







闲来无事,看到了updateStateByKey&mapWithState两个算子,本着学而不思则罔,思而不学则殆的精神, 写了个小demo测试了一下加深印象,将他们收入脑中
updateStateByKey
按照惯例,首先来看官网解释

1:updateStateByKey算子归属于 Transformations on DStreams。
2:需要一个func作为入参,通过对之前 "state" 的每个key作用于这个func,返回一个 “新状态” 的DStream
/**
* Return a new "state" DStream where the state for each key is updated by applying
* the given function on the previous state of the key and the new values of each key.
* In every batch the updateFunc will be called for each state even if there are no new values.
* Hash partitioning is used to generate the RDDs with Spark's default number of partitions.
* @param updateFunc State update function. If `this` function returns None, then
* corresponding state key-value pair will be eliminated.
* @tparam S State type
*/
def updateStateByKey[S: ClassTag](
updateFunc: (Seq[V], Option[S]) => Option[S]
): DStream[(K, S)] = ssc.withScope {
updateStateByKey(updateFunc, defaultPartitioner())
}眼过千遍,不如手过一遍,来看示例
test demo :
package spark
import org.apache.spark.streaming._
import org.apache.spark.{SparkConf, SparkContext}
object stateWordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName("stateWordCount")
val sc = new SparkContext(conf)
val ssc = new StreamingContext(sc, Seconds(5))
//要保存状态,必须设置checkpoint
ssc.checkpoint("file:///d:/checkpoint")
val stream = ssc.socketTextStream("192.168.241.101", 9999)
val wordCountStream = stream.flatMap(_.split(" "))
.map(w => (w, 1))
def updateFunc(values: Seq[Int], option: Option[Int]) = {
//获取状态值
println("当前序列值为: " + values.mkString("----"))
var oldValue = option.getOrElse(0)
println("当前 oldvalue " + oldValue)
//遍历当前数据,并更新状态
for (value <- values) {
println("")
oldValue += value
}
//返回最新的状态
Option(oldValue)
}
val value = wordCountStream.updateStateByKey(updateFunc)
value.print()
ssc.start()
ssc.awaitTermination()
}
}
启动程序后控制台输出

