




 本文深入探讨了机器学习模型的分类与应用,包括传统单模型、集成与提升模型,以及神经网络与深度学习等。详细介绍了模型的训练、调参过程,并通过sklearn库进行实践演示,展示了GBDT、XGBoost、lightGBM等模型的使用方法。
本文深入探讨了机器学习模型的分类与应用,包括传统单模型、集成与提升模型,以及神经网络与深度学习等。详细介绍了模型的训练、调参过程,并通过sklearn库进行实践演示,展示了GBDT、XGBoost、lightGBM等模型的使用方法。
前面我们学习了数据预处理与特征工程
文章目录
1.机器学习模型概述
-
模型与算法
模型:一类问题的解题步骤,即一类问题的算法。
算法:能够解决特定问题的无歧义、机械、有效的运算流程和规则。 -
机器学习中的三要素
模型、策略与算法
模型:回归模型、分类模型
算法:有了模型和策略之后的优化算法:梯度下降法、牛顿法 -
机器学习模型
传统机器学习模型(单模型)
集成(ensemble)与提升(boosting)模型
神经网络与深度学习
2.传统机器学习模型(单模型)
-
按任务类型划分
-
分类
- 逻辑回归
- 决策树
- 朴素贝叶斯
- knn
- 感知机与神经网络
- 支持向量机
- …
-
回归
- 线性回归
- lasso
- ridge
- …
-
按性质划分
-
非概率模型(决策函数)
- 回归模型
- …
-
概率模型
- 决策树
- 朴素贝叶斯
- …
-
-
按知识体系划分
-
线性模型
- 线性回归
- 逻辑回归
- 线性可分支持向量机
- …
-
神经网络模型
- 逻辑回归
- 感知机
- 神经网络
- 深度学习
-
支持向量机模型
- 感知机
- svm
- tsvm
- …
-
贝叶斯模型
- 朴素贝叶斯
- 贝叶斯网络
- 高斯过程
- 贝叶斯机器学习
- …
-
树模型
- 决策树
- CART
- Adaboost(集成模型)
- GBDT(集成模型)
- …
-
3.集成与提升模型(boosting)
-
集成学习(ensemble learning)
构建并结合多个学习器来完成学习任务。
集成学习的关键在于构建“好而不同”的基学习器。 -
boosting
boosting族算法:将一组弱学习器提升为强学习器的框架算法。- Adaboost
- GBDT
- XGBoost
- lightGBM
- …
-
bagging
- 随机森林
4.sklearn
官网文档:http://sklearn.apachecn.org/cn/0.19.0/
- 预处理
- 降维
- 分类
- 回归
- 聚类
- 模型评估与选择
- …
5.机器学习调参
-
机器学习模型的参数有哪些?
- 模型训练参数:机器学习需要学习的东西,由训练得出,无需也无法调整
- 神经网络的权重与偏置
- 线性回归的变量系数
- …
- 模型配置参数
- 优化算法的学习率
- 训练轮数
- 树模型最大深度
- …
- 模型训练参数:机器学习需要学习的东西,由训练得出,无需也无法调整
-
机器学习模型参数调整方法
- 手动根据经验和尝试调整
- 网格搜索(Grid Search)
- 贝叶斯调参

6. GBDT/XGBoost/lightGBM
GBDT:梯度提升决策树,XGBoost和lightGBM也属于广义上的GBDT模型
GBDT属于加性模型,构建很多棵CART(分类回归树)并组合
import numpy as np
import matplotlib.pyplot as plt
from sklearn import ensemble
from sklearn import datasets
from sklearn.utils import shuffle
from sklearn.metrics import mean_squared_error
# #############################################################################
# 导入数据
boston = datasets.load_boston()
X, y = shuffle(boston.data, boston.target, random_state=13)
X = X.astype(np.float32)
offset = int(X.shape[0] * 0.9)
X_train, y_train = X[:offset], y[:offset]
X_test, y_test = X[offset:], y[offset:]
# #############################################################################
# 拟合模型
params = {'n_estimators': 500, 'max_depth': 4, 'min_samples_split': 2,
'learning_rate': 0.01, 'loss': 'ls'}
