







目录
1 Redis 的 pub/sub 发布/订阅
Redis 的 pub/sub 是一种标准的消息多播模式,用于进程间的消息传递
基本命令:
# 查询频道列表
PUBSUB CHANNELS
# 向频道发一个消息
PUBLISH channel message
# 订阅一个或多个频道
SUBSCRIBE channel [channel …]
# 按模式匹配订阅一个或多个频道
PSUBSCRIBE pattern [pattern …]
# 退订一个频道
UNSUBSCRIBE [channel [channel …]]
# 按模式匹配退订频道
PUNSUBSCRIBE [pattern [pattern …]]
特点:
-
非持久化:直接传输消息,不会持久化
-
即时性:消息是实时发送和接收
-
无状态:发布者和订阅者之间没有直接关联
-
适用场景:实时通信场景,如聊天应用、实时通知
2 Redis 的 streams 消息队列
Redis Streams 是一种持久化的消息队列实现,可以用于构建复杂的事件驱动应用程序和服务,Streams 允许你按顺序添加消息到一个逻辑有序的流中,并支持多消费者模型。
特点:
-
顺序性:消息是顺序的, 每 个消息都有一个唯一ID
-
持久化: 一旦消息被发送到 stream 中,就会被持久化到磁盘上,即使 redis 重启也不会丢失
-
消费者组 :支持消费者组模型, 可以有多个消费者同时消息进行消费
-
多消费者模型 :支持多个消费者同时消费消息, 消费者之间是竞争关系, 可以实现负载均衡
-
消息过期和修剪 :可以设置消息的过期时间,可以对 stream 的长度进行修剪
-
offset 机制: 消费者可以指定从一个起始 ID 读取消息,客户端 可以做到不丢失数据,消费 at least once
-
消息确认 :消费者在处理完消息后,需要向 redis 发送一个 ack 确认命令,告知 redis 消息已经被处理
基本命令:
# 向stream添加一条或多条消息
XADD stream_name * key value [key value …]
# 读取一个或多个stream中的消息
XREAD COUNT count STREAMS stream_name [id …]
# 从消费者组中读取消息
XREADGROUP GROUP group_name consumer_name COUNT count STREAMS stream_name [id …]
# 创建一个消费者组
# '$'表示消费的起始位置是从最新开始消费
XGROUP CREATE stream_name group_name $
# 还可以指定某个消息ID,以这个ID最为起始位置开始消费
XGROUP CREATE stream_name group_name {ID}
# 设置消费者组的起始消费位置
XGROUP SETID stream_name group_name $
# 销毁一个消费者组
XGROUP DESTROY stream_name group_name
# 删除消费者组中的消费者
XGROUP DELCONSUMER stream_name group_name consumer_name
# 确认一条消息已被成功处理
XACK stream_name group_name message_id 3 消息队列需要考虑的几个问题
(1) 生产者丢失消息
场景:
-
消息没发出去:网络故障或其它问题,中间件直接返回失败
-
消息发送超时:不确定是否发布成功
解决方式:
-
