






 本文深入分析JAVA Stream接口,讲解其作为AutoCloseable接口子类的特性。通过Spliterator接口的介绍,阐述IntConsumer的概念,并提供示例。文章还探讨了流的计算本质,不关注数据本身,而关注计算过程。同时,详细剖析了ReferencePipeline作为流源阶段和中间阶段的实现,以及Lambda表达式与匿名内部类的区别。在源码层面,展示了map和forEach等操作的实现细节。
本文深入分析JAVA Stream接口,讲解其作为AutoCloseable接口子类的特性。通过Spliterator接口的介绍,阐述IntConsumer的概念,并提供示例。文章还探讨了流的计算本质,不关注数据本身,而关注计算过程。同时,详细剖析了ReferencePipeline作为流源阶段和中间阶段的实现,以及Lambda表达式与匿名内部类的区别。在源码层面,展示了map和forEach等操作的实现细节。
- Stream接口继承自BaseStream继承了AutoCloseable接口
【补充】AutoCloseable接口说明:* <p>Streams have a {@link #close()} method and implement {@link AutoCloseable}, * but nearly all stream instances do not actually need to be closed after use. * Generally, only streams whose source is an IO channel (such as those returned * by {@link Files#lines(Path, Charset)}) will require closing. Most streams * are backed by collections, arrays, or generating functions, which require no * special resource management. (If a stream does require closing, it can be * declared as a resource in a {@code try}-with-resources statement.)public class AutoCloseableTest implements AutoCloseable{ // 测试AutoCloseable接口的用法:使用try with resources声明时 接口中的方法会被自动的调用 // 比如操作文件,IO流时都创建新的文件,IO流,使用try中创建新的对象(即 with resources), // 然后对文件内容或IO内容进行操作时就会自动调用close方法,以关闭资源 public void doSomething(){ System.out.println("do some things"); } public void close() throws Exception{ System.out.println("close invoked"); } public static void main(String[] args) throws Exception { try (AutoCloseableTest autoCloseable = new AutoCloseableTest()){ autoCloseable.doSomething();//输出:do some things close invoked } } @Test public void Test1(){ // 读BaseStream接口中onClose方法上面的说明文档。测试它的功能或作用: List<String> list = Arrays.asList("Hello","World","Hello world"); try(Stream<String> stream = list.stream() ){ stream.onClose(()-> { System.out.println("close"); throw new NullPointerException("first exception"); // throw NullPointerException; }).onClose(()-> { System.out.println("close1"); throw new NullPointerException("second exception"); // throw NullPointerException; }).forEach(System.out::println); } } } - JAVA DOC需要认真看。
- Spliterator接口介绍与源码分析
Spliterator接口中 public interface OfInt extends OfPrimitive<Integer, IntConsumer, OfInt> 接口的实现:* @apiNote * <p>Spliterators, like {@code Iterator}s, are for traversing the elements of * a source. The {@code Spliterator} API was designed to support efficient * parallel traversal in addition to sequential traversal, by supporting * decomposition as well as single-element iteration. In addition, the * protocol for accessing elements via a Spliterator is designed to impose * smaller per-element overhead than {@code Iterator}, and to avoid the inherent * race involved in having separate methods for {@code hasNext()} and * {@code next()}. //最后一句:Spliterator避免了在使用hasNext和next[他们总是连续使用,先用hasNext判断是否存在然后再next] //时当多个线程来操作时就可能会的出现问题; * <p>Primitive subtype specializations of {@code Spliterator} are provided for * {@link OfInt int}, {@link OfLong long}, and {@link OfDouble double} values. * The subtype default implementations of * The subtype default implementations of * {@link Spliterator#tryAdvance(java.util.function.Consumer)} * and {@link Spliterator#forEachRemaining(java.util.function.Consumer)} box * primitive values to instances of their corresponding wrapper class. Such * boxing may undermine any performance advantages gained by using the primitive * specializations. To avoid boxing, the corresponding primitive-based methods * should be used. For example, * {@link Spliterator.OfInt#tryAdvance(java.util.function.IntConsumer)} * and {@link Spliterator.OfInt#forEachRemaining(java.util.function.IntConsumer)} //提供了原始接口(primitive)的子类型(int lo0ng double)的特化接口: 避免了装箱与拆箱带来的性能损耗 * <p><a name="binding">A Spliterator that does not report {@code IMMUTABLE} or * {@code CONCURRENT} is expected to have a documented policy concerning: * when the spliterator <em>binds</em> to the element source; and detection of * structural interference of the element source detected after binding.