






kubevirt-controller 代码解析(2)
在上一节点里面,我们阅读了virt-controller的源码,但其中我们漏了一个函数:
err = c.updateStatus(vmi, pod, dataVolumes, syncErr)

}
这个循环就是不断是监视着vmi pod的创建:
- 如果这个pod没有被创建,就通过一系列的pod模板最后生成pod并启动pod。
- 如果创建了,就获取pod。
- 最后都会进入updateStatus方法来监视
从某种意义上来说,sync和updateStatus函数是解耦的。
官方的workflow
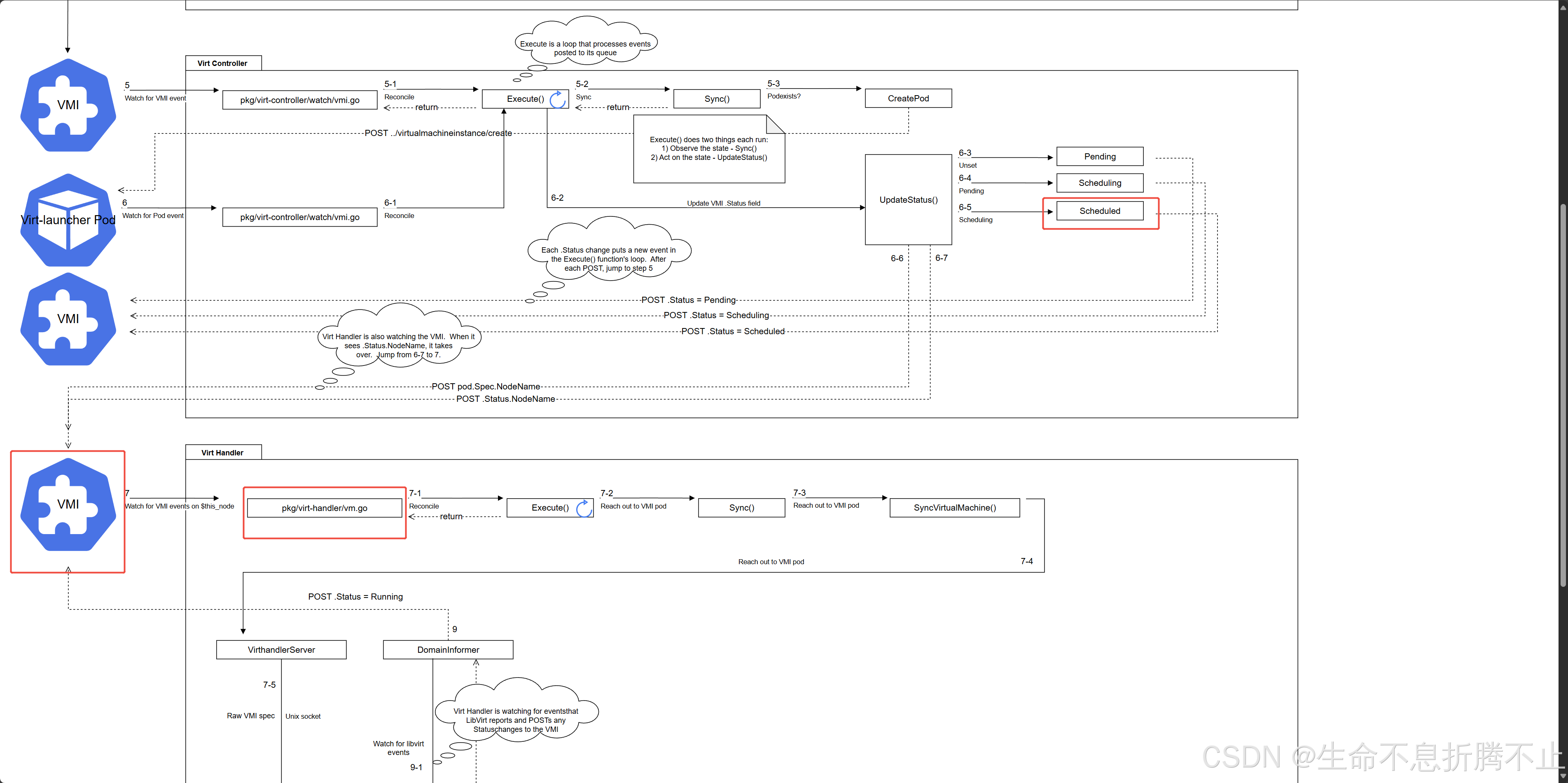
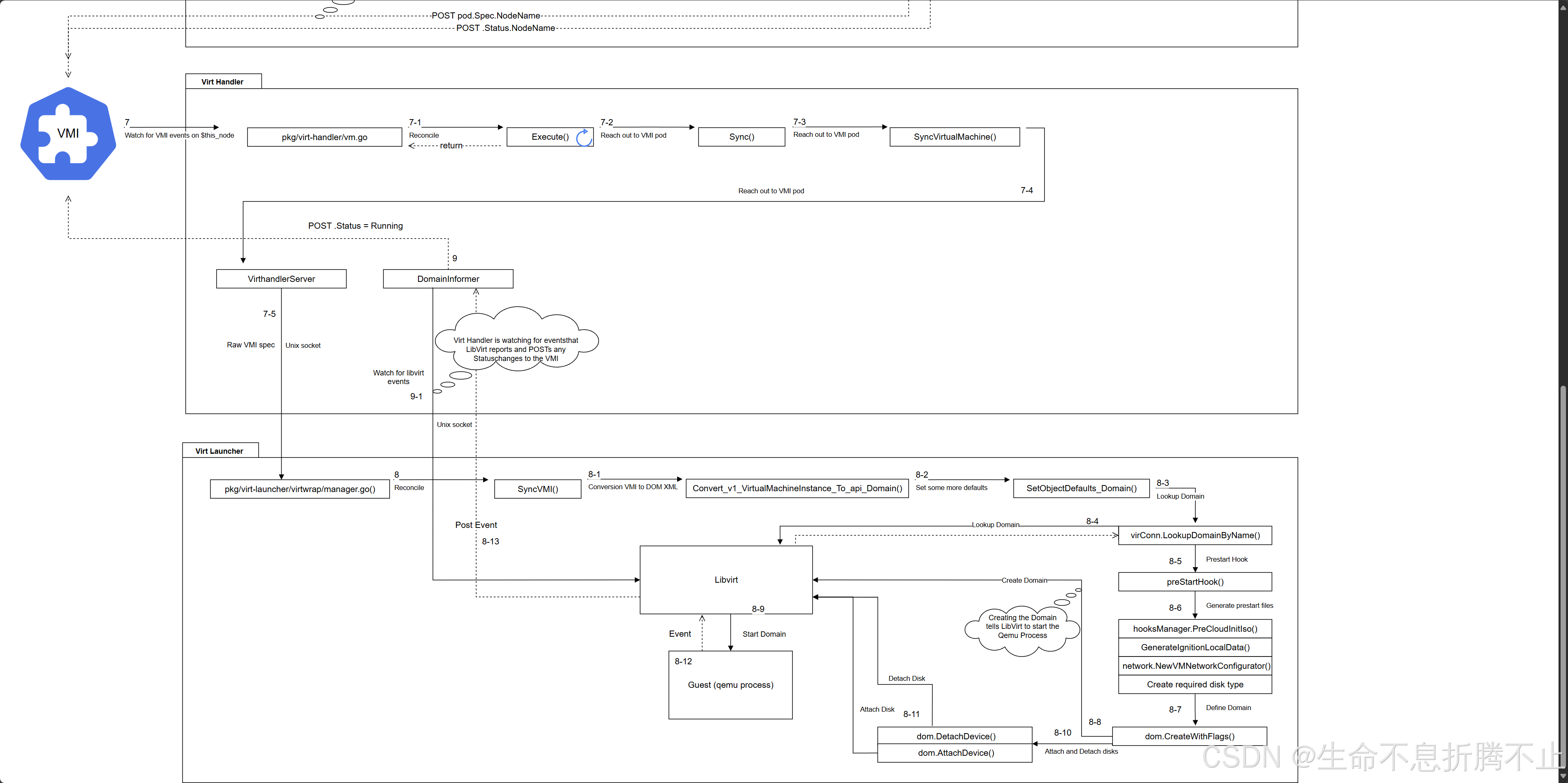
我们可以看到,updateStatus会一直等待pod的scheduled的完成。 然后再将由virt-handler来处理,而不是我们想象的由virt-launcher来调用virt-handler来处理。
handler在接收到vmi pod被调用到自身的消息后,会通过unix-scoket方式告诉virt-launcher来进行启动等操作。 这流程也太爆炸了吧。
updateStatus函数在做什么
func (c *Controller) updateStatus(vmi *virtv1.VirtualMachineInstance, pod *k8sv1.Pod, dataVolumes []*cdiv1.DataVolume, syncErr common.SyncError) error {
// 获取 vmi key
key := controller.VirtualMachineInstanceKey(vmi)
// 最后更新work queue
defer virtControllerVMIWorkQueueTracer.StepTrace(key, "updateStatus", trace.Field{Key: "VMI Name", Value: vmi.Name})
// 是否有错误的dv