clf = ensemble.GradientBoostingRegressor(**params)
clf.fit(X_train, y_train)
mse = mean_squared_error(y_test, clf.predict(X_test))
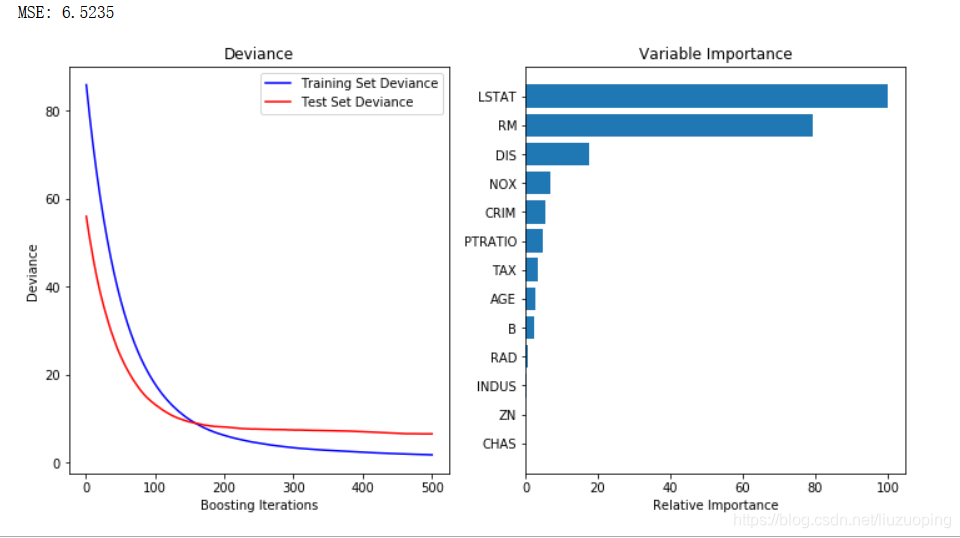
print("MSE: %.4f" % mse)
# #############################################################################
# 绘制训练误差图
# 计算测试误差
test_score = np.zeros((params['n_estimators'],), dtype=np.float64)
for i, y_pred in enumerate(clf.staged_predict(X_test)):
test_score[i] = clf.loss_(y_test, y_pred)
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.title('Deviance')
plt.plot(np.arange(params['n_estimators']) + 1, clf.train_score_, 'b-',
label='Training Set Deviance')
plt.plot(np.arange(params['n_estimators']) + 1, test_score, 'r-',
label='Test Set Deviance')
plt.legend(loc='upper right')
plt.xlabel('Boosting Iterations')
plt.ylabel('Deviance')
# #############################################################################
# 绘制特征重要性图
feature_importance = clf.feature_importances_
feature_importance = 100.0 * (feature_importance / feature_importance.max())
sorted_idx = np.argsort(feature_importance)
pos = np.arange(sorted_idx.shape[0]) + .5
plt.subplot(1, 2, 2)
plt.barh(pos, feature_importance[sorted_idx], align='center')
plt.yticks(pos, boston.feature_names[sorted_idx])
plt.xlabel('Relative Importance')
plt.title('Variable Importance')
plt.show();
XGBoost
import xgboost as xgb
data = np.random.rand(100000, 10)
label = np.random.randint(2, size=100000)
dtrain = xgb.DMatrix(data, label=label, missing = -999.0)
data2 = np.random.rand(5000, 10)
label2 = np.random.randint(2, size=5000)
dtest = xgb.DMatrix(data2, label=label2, missing = -999.0)
params = {'bst:max_depth':2, 'bst:eta':1, 'silent':1, 'objective':'binary:logistic' }
params['nthread'] = 4
params['eval_metric'] = 'auc'
evallist = [(dtrain,'train'), (dtest,'eval')]
num_round = 50
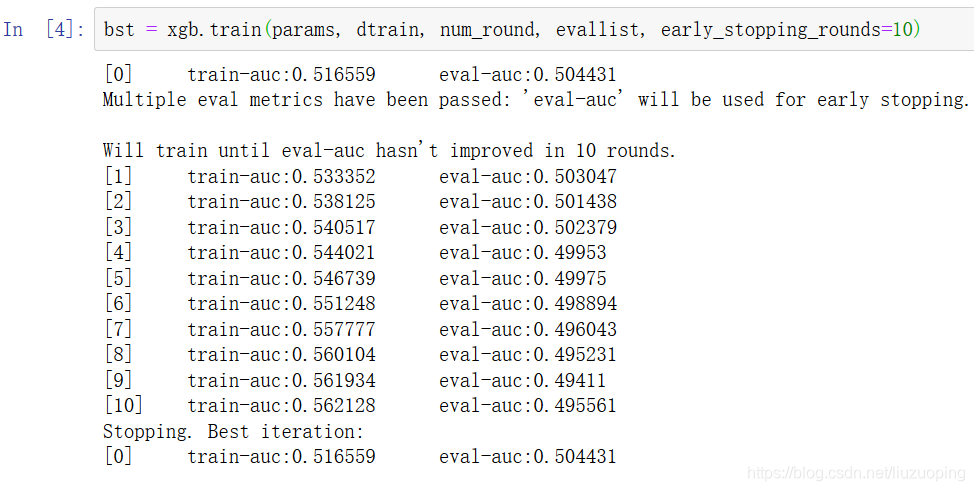
bst = xgb.train(params, dtrain, num_round, evallist)
运行结果
[0] train-auc:0.516559 eval-auc:0.504431
[1] train-auc:0.533352 eval-auc:0.503047
[2] train-auc:0.538125 eval-auc:0.501438
[3] train-auc:0.540517 eval-auc:0.502379
[4] train-auc:0.544021 eval-auc:0.49953
