







1. 机器学习介绍
随着GPT、stable diffusion等生成式AI模型受到大众的广泛关注,机器学习也开始走向我们的视野。 那么什么是机器学习呢? 机器学习约等于让机器自动去找到一个函数 y = f ( x ) y= f(x) y=f(x) ,然后通过这个函数来解决我们任务中的问题。 例如:
- Midjourney:我们期望函数输入是一段文字,输出是一段图片
- GPT: 输入是一段文字,输出是另外一段文字
- 一个预测房价的模型:我们期望函数输入的是房子的属性(房子的地段、建筑年龄、周围的交通)。而函数的输出是房子的价格
- 一个图像辨识的模型:我们期望函数输入的是一张图片,输出是一只猫或 一只狗

2. 处理任务的分类
在机器学习处理的任务中,如果我们根据函数的输出来分类,可以分成两种类型的任务。
Regression(回归)
当我们训练一个模型做以下任务时:预测明天PM 2.5的数据、房价、股价时,函数 y = f ( x ) y = f(x) y=f(x)的输出结果是一个数值,这个时候机器在一个Regression(回归)任务来找到函数 y = f ( x ) y = f(x) y=f(x),再通过函数来预测我们要的数值。
Classification(分类)
当我们训练一个模型做以下任务时:识别垃圾邮件、图像内容分类,函数输出的是一个类型,实现我们是让函数去做一个选择题,这个时候机器可以通过逻辑回归(Logistic Regression)来找到函数模型。

AlphaGo是一个什么类型的任务?
3. 机器是怎么找到函数的
我们都知道在机器学习领域中,模型是通过训练数据(training data)训练出来的。这也就是我们前面说,机器学习约等于让机器自己去找到一个有效的函数模型。那么怎么让机器通过训练,找到有效的函数模型的呢?
机器找到有效的函数模型的过程,我们大概可以看成以下三个步骤:
- 设定函数范围
- 设定评估标准
- 达成目标
3.1 设定函数范围
在机器学习的任务中,我们通常说机器有一个neural network,机器通过这个neural network来计算具体的任务。这里的neural network其实是一堆函数的集合。
我们说机器学习约等于让机器自己去找到一个有效的函数,来完成具体的任务。这里是约等于而不是等于,因为函数的范围,是人根据机器要完成的具体任务、可训练的数据量、能获取的运算资源 来设计的。
不同类型的neural network
根据机器要完成的任务不同,人们设计了不同的neural network,如例:
- 当我们训练一个房价预测的模型时,我们可以采用fully connected network

- 为了处理图像识别任务,人们设计了CNN(Convolutional Neural Networks):

