







 本文深入探讨脏数据的概念及表现形式,强调数据预处理在机器学习项目中的重要性,占比高达60%-70%。文章通过实例展示数据清洗过程,包括缺失值处理、文本数据清洗等关键步骤。
本文深入探讨脏数据的概念及表现形式,强调数据预处理在机器学习项目中的重要性,占比高达60%-70%。文章通过实例展示数据清洗过程,包括缺失值处理、文本数据清洗等关键步骤。
脏数据
脏数据可以理解为带有不整洁程度的原始数据。原始数据的整洁程度由数据采集质量所决定。
脏数据的表现形式五花八门,如若数据采集质量不过关,拿到的原始数据内容只有更差没有最差。
脏数据的表现形式包括:
- 数据串行,尤其是长文本情形下
- 数值变量种混有文本/格式混乱
- 各种符号乱入
- 数据记录错误
- 大段缺失(某种意义上不算脏数据)
数据采集完后拿到的原始数据到建模前的数据 ———— there is a long way to go.
从数据分析的角度上来讲,这个中间处理脏数据的数据预处理和清洗过程几乎占到了我们全部机器学习项目的60%-70%的时间。
总体而言就是 原始数据 -> 基础数据预处理/清洗 -> 探索性数据分析 -> 统计绘图/数据可视化 -> 特征工程
数据清洗与预处理基本方向
- 数据预处理没有特别固定的套路
- 数据预处理的困难程度与原始数据脏的程度而定
- 原始数据越脏,数据预处理工作越艰辛
- 数据预处理大的套路没有,小的套路一大堆