</a> A * <em>late-binding</em> Spliterator binds to the source of elements at the * point of first traversal, first split, or first query for estimated size, * rather than at the time the Spliterator is created. A Spliterator that is * not <em>late-binding</em> binds to the source of elements at the point of * construction or first invocation of any method. Modifications made to the * source prior to binding are reflected when the Spliterator is traversed. * After binding a Spliterator should, on a best-effort basis, throw * {@link ConcurrentModificationException} if structural interference is * detected. Spliterators that do this are called <em>fail-fast</em>. The * bulk traversal method ({@link #forEachRemaining forEachRemaining()}) of a * Spliterator may optimize traversal and check for structural interference * after all elements have been traversed, rather than checking per-element and * failing immediately. //late-binding延迟绑定:分割迭代器绑定到元的元素上是在第一次遍历,分割或查询时, // 而不是分割迭代器被创建的时候非延迟绑定的分割迭代器绑定到源元素是在构造或调用方法时。 //fail-fast它是Java集合的一种错误检测机制,当多个线程对集合进行结构上的改变的操作时,有可能会产 生fail-fast机制。记住是有可能,而不是一定。例如:假设存在两个线程(线程1、线程2),线程1通过 Iterator在遍历集合A中的元素,在某个时候线程2修改了集合A的结构(是结构上面的修改,而不是简单的修改 集合元素的内容),那么这个时候程序就会抛出 ConcurrentModificationException 异常,从而产生fail-fast机制。 * <p>Structural interference of a source can be managed in the following ways * (in approximate order of decreasing desirability)://对源结构化的更改可通过下面几种方式管理: * <ul> * <li>The source cannot be structurally interfered with.//不可更改的 * <br>For example, an instance of * {@link java.util.concurrent.CopyOnWriteArrayList} is an immutable source. * A Spliterator created from the source reports a characteristic of * {@code IMMUTABLE}.</li> * <li>The source manages concurrent modifications.//并发修改 * <br>For example, a key set of a {@link java.util.concurrent.ConcurrentHashMap} * is a concurrent source. A Spliterator created from the source reports a * characteristic of {@code CONCURRENT}.</li> * <li>The mutable source provides a late-binding and fail-fast Spliterator. * //可变源提供延迟绑定和快速失败Spliterator * <br>Late binding narrows the window during which interference can affect * the calculation; fail-fast detects, on a best-effort basis, that structural * interference has occurred after traversal has commenced and throws * {@link ConcurrentModificationException}. For example, {@link ArrayList}, * and many other non-concurrent {@code Collection} classes in the JDK, provide * a late-binding, fail-fast spliterator.</li> * <li>The mutable source provides a non-late-binding but fail-fast Spliterator. * //可变源提供非延迟绑定和快速失败Spliterator * <br>The source increases the likelihood of throwing * {@code ConcurrentModificationException} since the window of potential * interference is larger.</li> * <li>The mutable source provides a late-binding and non-fail-fast Spliterator. * //可变源提供延迟绑定和非快速失败Spliterator * <br>The source risks arbitrary, non-deterministic behavior after traversal * has commenced since interference is not detected. * </li> * <li>The mutable source provides a non-late-binding and non-fail-fast * //可变源提供非延迟绑定和非快速失败Spliterator * Spliterator. * <br>The source increases the risk of arbitrary, non-deterministic behavior * since non-detected interference may occur after construction. * </li> * </ul> //java.util.concurrent.CopyOnWriteArrayList适用于读多写少的情形,当有写操作就拷贝一份集合进行 操作;一方面可以避免线程的同步操作,效率较高,不会出现加锁等不必要的性能损耗 * <p><b>Example.</b> Here is a class (not a very useful one, except * for illustration) that maintains an array in which the actual data * are held in even locations, and unrelated tag data are held in odd * locations. Its Spliterator ignores the tags. * * <pre> {@code * class TaggedArray<T> { * private final Object[] elements; // immutable after construction * TaggedArray(T[] data, Object[] tags) { * int size = data.length; * if (tags.length != size) throw new IllegalArgumentException(); * this.elements = new Object[2 * size]; * for (int i = 0, j = 0; i < size; ++i) { * elements[j++] = data[i]; * elements[j++] = tags[i]; * } * } * * public Spliterator<T> spliterator() { * return new TaggedArraySpliterator<>(elements, 0, elements.length); * } * * static class TaggedArraySpliterator<T> implements Spliterator<T> { * private