发送失败时重试,一般设置一个最大重试次数,若超过上限,记录日志或报警
-
对数据一致性要求更严格的可以记录此次任务到 db,等待后续重试
(2) 消费者丢失消息
场景:
-
消费者拿到消息后,还没处理完成,就异常挂掉
解决方式:
-
消费者处理完消息后告知 redis,redis 再把消息标记为已处理,表示已经消费成功,即 XACK 命令
-
一般的中间件如 RabbitMQ、Kafka 也都是利用这种方式处理的
(3) 中间件本身丢失消息
Redis 在以下两个场景下,是会导致数据丢失的:
-
AOF 持久化配置为每秒写盘,但这个写盘过程是异步的,Redis 宕机时会存在数据丢失的可能
-
主从复制也是异步的,主从切换时,也存在丢失数据的可能(从库还未同步完成主库发来的数据,就被提成主库)
因此 Redis 本身无法保证严格的数据完整性,所以如果把 Redis 当做消息队列,是有可能导致数据丢失的。
而像 RabbitMQ 或 Kafka 这类专业的队列中间件,在使用时一般都是部署一个集群,生产者在发布消息时,队列中间件通常会写'多个节点',以此保证消息的完整性。这样即便其中一个节点挂了,也能保证集群的数据不丢失。也正因为如此,它们在设计时也更复杂,毕竟是专门用作消息队列的。
但 Redis 的定位则不同,它的定位更多是当作缓存来用,在这个方面肯定是存在差异的。
(4) 消息积压问题
Kafka、RabbitMQ 的数据会存储在磁盘上,消息积压的压力较小。但是 Redis 的数据都存储在内存中,如果发生消息积压,可能出现 OOM。
Redis 的 Stream 提供了可以指定队列最大长度的功能,在添加消息时,可以设置 MAXLEN 来指定队列的最大长度,如果超过限制,redis 会把最早的消息删除,这样就避免了 Stream 占用过多内存。
总结一下,把 Redis 当作队列来使用时,始终会面临的两个问题:
-
Redis 本身可能会丢数据
-
面对大量消息积压,Redis 内存资源紧张
所以如果你的业务场景不复杂,对于数据丢失不敏感,而且消息积压概率比较小的情况下,把 Redis 当作队列是完全可以的。而且 Redis 相比于 Kafka 和 RabbitMQ,部署和运维也更加轻量。
4 GRPC 服务中实体的同步方案
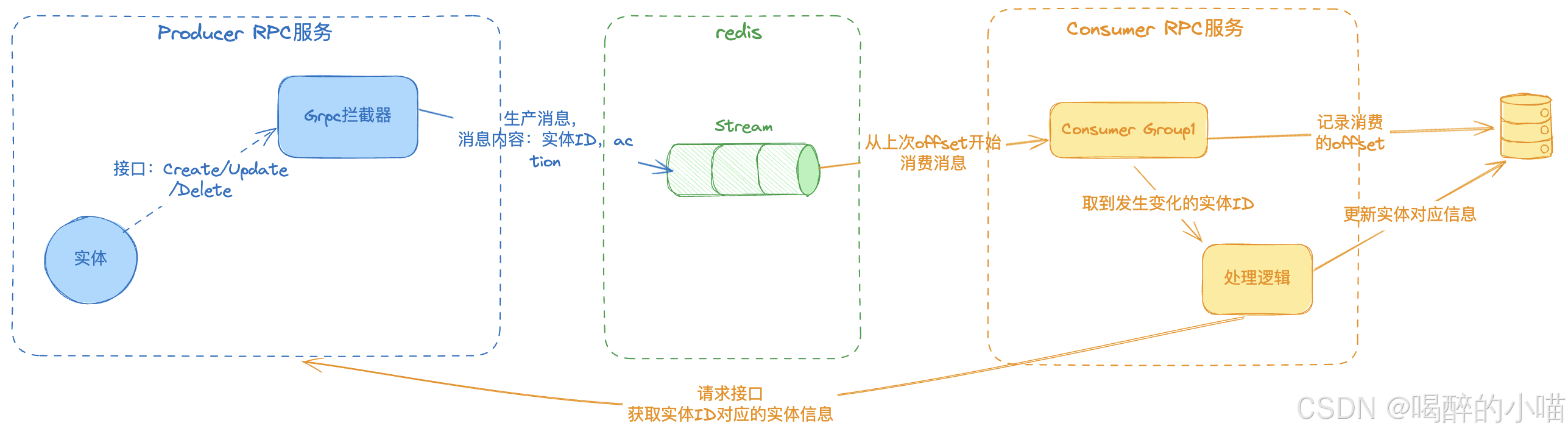
思路:
(1) 关于生产
-
利用 grpc 拦截器,当实体发生变化时,也就是实体的 Create/Update/Delete 接口被触发并成功返回时,由拦截器进行处理,生产一条消息到 stream channel
-
发送的消息内容为:实体 ID 、实体变化的 Action (即 create/update/delete)
-
生产消息时设置 stream 的最大队列长度 MAXLEN,避免大量数据积压
-
若生产消息失败,重试几次,若重试失败则记录日志
(2) 关于消费
-
不同的订阅者服务使用不同的 comsumer group,订阅同一个 channel 的消息,以保证多个服务都能收到消息
-
一个订阅者服务下的多个实例使用相同的 comsumer group,以保证消费不会重复触发业务逻辑
-
每个 consumer 要将自己消费的 offset 记录下来(可以记录到一个redis key),服务启动时从上次 offset 继续消费,如果没有记过 offset 则从0开始消费。这样保证服务宕机情况下不会丢失消息



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









