







 本文介绍了概率潜在语义分析(pLSA)的基本思想、生成模型,重点阐述了pLSA的EM算法,包括E-step和M-step,并探讨了pLSA的缺点。pLSA是一种基于生成模型的话题分析方法,利用隐变量表示话题,通过EM算法进行参数估计。
本文介绍了概率潜在语义分析(pLSA)的基本思想、生成模型,重点阐述了pLSA的EM算法,包括E-step和M-step,并探讨了pLSA的缺点。pLSA是一种基于生成模型的话题分析方法,利用隐变量表示话题,通过EM算法进行参数估计。
目录
Probabilistic latent semantic analysis (概率潜在语义分析,pLSA) 是一种Topic Model,在99年被 Thomas Hofmann 提出[1]。它和随后提出的LDA使得 Topic Model 成为了研究热点,其后的模型大都是建立在二者的基础上的。
1. 基本思想
PLSA模型通过一个生成模型来为LSA赋予了概率意义上的解释。该模型假设,每一篇文档都包含一系列可能的潜在话题,文档中的每一个单词都不是凭空产生的,而是在这些潜在的话题的指引下通过一定的概率生成的。
在 PLSA 模型里面,话题其实是一种单词上的概率分布,每一个话题都代表着一个不同的单词上的概率分布,而每个文档又可以看成是话题上的概率分布。每篇文档就是通过这样一个两层的概率分布生成的,这也正是PLSA 提出的生成模型的核心思想。
主题示例:给定一组词:证明,推导,对象,酒庄,内存,下列三个主题可以表示为:
- 数学主题:(0.45, 0.35, 0.2, 0, 0)
- 计算机主题:(0.2, 0.15, 0.45, 0, 0.2)
- 红酒主题:(0, 0, 0.2, 0.8, 0)
| 证明 |
推导 |
对象 |
酒庄 |
内存 |
|
| 数学 |
0.45 |
0.35 |
0.2 |
0 |
0 |
| 计算机 |
0.2 |
0.15 |
0.45 |
0 |
0.2 |
| 红酒 |
0 |
0 |
0.2 |
0.8 |
0 |
PLSA 的特点:
- 利用概率生成模型对文本集合进行话题分析的无监督学习方法
- 最大特点:用隐变量表示话题
- 整个模型表示文本生成话题,话题生成单词,从而得到单词-文本共现数据的过程
- 假设每个文本由一个话题分布决定,每个话题由一个单词分布决定
2. 生成模型
pLSA 遵从 bag-of-words 假设, 即只考虑一篇文档中单词出现的次数,忽略单词的先后次序关系,且每个单词的出现都是彼此独立的。 这样一来,我们观察到的其实就是每个单词在每篇文档
中出现的次数
。 pLSA 还假设对于每对出现的
都对应着一个表示“主题”的隐藏变量
。 pLSA 是一个生成模型,它假设
、
之间的关系用贝叶斯网络表示,如下图:
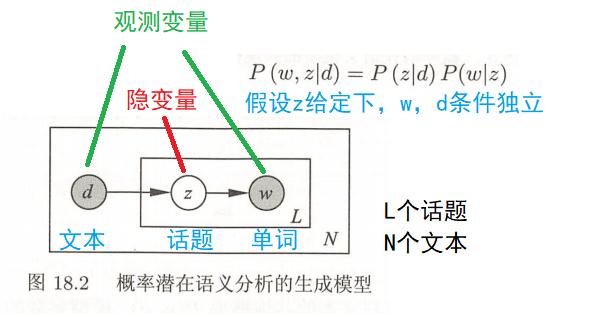
实心的节点 和
表示我们能观察到的文档和单词,空心的
表示我们观察不到的隐藏变量,用来表示隐含的主题。
表示单词出现在文档
的概率,
表示文档
中出现主题
下的单词的概率,
给定主题
出现单词
的概率。并且每个主题在所有词项上服从Multinomial 分布,每个文档在所有主题上服从Multinomial 分布。整个文档的生成过程是这样的:
- 以
的概率选中文档
;
- 以
的概率选中主题
;
- 以
的概率产生一个单词.
我们可以观察到的数据就是 对,而
是隐含变量。PLSA 通过下面这个式子对
的联合分布进行了建模(为方便,省略了下标):
其中,和
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1323
1323

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