[5] train-auc:0.546739 eval-auc:0.49975
[6] train-auc:0.551248 eval-auc:0.498894
[7] train-auc:0.557777 eval-auc:0.496043
[8] train-auc:0.560104 eval-auc:0.495231
[9] train-auc:0.561934 eval-auc:0.49411
[10] train-auc:0.562128 eval-auc:0.495561
[11] train-auc:0.566582 eval-auc:0.496794
[12] train-auc:0.572806 eval-auc:0.496856
[13] train-auc:0.574817 eval-auc:0.498392
[14] train-auc:0.578393 eval-auc:0.501446
[15] train-auc:0.581842 eval-auc:0.502795
[16] train-auc:0.58251 eval-auc:0.503
[17] train-auc:0.584241 eval-auc:0.502965
[18] train-auc:0.586867 eval-auc:0.503516
[19] train-auc:0.587748 eval-auc:0.502868
[20] train-auc:0.588055 eval-auc:0.503148
[21] train-auc:0.588948 eval-auc:0.503913
[22] train-auc:0.589735 eval-auc:0.504179
[23] train-auc:0.593615 eval-auc:0.50847
[24] train-auc:0.595019 eval-auc:0.508871
[25] train-auc:0.600959 eval-auc:0.509517
[26] train-auc:0.60514 eval-auc:0.507851
[27] train-auc:0.609499 eval-auc:0.506131
[28] train-auc:0.610952 eval-auc:0.506491
[29] train-auc:0.611655 eval-auc:0.506577
[30] train-auc:0.612526 eval-auc:0.504905
[31] train-auc:0.615221 eval-auc:0.5043
[32] train-auc:0.617091 eval-auc:0.505534
[33] train-auc:0.620287 eval-auc:0.504286
[34] train-auc:0.621687 eval-auc:0.505322
[35] train-auc:0.623884 eval-auc:0.505586
[36] train-auc:0.624621 eval-auc:0.505535
[37] train-auc:0.625218 eval-auc:0.505306
[38] train-auc:0.625362 eval-auc:0.505215
[39] train-auc:0.625739 eval-auc:0.505164
[40] train-auc:0.628378 eval-auc:0.503613
[41] train-auc:0.633285 eval-auc:0.501812
[42] train-auc:0.635064 eval-auc:0.501316
[43] train-auc:0.637284 eval-auc:0.501624
[44] train-auc:0.639024 eval-auc:0.502469
[45] train-auc:0.640954 eval-auc:0.502014
[46] train-auc:0.643208 eval-auc:0.499882
[47] train-auc:0.645045 eval-auc:0.499513
[48] train-auc:0.648184 eval-auc:0.500682
[49] train-auc:0.649412 eval-auc:0.500792
bst = xgb.train(params, dtrain, num_round, evallist, early_stopping_rounds=10)
lightGBM
import lightgbm as lgb
data = np.random.rand(100000, 10)
label = np.random.randint(2, size=100000)
train_data = lgb.Dataset(data, label=label)
data2 = np.random.rand(5000, 10)