现在通过999端口号输入内容,回车

idea中出现如下内容

通过内容可以直观看出 def updateFunc(values: Seq[Int], option: Option[Int]) = {...} 方法中
values: Seq[Int] 代表着 当前输入(hello,1)(hello,1) (hello,1)(spark,1)中以key分组,将所有值添加到一个seq中
例如 hello 对应着 Seq(1,1,1) spark 对应着 Seq(1),当然在一个处理过程中,只能是有一个key来做操作。
option: Option[Int] 代表着 当前处理环境中,获取到的当前key之前的状态,也就是描述中所说的 "previous state"
在updateFunc方法内部,需要自己去实现相应的func操作。例如例子中将每个输入值(key,1) 中的value值累加起来,像这样
for (value <- values) {
oldValue += value
}在得到被func处理的每个key结果以后,还需要把当前key的 "state" 返回,作为下一个处理操作中的 "previous state",为什么返回是Option类型呢,因为当前key的状态可能为None。
至此,想必大家对updateStateByKey这个算子有了一定的了解,这篇文章也可以收尾了。等等,你是不是觉得有点"别扭",没错,接着往下看。
从截图中可以看出,当前运行环境如果没有发生错误,被处理的所有key和state都会在每个batch中返回,包括新增的,状态改变过的和未改变过的,如此这样,当数据量庞大或者是运行时间较长,checkpoint会变得越来越大,处理性能也会越来越低。
看到这儿想必有人儿会想到,我只需要处理更改过的数据并返回,而不关心未更改的数据,如此是不是性能就会提升?
如果现在有某个需求要实现只处理被更改的数据,而不关心未改变的数据,那该怎么做呢?
出于对程序优化和具体业务场景的实现来思考,这也是一个程序员的价值所在。幸运的是,spark早在1.5版本之后便引入了另一个算子,mapWithState
/**
* :: Experimental ::
* Return a [[MapWithStateDStream]] by applying a function to every key-value element of
* `this` stream, while maintaining some state data for each unique key. The mapping function
* and other specification (e.g. partitioners, timeouts, initial state data, etc.) of this
* transformation can be specified using `StateSpec` class. The state data is accessible in
* as a parameter of type `State` in the mapping function.
*
* Example of using `mapWithState`:
* {{{
* // A mapping function that maintains an integer state and return a String
* def mappingFunction(key: String, value: Option[Int], state: State[Int]): Option[String] = {
* // Use state.exists(), state.get(), state.update() and state.remove()
* // to manage state, and return the necessary string
* }
*
* val spec = StateSpec.function(mappingFunction).numPartitions(10)
*
* val mapWithStateDStream = keyValueDStream.mapWithState[StateType, MappedType](spec)
* }}}
*
* @param spec Specification of this transformation
* @tparam StateType Class type of the state data
* @tparam MappedType Class type of the mapped data
*/
@Experimental
def mapWithState[StateType: ClassTag, MappedType: ClassTag](
spec: StateSpec[K, V, StateType, MappedType]
): MapWithStateDStream[K, V, StateType, MappedType] = {
new MapWithStateDStreamImpl[K, V, StateType, MappedType](
self,
spec.asInstanceOf[StateSpecImpl[K, V, StateType, MappedType]]
)
}是不是很好奇为什么在官网上没有搜到mapWithState这个算子,@Experimental 是实验性的功能,目前还未正式归类为transForm算子,但是不影响使用,也不排除里面有小惊喜哦。
好了, 言归正传,下面来进行demo演示
test demo:
package spark
import org.apache.spark.streaming._
import org.apache.spark.{SparkConf, SparkContext}
object stateWordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName("stateWordCount")
val sc = new SparkContext(conf)
val ssc = new StreamingContext(sc, Seconds(5))
//要保存状态,必须设置checkpoint
ssc.checkpoint("file:///d:/checkpoint")
val stream = ssc.socketTextStream("192.168.241.101", 9999)
val wordCountStream = stream.flatMap(_.split(" "))
.map(w => (w, 1))
val mappingFunction = (time: Time, key: String, option: Option[Int], state: State[Int]) => {
println("time: " + time)
println("key: " + key)
println("option: " + option.mkString("---"))
println("state: " + state)
val newValue = option.getOrElse(0) + state.getOption().getOrElse(0)
state.update(newValue)
Option((key, newValue))
}
val spec = StateSpec.function(mappingFunction)
val value = wordCountStream.mapWithState(spec)
value.print()
ssc.start()
ssc.awaitTermination()
}
}
老样子,9999 端口号输入数据
![]()
idea控制台输出
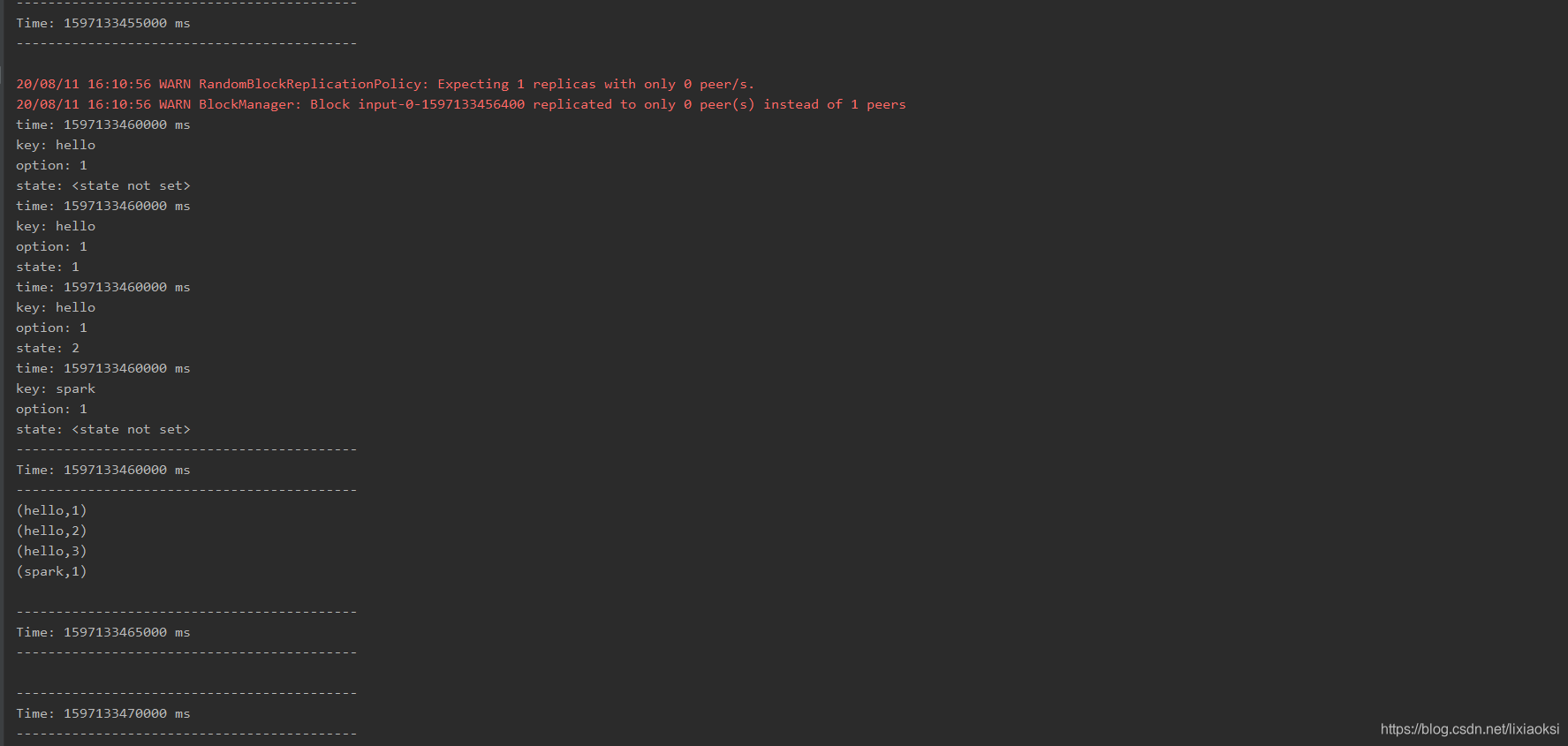
mapWithState 算子入参 spec: StateSpec[K, V, StateType, MappedType]
使用 StateSpec 伴生对象的 function 方法来获取 StateSpec 对象,接着来看 function 的入参 : 需要一个函数
mappingFunction: (Time, KeyType, Option[ValueType], State[StateType]) => Option[MappedType]
各个参数具体代表什么可结合上面源码和输出内容了解
可以看出当前输入值计算完成以后在接下来的批次中并未打印,接着我们继续来输入,验证之前计算的值是否还存在

