







 该博客介绍分布式Hadoop安装配置教程,适用于win和mac环境。内容涵盖修改用户权限、主机名与映射,关闭防火墙,配置免密登录,安装JDK和Hadoop,进行时间同步,修改6个配置文件,最后启动并验证,完成完全分布式搭建。
该博客介绍分布式Hadoop安装配置教程,适用于win和mac环境。内容涵盖修改用户权限、主机名与映射,关闭防火墙,配置免密登录,安装JDK和Hadoop,进行时间同步,修改6个配置文件,最后启动并验证,完成完全分布式搭建。
环境:macOS 10.14.4 +parallel dosktop14 +4台centos7+secureCRT
此教程适合win和mac环境。
在安装分布式hadoop过程中,需要将所有机子的用户名必须一样,密码必须一样。
例如:
[zhangsan@centos-01 ~]$ :
用户名:zhangsan
主机名:centos-01
[root@centos-01]# :
用户名:root
主机名:centos-01
所以,@前面的是用户名,@后面的是主机名。
1.修改普通用户权限
先切换到root用户:# su
# vi /etc/sudoers
hadoop ALL=(ALL) ALL
2.修改主机名
切换普通用户:# su - hadoop
分别改成:
# hostnamectl set-hostname hadoop
# hostnamectl set-hostname node-1
# hostnamectl set-hostname node-2
# hostnamectl set-hostname node-3
3.修改主机映射:
需要普通用户权限:# su - hadoop
# sudo vi /etc/hosts
10.211.55.9 hadoop
10.211.55.10 node-1
10.211.55.11 node-2
10.211.55.12 node-3
可以每台主机都配一遍,也可以配好一台,然后发送给其他
# sudo scp /etc/hosts node-1:/etc/
# sudo scp /etc/hosts node-2:/etc/
# sudo scp /etc/hosts node-3:/etc/
4.关闭防火墙:
普通用户下:
# sudo systemctl stop firewalld.service
如果防火墙是iptables的话,
# sudo service iptables stop
补充一条查看防火墙状态的命令:
# sudo systemctl status firewalld
关闭selinux:
# sudo vi /etc/selinux/config
SELINUX=disabled
5.修改启动级别:
# sudo vi /etc/inittab
id:3:initdefault:
6.配置免密登录:
每台机器都需要配置,这步用secureCRT的window下面的tile,一起操作4台机器
切换到普通用户:# su - hadoop
第一步:生成密钥:
# ssh-keygen
第二步:发送密钥
# ssh-copy-id hadoop
# ssh-copy-id node-1
# ssh-copy-id node-2
# ssh-copy-id node-3
第三步:验证
# ssh hadoop
# ssh node-1
# ssh node-2
# ssh node-3
7.安装jdk:
先操作一台虚拟机:
①用secureCRT把jdk的压缩包传到虚拟机上。
②解压:
# tar -xvzf jdk1.8.0_11
③环境变量:
# sudo vi /etc/profile
export JAVA_HOME=/home/hadoop/jdk1.8.0_11
export HADOOP_HOME=/home/hadoop/hadoop-2.7.6
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# source /etc/profile
④验证:
# java -version
⑤一台机器的jdk环境搭建好后,发送给其他3台:
发送jdk文件:
# scp -r jdk1.8.0_11 node-1:$PWD
# scp -r jdk1.8.0_11 node-2:$PWD
# scp -r jdk1.8.0_11 node-3:$PWD
发送环境变量配置文件:
# sudo scp /etc/profile node-1:/etc/
# sudo scp /etc/profile node-2:/etc/
# sudo scp /etc/profile node-3:/etc/
8.时间同步:
在联网的情况下,同步到阿里云的系统时间:
# ntpdate ntp1.aliyun.com
9.安装hadoop
一定要切换普通用户
第一步:上传
第二步:解压
# tar -xvzf hadoop-2.7.6.tar.gz
第三步:配置环境变量:
由于配置jdk的时候配置了,所以直接执行# source /etc/profile
第四步:修改配置文件
配置文件目录:Hadoop_Home/etc/hadoop
需要修改6个配置文件:
①hadoop-env.sh
export JAVA_HOME=/home/hadoop/jdk1.8.0_11
②core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/data/hadoopdata</value>
</property>
</configuration>
③hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.dir</name>
<value>/home/hadoop/data/hadoopdata/name</value>
<description>为了保证元数据的安全一半配置多个不同目录</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/data/hadoopdata/data</value>
<description>datanode的数据存储目录</description>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
<description>HDFS数据块的副本存储数量</description>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>node-2:50090</value>
<description>secondarynamenode的运行节点信息,不能喝NameNode节点一样</description>
</property>
</configuration>
④ yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node-3</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
⑤mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
⑥slaves
hadoop
node-1
node-2
node-3
第五步:远程发送:
# cd ~
# scp -r hadoop-2.7.6 node-1:$PWD
# scp -r hadoop-2.7.6 node-2:$PWD
# scp -r hadoop-2.7.6 node-3:$PWD
第六步:执行source:
# source /etc/profile
第七步:格式化
只需要在主节点上格式化,而且必须在主节点
# hadoop namenode -format
10.启动
启动HDFS:
# start-dfs.sh 在任一节点都行
启动YARN:
# start-yarn.sh 在YARN的主节点
11.验证
# jps
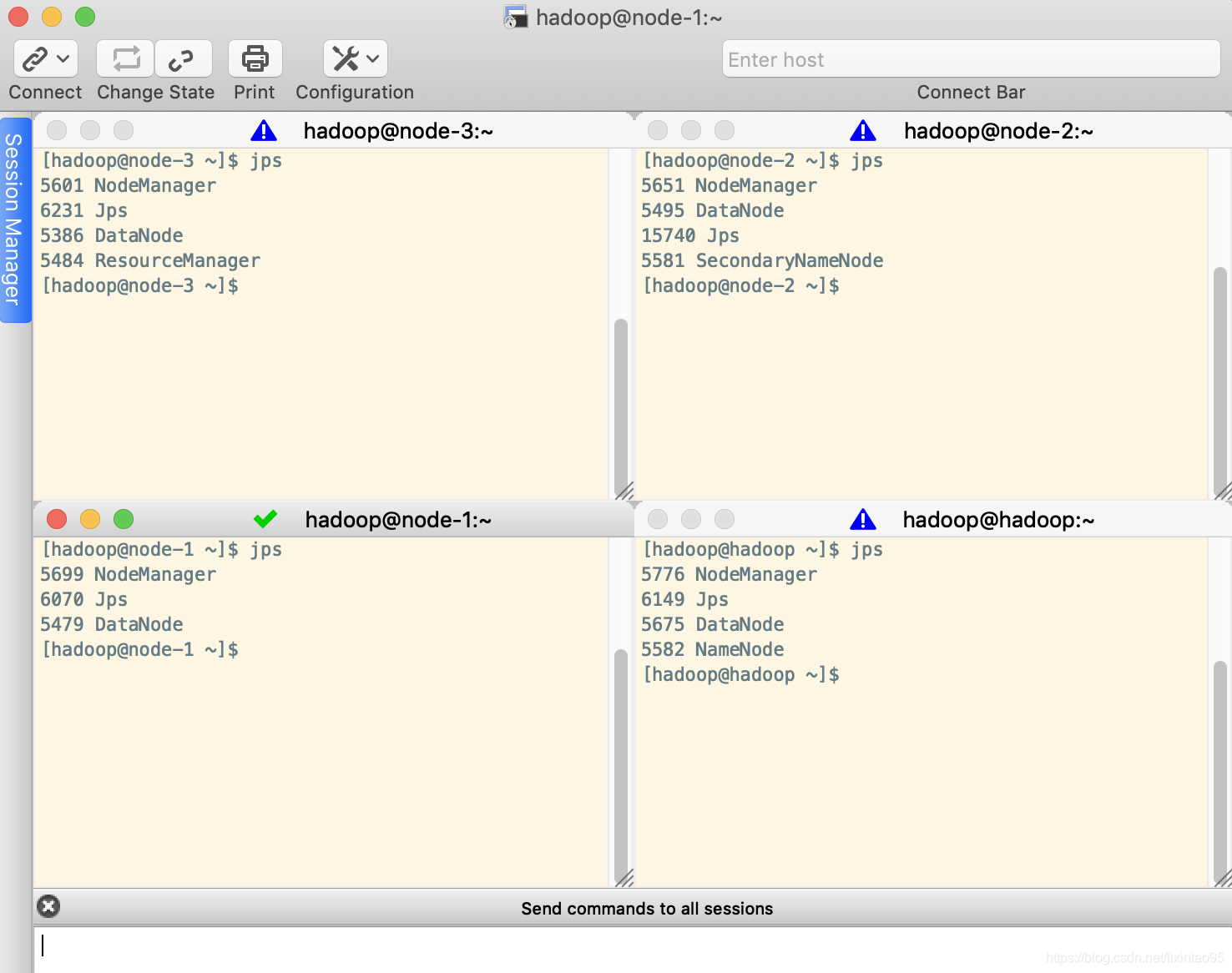
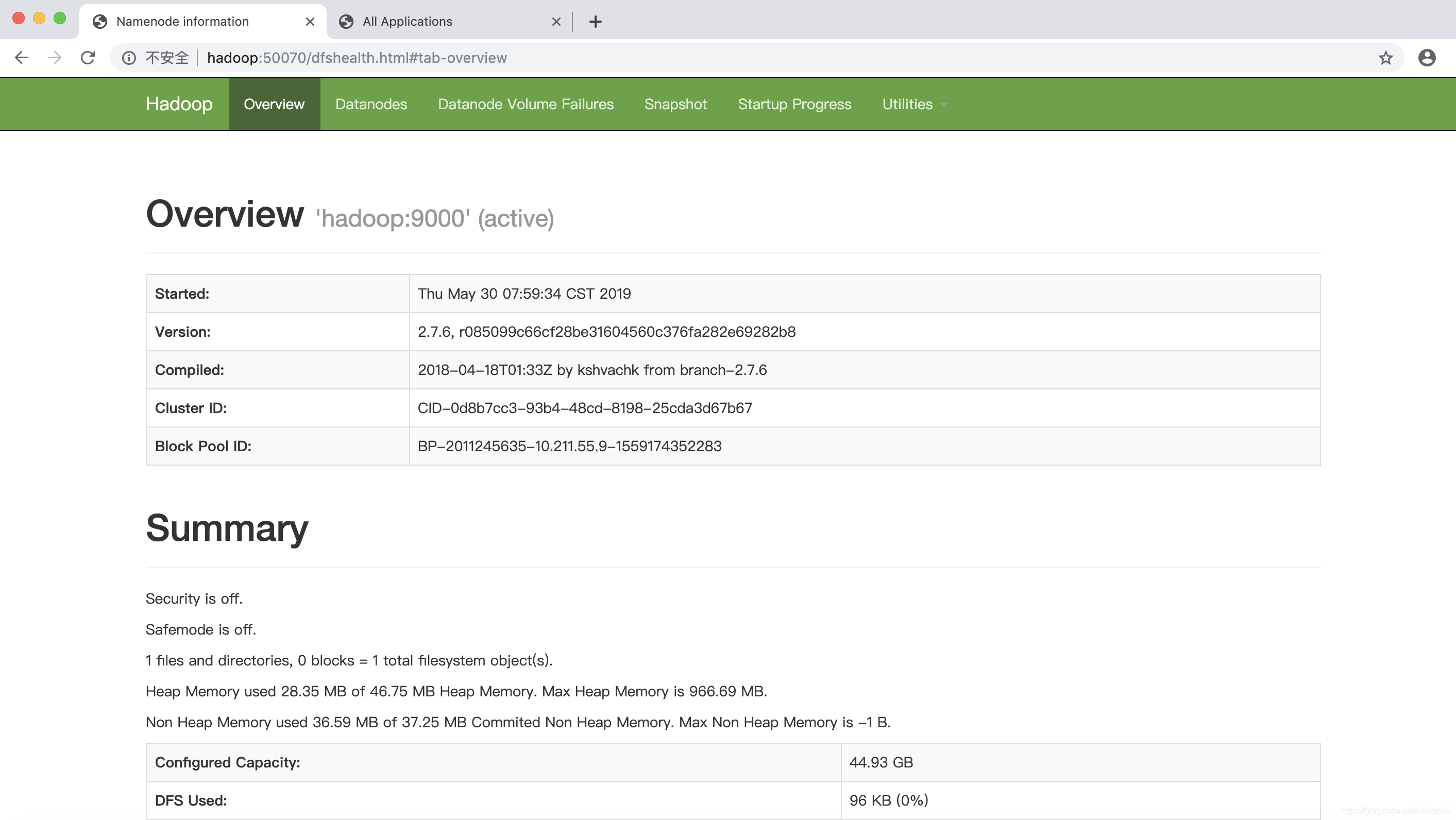
浏览器验证:
输入:hadoop:50070
输入:node-3:8088
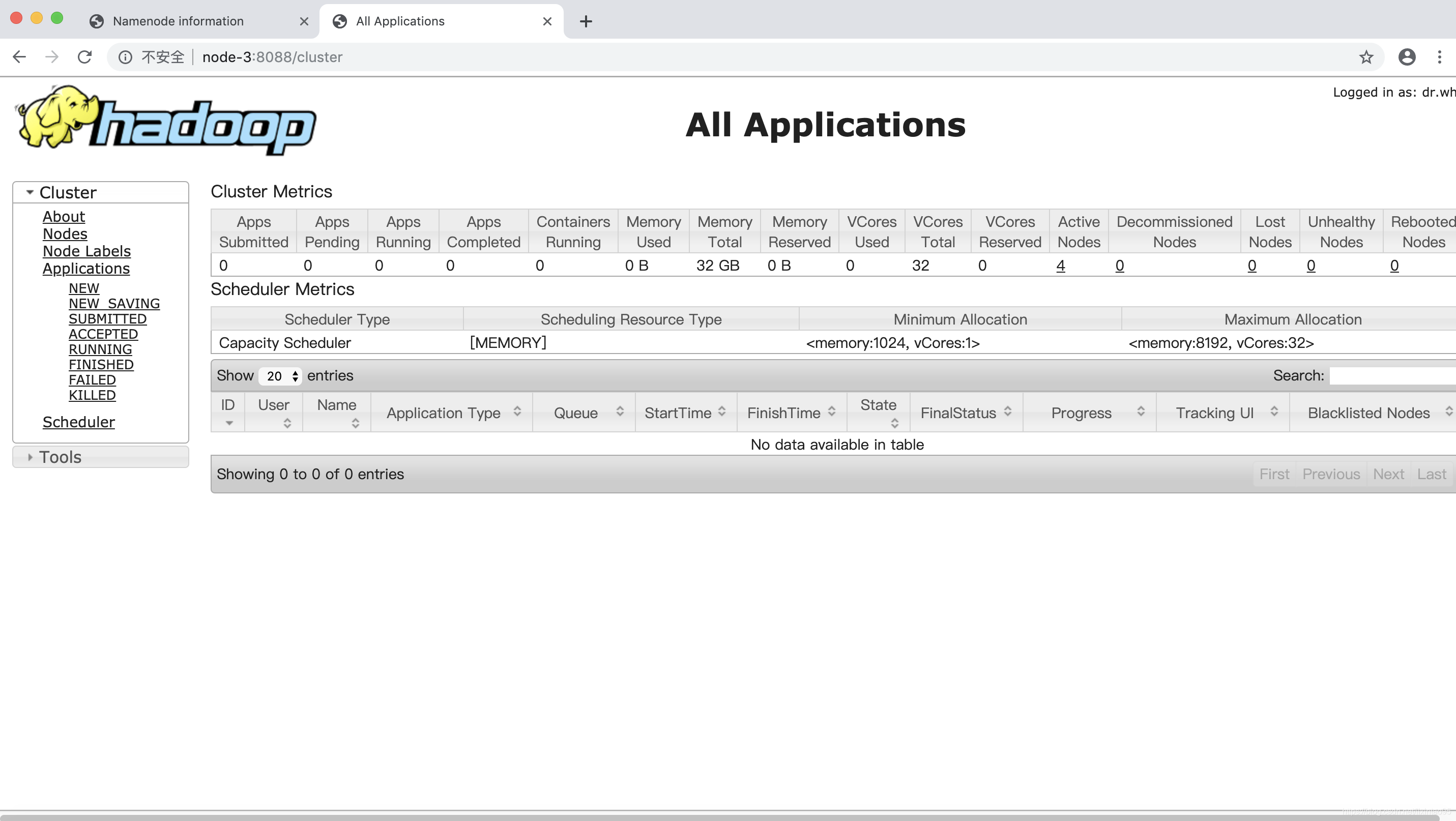
至此,完全分布式搭建完毕。

















 5418
5418

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