label2 = np.random.randint(2, size=5000)
test_data = lgb.Dataset(data2, label=label2)
param = {'num_leaves':31, 'num_trees':100, 'objective':'binary', 'metrics': 'binary_error'}
num_round = 10
bst = lgb.train(param, train_data, num_round, valid_sets=[test_data])
[1] valid_0’s binary_error: 0.5028
[2] valid_0’s binary_error: 0.5068
[3] valid_0’s binary_error: 0.5084
[4] valid_0’s binary_error: 0.5106
[5] valid_0’s binary_error: 0.5084
[6] valid_0’s binary_error: 0.511
[7] valid_0’s binary_error: 0.5094
[8] valid_0’s binary_error: 0.5102
[9] valid_0’s binary_error: 0.5124
[10] valid_0’s binary_error: 0.511
[11] valid_0’s binary_error: 0.5088
[12] valid_0’s binary_error: 0.506
[13] valid_0’s binary_error: 0.5078
[14] valid_0’s binary_error: 0.5106
[15] valid_0’s binary_error: 0.5096
[16] valid_0’s binary_error: 0.5116
[17] valid_0’s binary_error: 0.511
[18] valid_0’s binary_error: 0.5096
[19] valid_0’s binary_error: 0.5086
[20] valid_0’s binary_error: 0.5108
[21] valid_0’s binary_error: 0.5106
[22] valid_0’s binary_error: 0.51
[23] valid_0’s binary_error: 0.5078
[24] valid_0’s binary_error: 0.5088
[25] valid_0’s binary_error: 0.5076
[26] valid_0’s binary_error: 0.5068
[27] valid_0’s binary_error: 0.5064
[28] valid_0’s binary_error: 0.5068
[29] valid_0’s binary_error: 0.5058
[30] valid_0’s binary_error: 0.5066
[31] valid_0’s binary_error: 0.5074
[32] valid_0’s binary_error: 0.5072
[33] valid_0’s binary_error: 0.5056
[34] valid_0’s binary_error: 0.5056
[35] valid_0’s binary_error: 0.505
[36] valid_0’s binary_error: 0.5048
[37] valid_0’s binary_error: 0.5042
[38] valid_0’s binary_error: 0.504
[39] valid_0’s binary_error: 0.504
[40] valid_0’s binary_error: 0.5072
[41] valid_0’s binary_error: 0.5076
[42] valid_0’s binary_error: 0.5076
[43] valid_0’s binary_error: 0.5064
[44] valid_0’s binary_error: 0.5048
[45] valid_0’s binary_error: 0.5044
[46] valid_0’s binary_error: 0.5048
[47] valid_0’s binary_error: 0.5058
[48] valid_0’s binary_error: 0.5042
[49] valid_0’s binary_error: 0.506
[50] valid_0’s binary_error: 0.5054
[51] valid_0’s binary_error: 0.505
[52] valid_0’s binary_error: 0.5056
[53] valid_0’s binary_error: 0.5048