hasFailedDataVolume := storagetypes.HasFailedDataVolumes(dataVolumes)
hasWffcDataVolume := false
// there is no reason to check for waitForFirstConsumer is there are failed DV's
if !hasFailedDataVolume {
hasWffcDataVolume = storagetypes.HasWFFCDataVolumes(dataVolumes)
}
conditionManager := controller.NewVirtualMachineInstanceConditionManager()
podConditionManager := controller.NewPodConditionManager()
// 进行一次深拷贝
vmiCopy := vmi.DeepCopy()
// vmipod 和temppod是否都创建,但实际上他们两个是一个。
vmiPodExists := controller.PodExists(pod) && !isTempPod(pod)
tempPodExists := controller.PodExists(pod) && isTempPod(pod)
// 查看vmi pod是否已经都是active状态
vmiCopy, err := c.setActivePods(vmiCopy)
if err != nil {
return fmt.Errorf("Error detecting vmi pods: %v", err)
}
// 为pod做一个condition的状态更新。
c.syncReadyConditionFromPod(vmiCopy, pod)
// 如果vmiPodExists,更新一下pod中有用的信息到vmi的信息中
if vmiPodExists {
var foundImage string
for _, container := range pod.Spec.Containers {
if container.Name == "compute" {
foundImage = container.Image
break
}
}
vmiCopy = c.setLauncherContainerInfo(vmiCopy, foundImage)
if err := c.syncPausedConditionToPod(vmiCopy, pod); err != nil {
return fmt.Errorf("error syncing paused condition to pod: %v", err)
}
if err := c.syncDynamicLabelsToPod(vmiCopy, pod); err != nil {
return fmt.Errorf("error syncing labels to pod: %v", err)
}
}
// 将dv的信息也更新到vmi中
c.aggregateDataVolumesConditions(vmiCopy, dataVolumes)
// 将pvc的信息更新到vmi中。
if pvc := backendstorage.PVCForVMI(c.pvcIndexer, vmi); pvc != nil {
c.backendStorage.UpdateVolumeStatus(vmiCopy, pvc)
}
switch {
// vmi 还没有启动
case vmi.IsUnprocessed():
if vmiPodExists {
// pod exist, vmi status = scheduling
vmiCopy.Status.Phase = virtv1.Scheduling
} else if vmi.DeletionTimestamp != nil || hasFailedDataVolume {
// 如果有dv失败,vmi status = faild
vmiCopy.Status.Phase = virtv1.Failed
} else {
// 最后,vmi status = pending,
vmiCopy.Status.Phase = virtv1.Pending
if vmi.Status.TopologyHints == nil {
...