- 机器学习的数据预处理基于pandas来做
- 缺失值处理
- 小文本和字符串数据处理
- 法无定法,融会贯通
缺失值处理方法
- 删除:超过70%以上的缺失
- 填充
清洗过程模块化实战
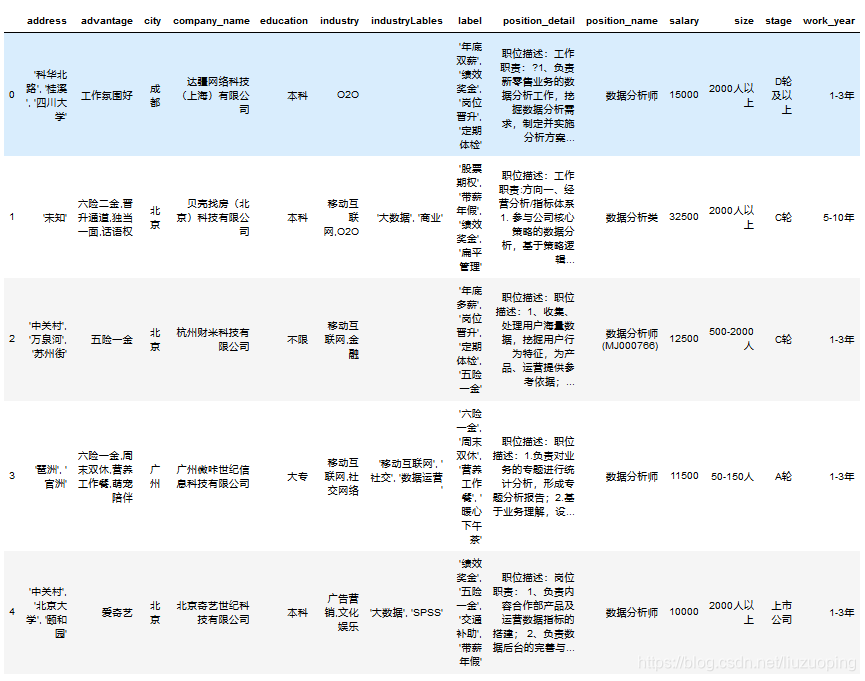
源数据分析
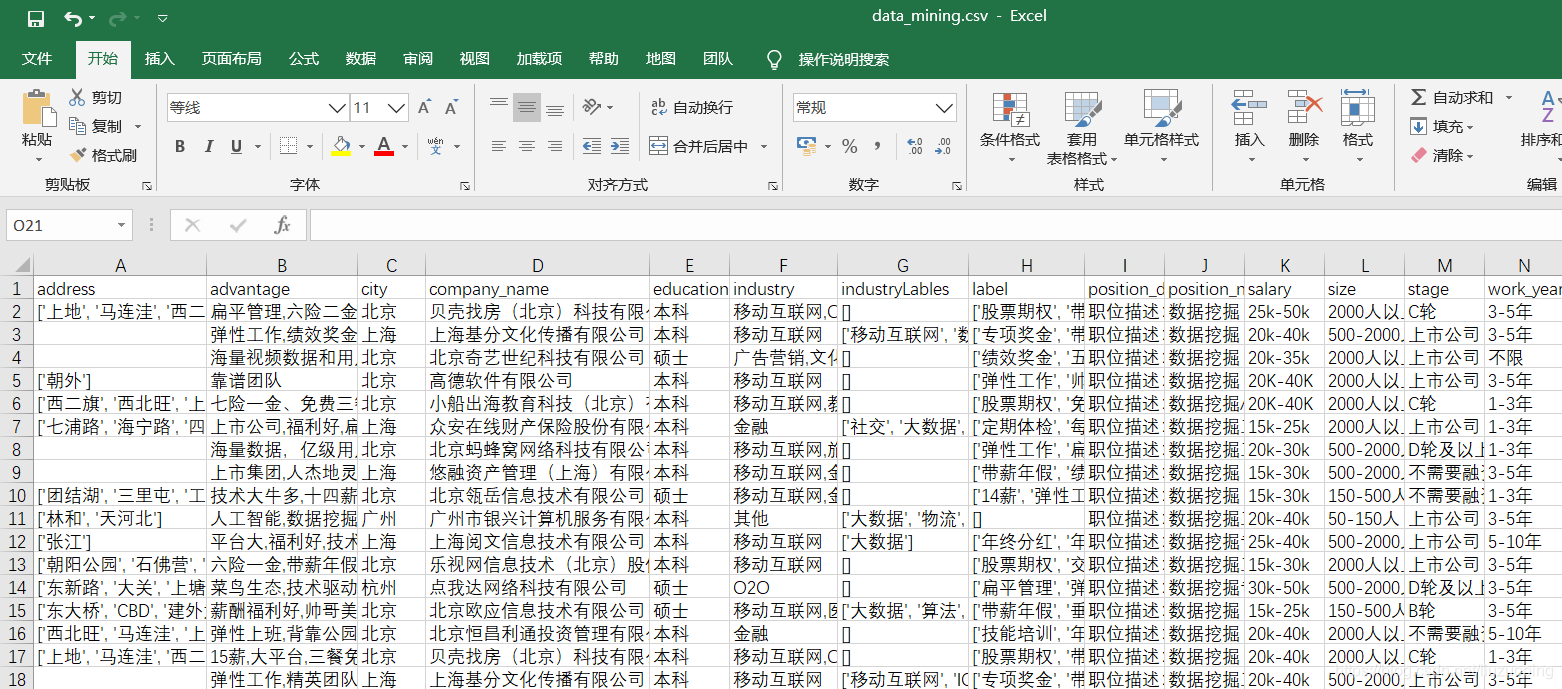
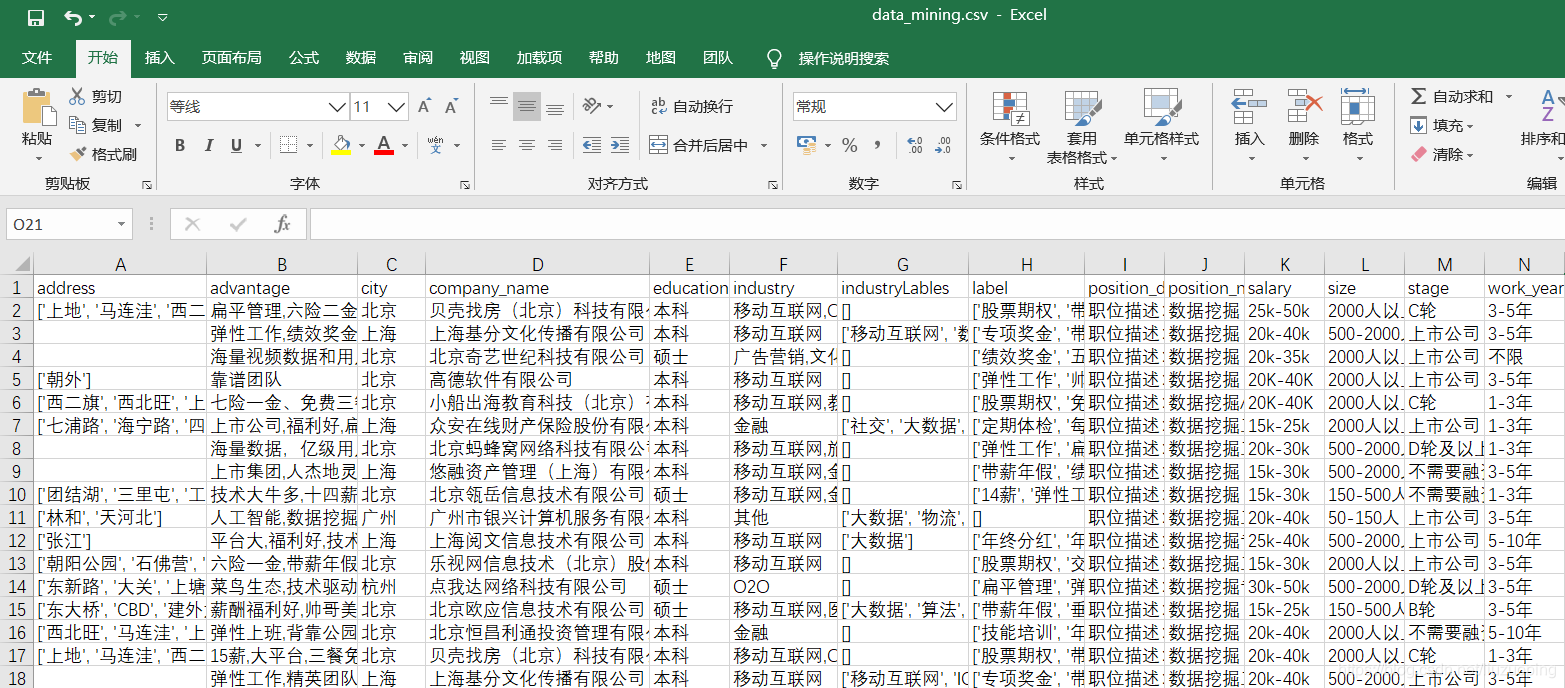
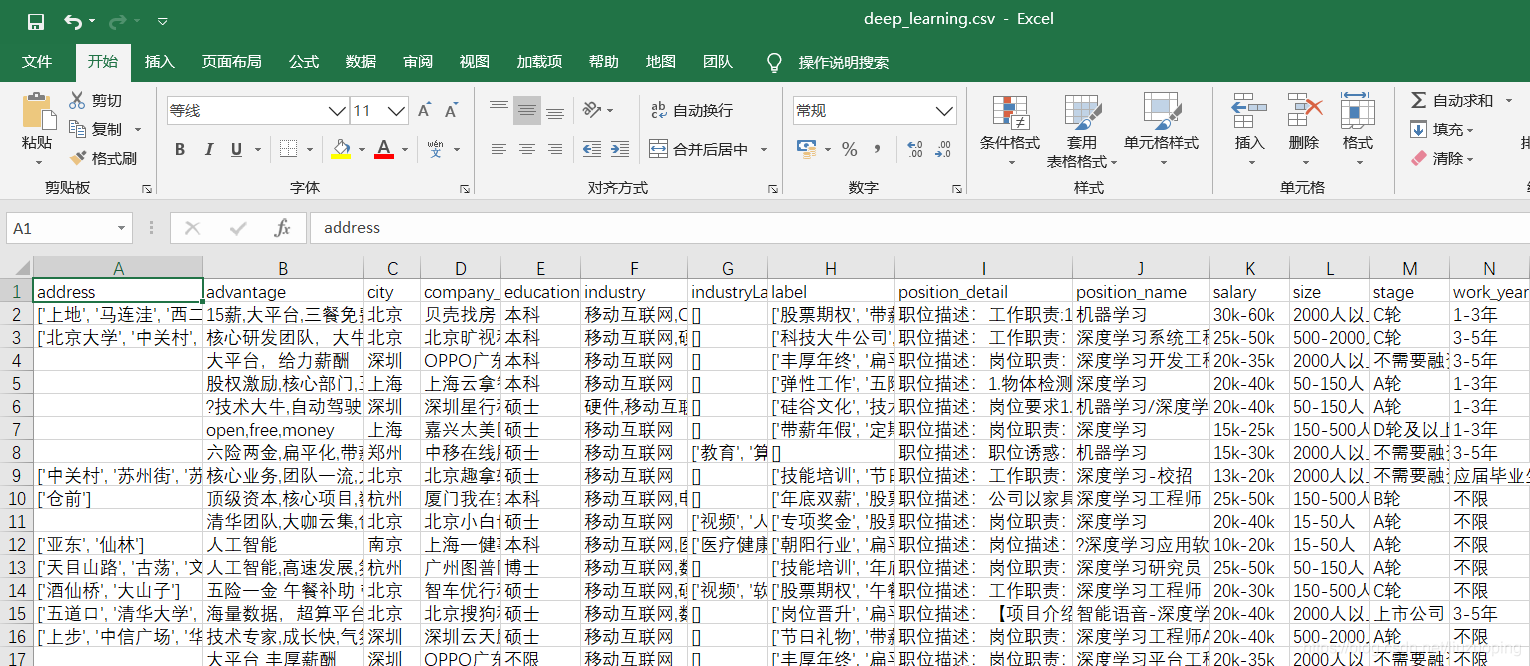
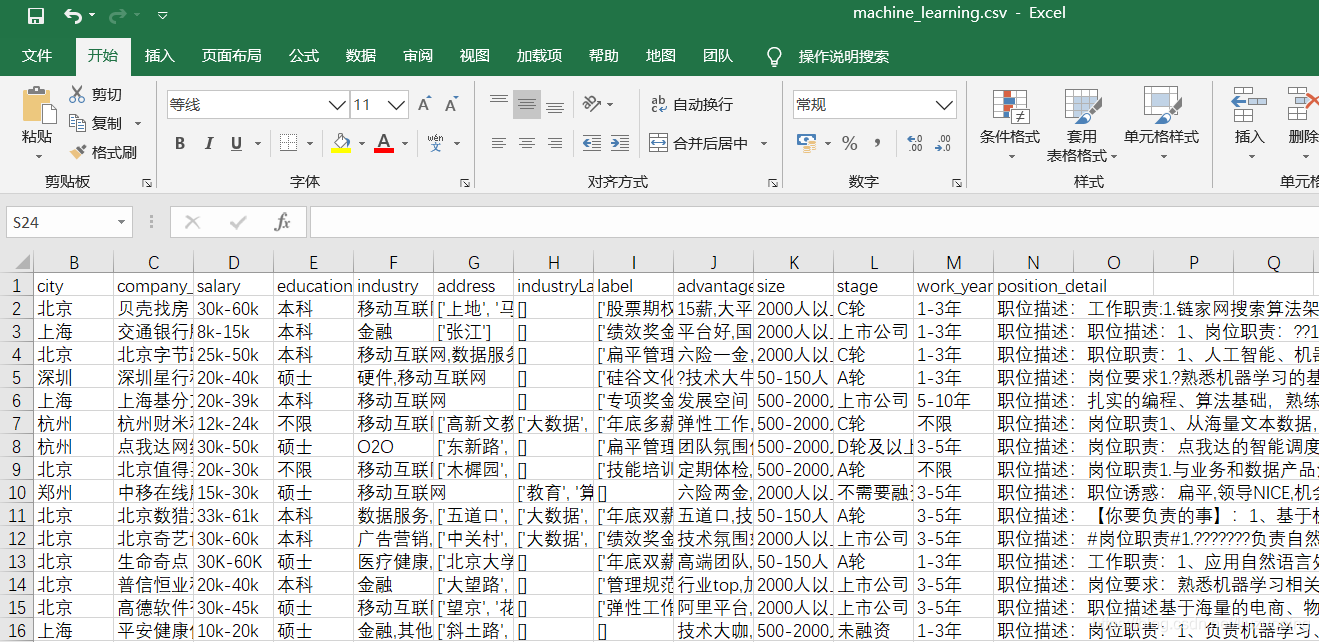
本次数据清洗的源数据是4个招聘信息的csv文件
具体源文件与代码获取可以访问我的GitHub地址
https://github.com/liuzuoping/MeachineLearning-Case
代码实战
import numpy as np
import pandas as pd
import string
import warnings
warnings.filterwarnings('ignore')
class data_clean(object):
def __init__(self):
pass
def get_data(self):
data1 = pd.read_csv('./data_analysis.csv', encoding='gbk')