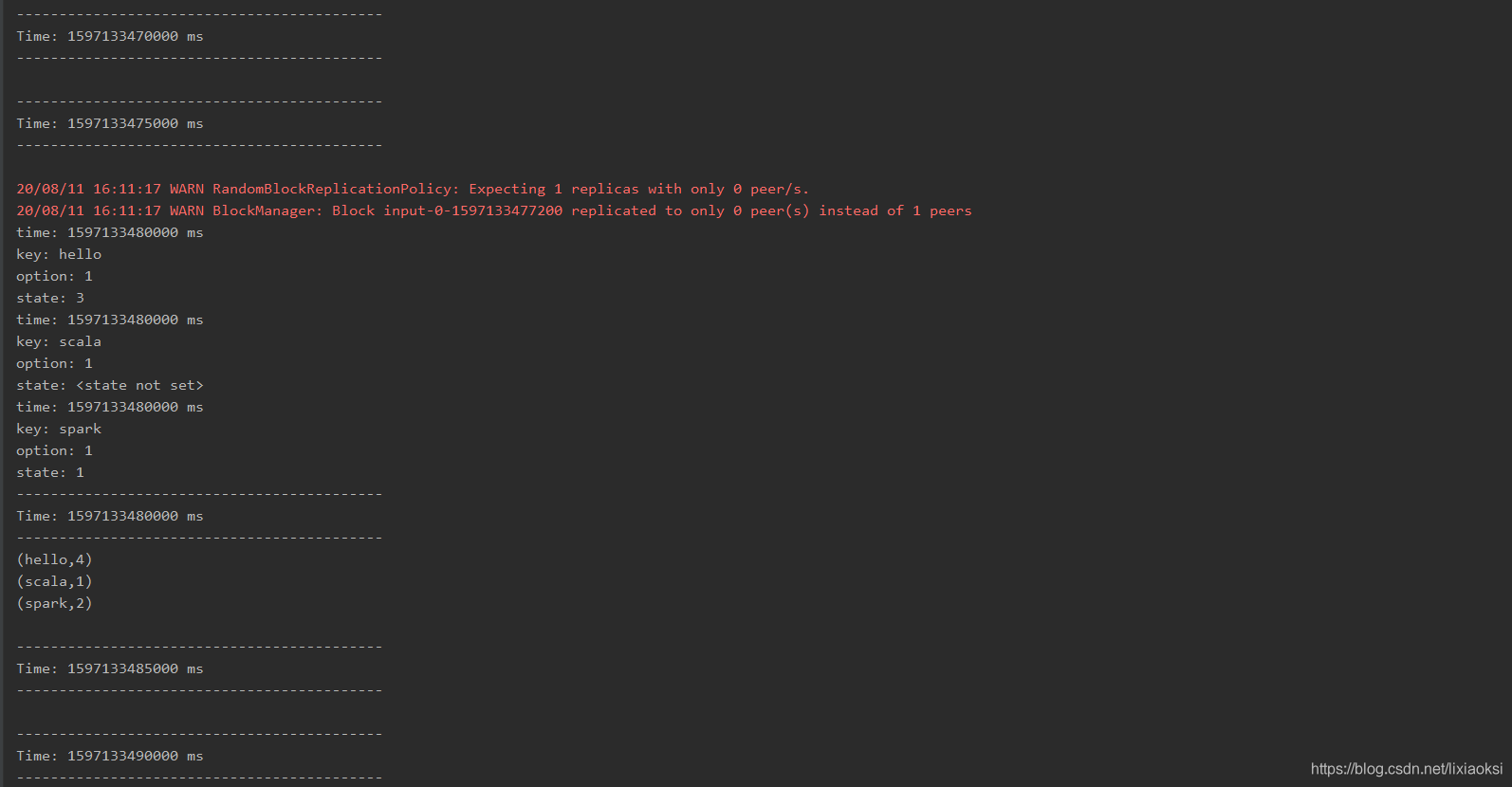
奈斯,之前输入数据的计算值仍在累计,而且处理的正是变化的数据,这样就减少了处理的数据量,只获取更改的数据,还不影响之前数据的状态。至于需要什么样的处理方式选择什么样的算子,还得根据具体业务来决定。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