- 为了让机器能做语音识别,能处理nlp(Natural Language Processing)任务,人们设计了RNN,self-attention
函数集的大小
neural network是
y
=
f
(
x
)
y = f(x)
y=f(x)集合
如果
f
(
x
)
f(x)
f(x)可以是X一阶函数:
y
=
w
x
+
b
y = wx +b
y=wx+b
也可以是X的多阶函数:
y
=
w
n
x
n
+
w
n
−
1
x
n
−
1
+
.
.
.
+
w
x
+
b
y = w_nx_n+w_{n-1}x_{n-1} + ... +wx + b
y=wnxn+wn−1xn−1+...+wx+b
高阶函数的包含低阶函数,那么是不是阶数越多越好呢?函数集的范围是不是越大越好?这个问题,要根据我们能获取的数据集来看,如果数据集太小,函数集合太大,很可能我们的模型在训练数据中,可以获取很好的结果。但是在测试数据中,则不是很有效。
为什么会这样?因为neural network把训练数据的所有特征都背下来了,包括所有随机因素导致的结果变化,这种问题叫overfitting(过拟合)。所以函数集并不是越大越好。
3.2 设定评估标准
要让机器能够自动找到函数
y
=
f
(
x
)
y= f(x)
y=f(x),我们需要给机器设定一个评估函数好坏的标准。
那么什么样的函数,才能称之为好呢?答案是:目标导向
当我们设定一个模型来预测房价时,我们希望房价的真实成交值
y
y
y,跟我们模型的预测值
y
∼
\overset{\sim}{y}
y∼之差距越小越好,这两者之间的差距,我们称之为Loss。所以我们可以定义一个Loss function:
L
(
f
x
)
L(f_x)
L(fx)我们的目标是让
L
(
f
x
)
L(f_x)
L(fx)越小越好,所以我们可以用这个Loss function来做为评估标准。在Regression中,我的可以定义
L
(
f
x
)
=
∑
i
=
1
n
y
∼
i
−
y
n
L(f_x) = \sum{_{i=1}^{n}}\sqrt{\frac{\overset{\sim}{y}_i- y}{n}}
L(fx)=∑i=1nny∼i−y
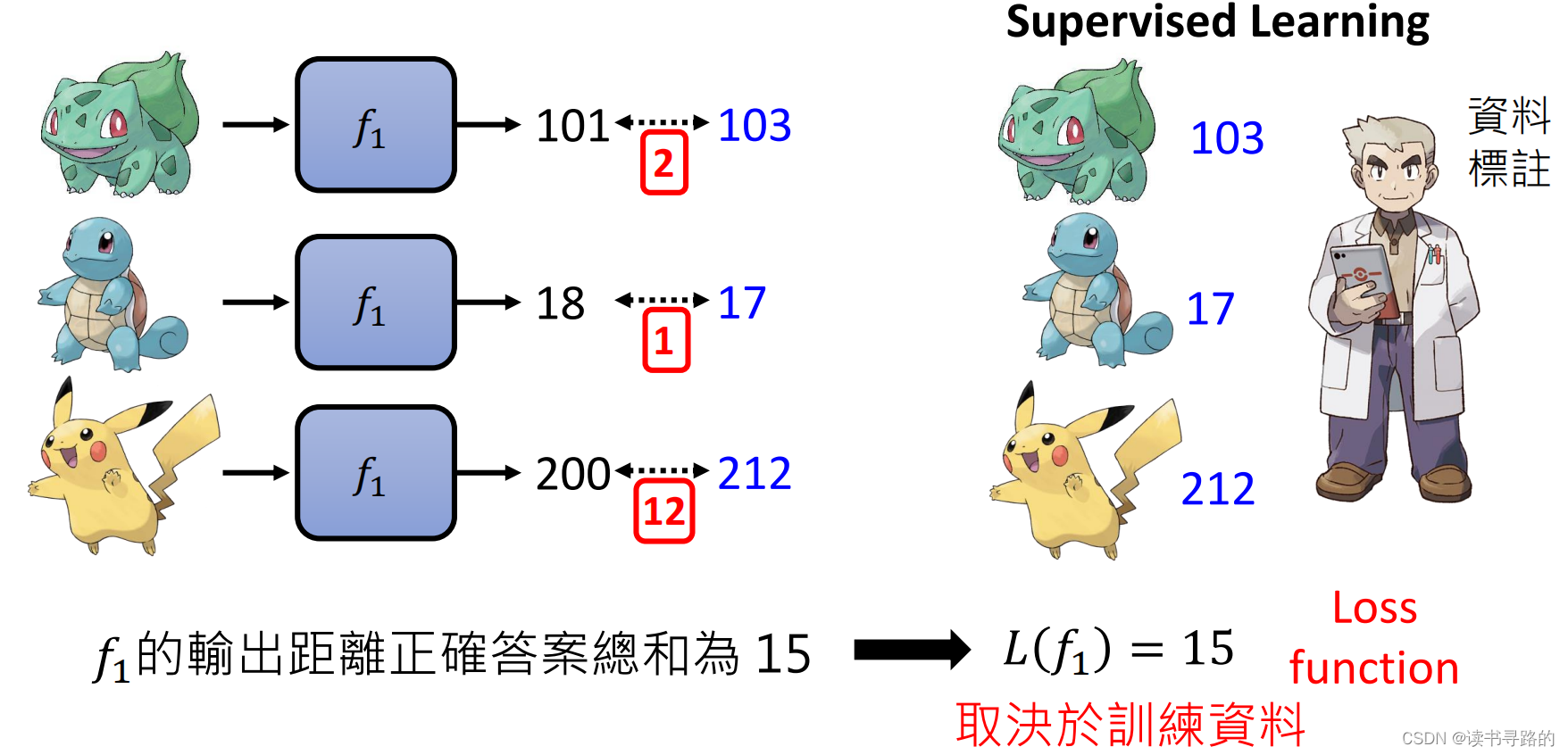
3.3 达成目标