// 中间一堆暂时没有用到的判断
}
}
// 如果是scheduling了
case vmi.IsScheduling():
// Remove InstanceProvisioning condition from the VM
// 移除provisioning状态,也就是提供者状态,在ironic里面比较觉这个状态
if conditionManager.HasCondition(vmiCopy, virtv1.VirtualMachineInstanceProvisioning) {
conditionManager.RemoveCondition(vmiCopy, virtv1.VirtualMachineInstanceProvisioning)
}
switch {
case vmiPodExists:
// ensure that the QOS class on the VMI matches to Pods QOS class
if pod.Status.QOSClass == "" {
vmiCopy.Status.QOSClass = nil
} else {
vmiCopy.Status.QOSClass = &pod.Status.QOSClass
}
// Add PodScheduled False condition to the VM
// 将pod的PodScheduled状态同步到VMI的PodScheduled状态
if podConditionManager.HasConditionWithStatus(pod, k8sv1.PodScheduled, k8sv1.ConditionFalse) {
conditionManager.AddPodCondition(vmiCopy, podConditionManager.GetCondition(pod, k8sv1.PodScheduled))
} else if conditionManager.HasCondition(vmiCopy, virtv1.VirtualMachineInstanceConditionType(k8sv1.PodScheduled)) {
// Remove PodScheduling condition from the VM
conditionManager.RemoveCondition(vmiCopy, virtv1.VirtualMachineInstanceConditionType(k8sv1.PodScheduled))
}
if imageErr := checkForContainerImageError(pod); imageErr != nil {
// only overwrite syncErr if imageErr != nil
syncErr = imageErr
}
// 检查pod的状态并更新VMI的状态
if controller.IsPodReady(pod) && vmi.DeletionTimestamp == nil {
// fail vmi creation if CPU pinning has been requested but the Pod QOS is not Guaranteed
podQosClass := pod.Status.QOSClass
if podQosClass != k8sv1.PodQOSGuaranteed && vmi.IsCPUDedicated() {
c.recorder.Eventf(vmi, k8sv1.EventTypeWarning, controller.FailedGuaranteePodResourcesReason, "failed to guarantee pod resources")
syncErr = common.NewSyncError(fmt.Errorf("failed to guarantee pod resources"), controller.FailedGuaranteePodResourcesReason)
break
}
// Initialize the volume status field with information
// about the PVCs that the VMI is consuming. This prevents
// virt-handler from needing to make API calls to GET the pvc
// during reconcile
if err := c.updateVolumeStatus(vmiCopy, pod); err != nil {
return err
}
if err := c.updateNetworkStatus(c.clusterConfig, vmiCopy, pod); err != nil {
log.Log.Errorf("failed to update the interface status: %v", err)
}
// vmi is still owned by the controller but pod is already ready,
// so let's hand over the vmi too
vmiCopy.Status.Phase = virtv1.Scheduled
if vmiCopy.Labels == nil {
vmiCopy.Labels = map[string]string{}
}
vmiCopy.ObjectMeta.Labels[virtv1.NodeNameLabel] = pod.Spec.NodeName
vmiCopy.Status.NodeName = pod.Spec.NodeName
// Set the VMI migration transport now before the VMI can be migrated
// This status field is needed to support the migration of legacy virt-launchers
// to newer ones. In an absence of this field on the vmi, the target launcher
// will set up a TCP proxy, as expected by a legacy virt-launcher.
if shouldSetMigrationTransport(pod) {
vmiCopy.Status.MigrationTransport = virtv1.MigrationTransportUnix
}
// Allocate the CID if VSOCK is enabled.
