




 本文介绍了Python爬虫的基础知识,通过requests库获取网页内容。讲解了User-Agent伪装的重要性,防止被服务器识别为非浏览器访问。并提供了一个完整的Python代码示例,展示如何爬取百度首页并保存为HTML文件。该程序展示了requests.get()方法的用法,以及如何设置headers来伪装User-Agent。
本文介绍了Python爬虫的基础知识,通过requests库获取网页内容。讲解了User-Agent伪装的重要性,防止被服务器识别为非浏览器访问。并提供了一个完整的Python代码示例,展示如何爬取百度首页并保存为HTML文件。该程序展示了requests.get()方法的用法,以及如何设置headers来伪装User-Agent。
1.使用requests模块,首先要进行安装。
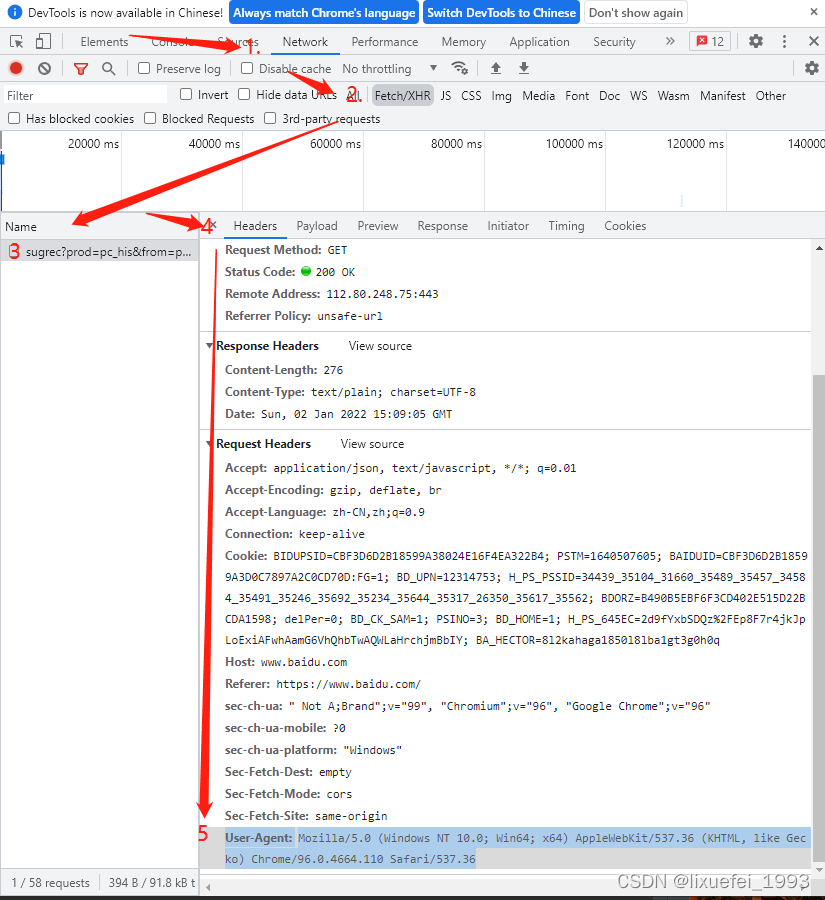
2.User-agent伪装(ua伪装),服务器会识别不是浏览器访问的请求,并对非浏览器访问的请求进行拦截。ua是一个以字典形式存储的信息,存放的是请求端的类型。不同浏览器,对应的ua是不一样的。
f12---->network----->XHR----->刷新显示sugrec----->Headers------>User-agent
3.完整程序如下:
# 爬取百度首页页面
import requests
url = "http://www.baidu.com"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36"
}
resp = requests.get(url,headers=headers)
with open("my_baidu.html", "w", encoding="utf-8") as fp:
fp.write(resp.text)
print("ok")

















 1348
1348

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