我们已经设定好了函数集合,也有了评估函数好坏的标准,接下来就是给机器一种优化算法(Optimization),让机器能够自动的找到最佳的函数,使得Loss最小化:
f
∗
=
arg
min
f
∈
H
L
(
f
)
f^{*} = \mathop{\arg\min}\limits_{f\in\mathcal{H}}L(f)
f∗=f∈HargminL(f)
目前,机器寻找最佳函数的思路和方法,基本都是Gradient Descent(梯度下降)算法,使得Loss不断的趋近于局部最小值(local minima)。
对于函数
y
=
w
n
x
n
+
w
n
−
1
x
n
−
1
+
.
.
.
+
w
1
x
1
+
b
y = w_nx_n+w_{n-1}x_{n-1}+ ... +w_1x_1+b
y=wnxn+wn−1xn−1+...+w1x1+b
Gradient Descent是怎么找到最小的Loss的呢?
首先,我们假设
y
=
w
x
+
b
y = wx +b
y=wx+b,那么Loss function是一个参数为w的函数
L
(
w
)
L(w)
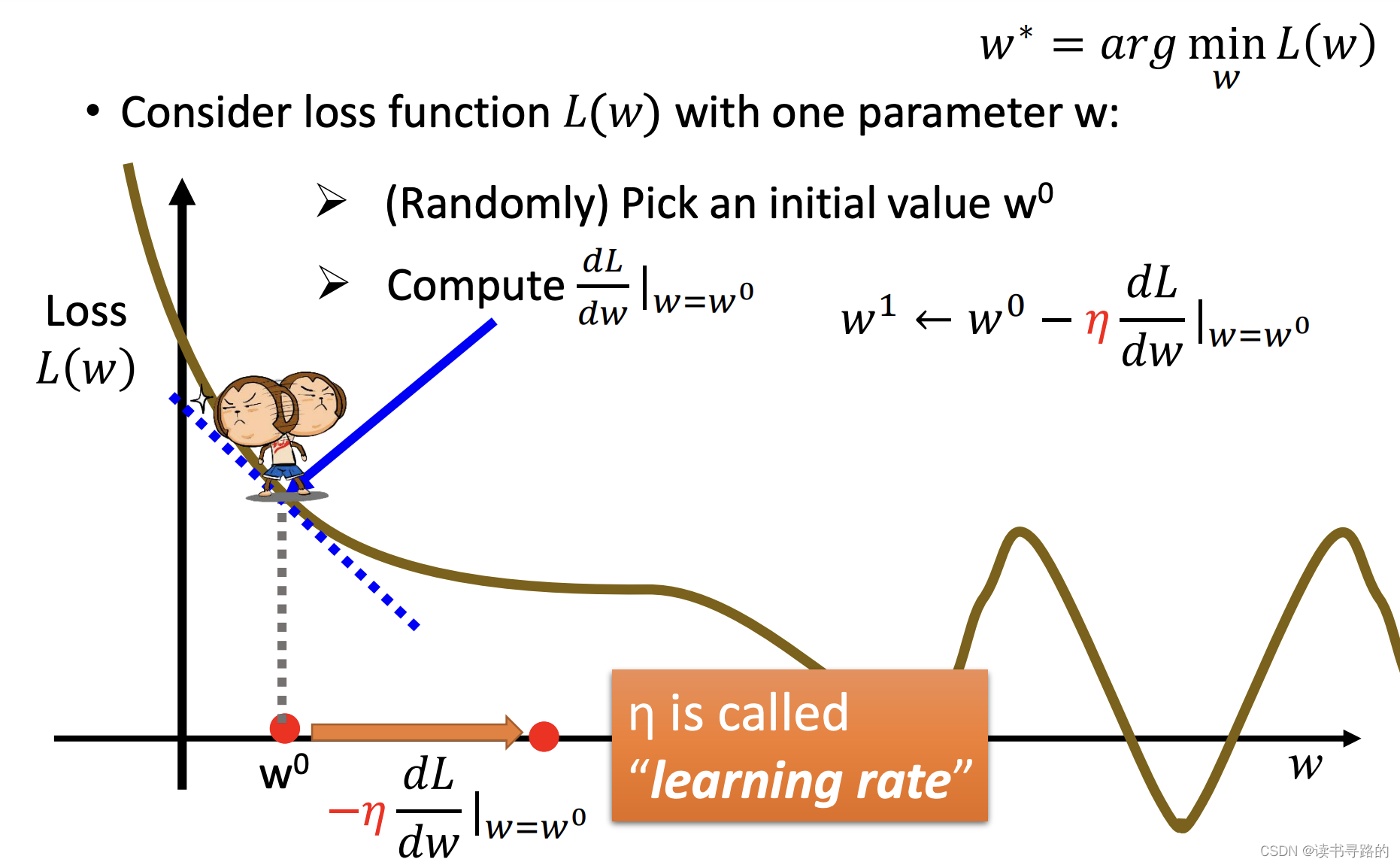
L(w),它是一个二维平面上的曲线,如下图拟示。Gradient Descent是通过以下步骤找到
L
(
w
)
L(w)
L(w)的最小值:
- [1] 首先,随机给函数参数一个初始值 w 0 w^0 w0
- [2] 计算 L ( w ) L(w) L(w)在 w 0 w_0 w0位置的微分,通过微分的正负,可以确定Loss下降的方向,如下图,当微分为负时,需要增加 w w w,当微分为正是,需要减小 w w w
- [3] 将 w w w从 w 0 w_0 w0移动到 w 1 w_1 w1。这里的移动幅度应该多长呢?一般我们在训练模型时,需设定一个learning rate( η \eta η),移动的幅度就是 η d L d w \eta \frac{dL}{dw} ηdwdL,所以 w 1 ← w 0 − η d L d w ∣ w = w 0 w_1 \gets w_0 - \eta\frac{dL}{dw}|_{w=w^0} w1←w0−ηdwdL∣w=w0
- [4]重复[2]、[3]直到Loss不再下降。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