if util.IsAutoAttachVSOCK(vmiCopy) {
if err := c.cidsMap.Allocate(vmiCopy); err != nil {
return err
}
}
} else if controller.IsPodDownOrGoingDown(pod) {
vmiCopy.Status.Phase = virtv1.Failed
}
case !vmiPodExists:
// someone other than the controller deleted the pod unexpectedly
vmiCopy.Status.Phase = virtv1.Failed
}
case vmi.IsFinal():
allDeleted, err := c.allPodsDeleted(vmi)
if err != nil {
return err
}
if allDeleted {
log.Log.V(3).Object(vmi).Infof("All pods have been deleted, removing finalizer")
controller.RemoveFinalizer(vmiCopy, virtv1.VirtualMachineInstanceFinalizer)
if vmiCopy.Labels != nil {
delete(vmiCopy.Labels, virtv1.OutdatedLauncherImageLabel)
}
vmiCopy.Status.LauncherContainerImageVersion = ""
}
if !c.hasOwnerVM(vmi) && len(vmiCopy.Finalizers) > 0 {
// if there's no owner VM around still, then remove the VM controller's finalizer if it exists
controller.RemoveFinalizer(vmiCopy, virtv1.VirtualMachineControllerFinalizer)
}
case vmi.IsRunning():
// 判断 vmi是running状态下,但发生错误的情况
if !vmiPodExists {
vmiCopy.Status.Phase = virtv1.Failed
break
}
if err := c.updateVolumeStatus(vmiCopy, pod); err != nil {
return err
}
if err := c.updateNetworkStatus(c.clusterConfig, vmiCopy, pod); err != nil {
log.Log.Errorf("failed to update the interface status: %v", err)
}
if c.requireCPUHotplug(vmiCopy) {
c.syncHotplugCondition(vmiCopy, virtv1.VirtualMachineInstanceVCPUChange)
}
if c.requireMemoryHotplug(vmiCopy) {
c.syncMemoryHotplug(vmiCopy)
}
if c.requireVolumesUpdate(vmiCopy) {
c.syncVolumesUpdate(vmiCopy)
}
case vmi.IsScheduled():
if !vmiPodExists {
vmiCopy.Status.Phase = virtv1.Failed
}
default:
return fmt.Errorf("unknown vmi phase %v", vmi.Status.Phase)
}
// VMI is owned by virt-handler, so patch instead of update
// 将deepcopy的vmi的更新到现有的vmi上
if vmi.IsRunning() || vmi.IsScheduled() {
patchSet := prepareVMIPatch(vmi, vmiCopy)
if patchSet.IsEmpty() {
return nil
}
patchBytes, err := patchSet.GeneratePayload()
if err != nil {
return fmt.Errorf("error preparing VMI patch: %v", err)
}
_, err = c.clientset.VirtualMachineInstance(vmi.Namespace).Patch(context.Background(), vmi.Name, types.JSONPatchType, patchBytes, v1.PatchOptions{})
// We could not retry if the "test" fails but we have no sane way to detect that right now: https://github.com/kubernetes/kubernetes/issues/68202 for details
// So just retry like with any other errors
if err != nil {
return fmt.Errorf("patching of vmi conditions and activePods failed: %v", err)
}
return nil
}
reason := ""
if syncErr != nil {
reason = syncErr.Reason()
}
conditionManager.CheckFailure(vmiCopy, syncErr, reason)
controller.SetVMIPhaseTransitionTimestamp(vmi, vmiCopy)
// If we detect a change on the vmi we update the vmi
vmiChanged := !equality.Semantic.DeepEqual(vmi.Status, vmiCopy.Status) || !equality.Semantic.DeepEqual(vmi.Finalizers, vmiCopy.Finalizers) || !equality.Semantic.DeepEqual(vmi.Annotations, vmiCopy.Annotations) || !equality.Semantic.DeepEqual(vmi.Labels, vmiCopy.Labels)
if vmiChanged {
key := controller.VirtualMachineInstanceKey(vmi)
c.vmiExpectations.SetExpectations(key, 1, 0)
_, err := c.clientset.VirtualMachineInstance(vmi.Namespace).Update(context.Background(), vmiCopy, v1.UpdateOptions{})
if err != nil {
c.vmiExpectations.LowerExpectations(key, 1, 0)
return err
}
}
return nil
}
最终 ,这个函数就是不断的获取pod的状态,然后再更新到vmi上。

















 4950
4950

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









