引擎层上的日志,只有InnoDB支持,和bin_log一样都是Mysql中WAL(Write-Ahead-loging)技术机制中的一种,简单来说就是对于数据更改,先写入日志,再flush到磁盘当中。redo_log是一种物理格式的日志,也就是说记录的是数据页上发生的修改,区别于bin_log,bin_log是一种逻辑型的日志,记录的是具体某某数据发生了什么样的修改。redo_log采用的是循环写的模式,根据极客时间《mysql实战45讲》的内容,可以理解为下面一张图。也就是当写指针write_pos与check_pos之间还有位置时,就会进行日志的写入,当空间不足时,需要flush到磁盘种,推进check_pos指针的位置。所以数据库时不时会停下来进行redo_log的写入 磁盘操作。也就是讲义种提到的“抖”了一下。再一个注意的点是redo_log是数据发生修改时就会进行记录的,而bin_log则是在事务提交以后才进行读写。
bin_log概述
bin_log是mysql后期开发基于server层的日志,也叫做归档类日志,它不受sql引擎的限制,bin_log是采用“追加写”的形式,也就是说每发生数据修改就会在归档日志后面进行追加,而不像redo_log在逻辑上是采用一块环状固定大小的内存进行重复写入。bin_log从类型上来说分为三类,一类是基于Statement即SQL语句的复制(SBR)、一类是基于行的复制(RBR)以及混合模式复制(MBR)。其中SBR指的是每有一条修改数据的SQL都会记录在bin_log种,RBR指的是没有数据行记录发生变化时,仅仅记录发生更改的数据行记录。第三种则是两者的结合。
SBR由于只记录对数据库修改记录起作用的SQL语句,所以能有效减少bin_log的日志量,日志文件较小,节约了磁盘读写的IO操作,是一种比较高效的日志记录方式。所以比较适合用在数据库大规模集群方案当中,例如主从复制模式下,为了保证数据在主从数据库上的一致性和同步性,slave会通过一个IO进程读取master上的bin_log。将至读取到自己的中继日志当中,然后进行数据同步操作。
RBR的话由于记录的是每个发生更改的数据行的变化,所以记录的信息可读性较高、信息详细。
redo_log与bin_log的应用场景
简单从用途上来说,redo_log由于是在事务运行过程中就被不断进行读写,所以一般适合用于保证数据库事务的持久性,而bin_log是在事务提交之后才进行记录的,所以主要通途是主从复制、以及数据恢复的。
MVCC
MVCC就是多版本控制并发的机制。是Mysql在可重复读隔离级别下采用的一种保证事务之间数据可见性、数据安全性的机制。MVCC的实现是通过在每个数据记录行中添加两个隐藏列,一个列保存数据的当前事务版本号id,一个保存数据行的删除时间。通过MVCC的控制,能够保证事务之间读不加锁、读写不冲突。下面具体说明是如何保证的
select情况:在事务读取数据行时,如何从能保证读取到该事务能看到的数据,一是确定数据的当前事务id要<=该事务的id,这就是说数据行在该事务开启之前就已经存在了,那当然是对于该事务可见的了。二是保证该数据行的删除时间要大于此事务id,也就是说该事务开启时以及执行过程中,此数据行还没有被删除。
update情况:update的操作主要被分为两个部分,一是删除原数据行,那就将删除的数据行的删除数时间的id记为该事务的id(删除的数据行其实还在数据库中,只是存放在undo_log中,其实也不是存放,是可以通过undo_log进行事务回滚,计算得到原来的数据)。二是插入新数据行,插入的新数据行的当前事务版本号就是此事务的id。
insert情况:插入的新数据行的当前事务版本号就是此事务的id。
delete情况:update的操作主要被分为两个部分,一是删除原数据行,那就将删除的数据行的删除数时间的id记为该事务的id。
所以通过这样的控制,不同事务的不同操作,给予了数据记录不同的事务id,从事务id与本身的id进行比较来控制事务可以看见哪些数据,从而达到了避免脏读、不可重复读、幻读的情况,保证了事务的隔离安全。那么具体是怎么实现的呢,这里需要简单回顾下《mysql实战45讲》的内容:
MVCC具体是如何保证事务隔离的
每一个事务在开启时都会保存一个活跃性事务的id数组(活跃性事务就是指那些开启了但是还没有commit的事务),这些id中最大的叫做高水平,是最晚开启的事务。最小的叫做低水平是最早开启的事务。
那么当数据行来了的时候,就分为三种情况了:
1.数据行事务id<低水位,这部分数据早在事务开始前就存在了,当然可见;
2.数据行事务id>高水位,这部分数据是最晚开启的事务操作过的数据,当然不可见。
3.数据行事务id处于低水位和高水位之间,又分为两种情况:
3.1 事务id<该数据行的事务id,那该事务是看不到该数据的;
3.2 事务id>该数据行的事务id,那该事务是看得到该数据的。
现在就能解释为什么快照读能保证不出现幻读现象了吧,就是基于MVCC和undo_log的控制。
而当前读的话由于读取的是最新版本的数据行,所以需要通过间隙锁和行锁组成next_key_locks来保证幻读的不发生。这展开说就太多了,先不说了。
mysqldump和Xtrabackup的实现原理
有了上述概念,现在就好理解两种备份工具的实现原理了。
mysqldump实现
实际上,mysqldump的实现就是通过MVCC机制拿到数据的一致性视图(我们知道每一个事务开启时都会生成一个数据的事务视图,在RR隔离级别下事务一开启就拿到这个视图,保证在事务执行过程中,一直见到的都是这个视图中的数据;在RC隔离级别下则是在食物中执行SQL查询时才生成事务视图),加入–single-transaction选项保证了拿到一致性视图,同时设置事务隔离级别为RR:SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ。此时还可以通过设置–master-data=1,添加flush table with read lock给数据库加全局性的锁,保证备份期间不被进行写操作。因为你知道的,MVCC只在InnoDB引擎的RR级别下起作用,所以有的时候备份还需要使用FTWRL。
Xtrabackup
Xtrabackup属于物理备份,是通过直接拷贝表空间,同时不断地扫描读取redo_log中的内容,完成备份后,进行flush engine logs操作,也就是将备份内容flush,确保所有的redo_log都被写入到拷贝的主机的磁盘中(redo_log的两阶段提交,由于Xtrabackup不拷贝bin_log,所以为了避免数据丢失,必须进行flush确保redo_log全部存盘。最后为了把其他引擎的数据也进行拷贝,还要使用到FTWRL进行全局性的加锁拷贝。
mysqldump和Xtrabackup的优缺点
从实现原理和备份类型就很好理解二者的优缺点了:
1.mysqldump采用的一致性视图拷贝的方式,当然拷贝到的内容为可读的SQL文件,可以用于跨平台的恢复;
2.mysqldump是逻辑备份,备份文件尺寸小于Xtrabackup,也便于长期存储;
3.mysqldump只支持单线程备份,速度较慢,还会造成Innodb Buffer Pool的污染;
4.xtrabackup支持Innod的在线热备份,对Innodb的缓冲没有影响;
5.xtrabackup的备份效率高,支持全备份和增量备份(需要读取redo_log);
Pool的污染;
4.xtrabackup支持Innod的在线热备份,对Innodb的缓冲没有影响;
5.xtrabackup的备份效率高,支持全备份和增量备份(需要读取redo_log);

















 590
590

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