data2 = pd.read_csv('./machine_learning.csv', encoding='gbk')
data3 = pd.read_csv('./data_mining.csv', encoding='gbk')
data4 = pd.read_csv('./deep_learning.csv', encoding='gbk')
data = pd.concat((pd.concat((pd.concat((data1, data2)), data3)), data4)).reset_index(drop=True)
return data
def clean_operation(self):
data = self.get_data()
data['address'] = data['address'].fillna("['未知']")
for i, j in enumerate(data['address']):
j = j.replace('[', '').replace(']', '')
data['address'][i] = j
for i, j in enumerate(data['salary']):
j = j.replace('k', '').replace('K', '').replace('以上', '-0')
j1 = int(j.split('-')[0])
j2 = int(j.split('-')[1])
j3 = 1/2 * (j1+j2)
data['salary'][i] = j3*1000
for i, j in enumerate(data['industryLables']):
j = j.replace('[', '').replace(']', '')
data['industryLables'][i] = j
for i, j in enumerate(data['label']):
j = j.replace('[', '').replace(']', '')
data['label'][i] = j
data['position_detail'] = data['position_detail'].fillna('未知')
for i, j in enumerate(data['position_detail']):
j = j.replace('\r', '')
data['position_detail'][i] = j
return data
opt = data_clean()
data = opt.clean_operation()
data.head()
运行结果

















 502
502

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