[54] valid_0’s binary_error: 0.5048
[55] valid_0’s binary_error: 0.5038
[56] valid_0’s binary_error: 0.5034
[57] valid_0’s binary_error: 0.5062
[58] valid_0’s binary_error: 0.5072
[59] valid_0’s binary_error: 0.5058
[60] valid_0’s binary_error: 0.505
[61] valid_0’s binary_error: 0.5056
[62] valid_0’s binary_error: 0.5054
[63] valid_0’s binary_error: 0.5066
[64] valid_0’s binary_error: 0.5064
[65] valid_0’s binary_error: 0.5048
[66] valid_0’s binary_error: 0.503
[67] valid_0’s binary_error: 0.5026
[68] valid_0’s binary_error: 0.5008
[69] valid_0’s binary_error: 0.5014
[70] valid_0’s binary_error: 0.5026
[71] valid_0’s binary_error: 0.5024
[72] valid_0’s binary_error: 0.502
[73] valid_0’s binary_error: 0.5044
[74] valid_0’s binary_error: 0.5036
[75] valid_0’s binary_error: 0.5036
[76] valid_0’s binary_error: 0.5042
[77] valid_0’s binary_error: 0.5074
[78] valid_0’s binary_error: 0.5076
[79] valid_0’s binary_error: 0.5066
[80] valid_0’s binary_error: 0.506
[81] valid_0’s binary_error: 0.5062
[82] valid_0’s binary_error: 0.508
[83] valid_0’s binary_error: 0.5086
[84] valid_0’s binary_error: 0.5104
[85] valid_0’s binary_error: 0.5092
[86] valid_0’s binary_error: 0.5086
[87] valid_0’s binary_error: 0.5082
[88] valid_0’s binary_error: 0.5082
[89] valid_0’s binary_error: 0.5082
[90] valid_0’s binary_error: 0.5088
[91] valid_0’s binary_error: 0.506
[92] valid_0’s binary_error: 0.5062
[93] valid_0’s binary_error: 0.5064
[94] valid_0’s binary_error: 0.5066
[95] valid_0’s binary_error: 0.507
[96] valid_0’s binary_error: 0.5066
[97] valid_0’s binary_error: 0.5072
[98] valid_0’s binary_error: 0.5066
[99] valid_0’s binary_error: 0.5056
[100] valid_0’s binary_error: 0.5072
num_round = 10
param = {'num_leaves':50, 'num_trees':100, 'objective':'binary'}
lgb.cv(param, train_data, num_round, nfold=5)
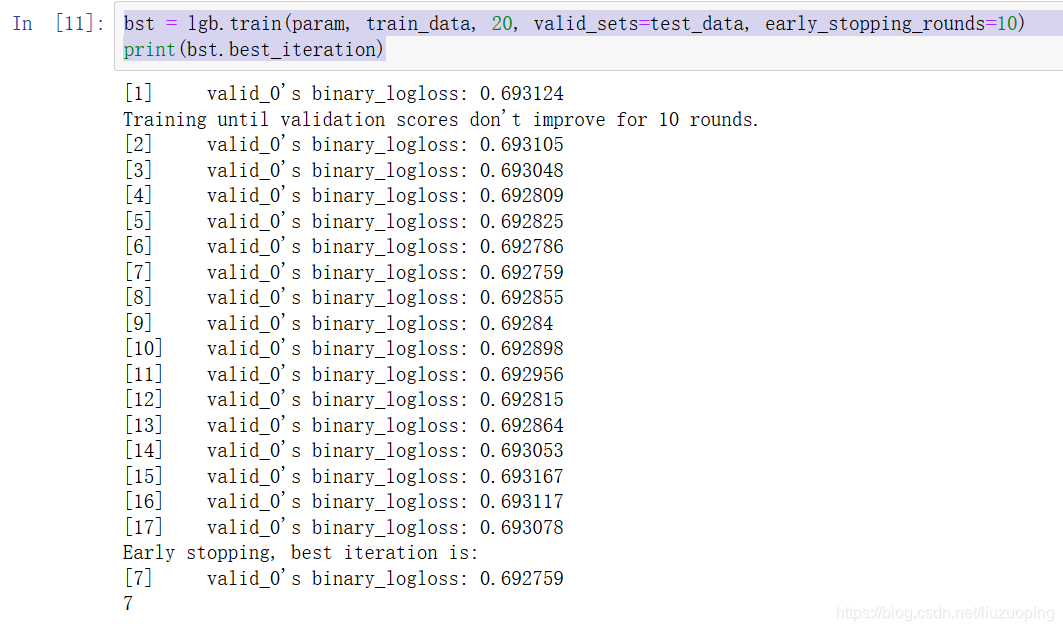
bst = lgb.train(param, train_data, 20, valid_sets=test_data, early_stopping_rounds=10)
print(bst.best_iteration)

















&spm=1001.2101.3001.5002&articleId=103335958&d=1&t=3&u=02a3a9edd57446c490fdf781abd312b0)
 2800
2800

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