final Object[] array; * private int origin; // current index, advanced on split or traversal * private final int fence; // one past the greatest index * * TaggedArraySpliterator(Object[] array, int origin, int fence) { * this.array = array; this.origin = origin; this.fence = fence; * } * //对于后面还没有完成遍历的元素完成遍历 * public void forEachRemaining(Consumer<? super T> action) { * for (; origin < fence; origin += 2) * action.accept((T) array[origin]); * } * //tryAdvance方法相当于完成了Iterator中hasNext方法及next方法 * public boolean tryAdvance(Consumer<? super T> action) { * if (origin < fence) { * action.accept((T) array[origin]); * origin += 2; * return true; * } * else // cannot advance * return false; * } * * public Spliterator<T> trySplit() { * int lo = origin; // divide range in half * int mid = ((lo + fence) >>> 1) & ~1; // force midpoint to be even * if (lo < mid) { // split out left half * origin = mid; // reset this Spliterator's origin * return new TaggedArraySpliterator<>(array, lo, mid); * } * else // too small to split * return null; * } * * public long estimateSize() { * return (long)((fence - origin) / 2); * } * * public int characteristics() { * return ORDERED | SIZED | IMMUTABLE | SUBSIZED; * } * } * }}</pre> *@Override boolean tryAdvance(IntConsumer action); /** * {@inheritDoc} * @implSpec * If the action is an instance of {@code IntConsumer} then it is cast * to {@code IntConsumer} and passed to * {@link #tryAdvance(java.util.function.IntConsumer)}; otherwise * the action is adapted to an instance of {@code IntConsumer}, by * boxing the argument of {@code IntConsumer}, and then passed to * {@link #tryAdvance(java.util.function.IntConsumer)}. */ @Override default boolean tryAdvance(Consumer<? super Integer> action) { //action是Consumer函数式接口类型的,如何是IntConsumer函数式接口类型的, // 从接口声明来看,Consumer接口类型与IntConsumer接口类型没有继承关系 //如果action中传入参数式Integer类型,则既符合Consumer<? super Integer> // 又符合IntConsumer,(系统给int与Integer之间会自动装箱和自动拆箱) //对于Lambda表达式(匿名的参数自动判断的)所有信息都是通过上下文推断出来 if (action instanceof IntConsumer) { return tryAdvance((IntConsumer) action); } else { if (Tripwire.ENABLED) Tripwire.trip(getClass(), "{0} calling Spliterator.OfInt.tryAdvance((IntConsumer) action::accept)"); return tryAdvance((IntConsumer) action::accept); } }其中解释Consumer与IntConsumer的具体示例如下程序:
public class ConsumerOrintConsumerTest { public void compute(Consumer<Integer> consumer){ consumer.accept(100); } @Test public void Test(){ Consumer<Integer> consumer = i-> System.out.println(i); IntConsumer intConsumer = i-> System.out.println(i); compute(consumer);//面向对象方式:传递对象 // compute(intConsumer);//编译报错:intConsumer与Consumer类型无关 compute(consumer::accept);//函数式方式:传递的是行为 compute(intConsumer::accept);//不报错,输出正常 } }流关心的是计算本身,不关心数据。流的源阶段和中间阶段本身不持有数据,数据是由集合持有的。
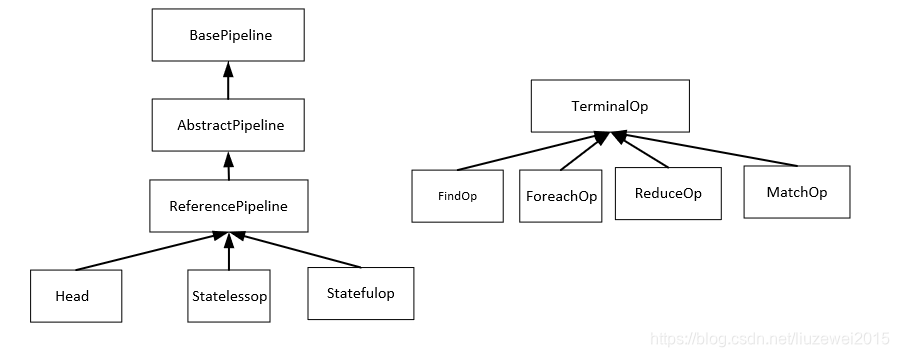
- ReferencePipeline表示流的源阶段与中间阶段;ReferencePipeline.head是一个静态内部类,且继承自ReferencePipeline,表示流的源阶段; 二者在大部分属性设计上都是类似的,但存在一些属性是不同的。Pipeline可以看作是一个双向链表。
Abstractpipeline中的注释文档中的:说明 * <p>For sequential streams, and parallel streams without * <a href="package-summary.html#StreamOps">stateful intermediate * operations</a>, parallel streams, pipeline evaluation is done in a single * pass that "jams" all the operations together. For parallel streams with * stateful operations, execution is divided into segments, where each * stateful operations marks the end of a segment, and each segment is * evaluated separately and the result used as the input to the next * segment. In all cases, the source data is not consumed until a terminal * operation begins. //管道计算对每一个流元素是在一趟过程中完成,这一趟过程会将所有操作放到一起完成; //(操作也涉及流的短路,其指不满足第一个中间操作时便不再执行后面的操作) //源数据不会被消费直到开始一个终止操作。 - Lambda表达式与匿名内部类本质上是不同的东西:只是完成相同的功能:
public class LambdaTest { //匿名内部类与Lambda表达式的不同 Runnable r1 = ()-> System.out.println(this); Runnable r2 = new Runnable() { @Override public void run() { System.out.println(this); } }; @Test public void Test1(){ Thread t1 = new Thread(r1); t1.start(); //com.learn.jdk8.LambdaTest@8b124ba //上面this表示当前类的对象 System.out.println("------------"); Thread t2 = new Thread(r2); t2.start(); //com.learn.jdk8.LambdaTest$1@5523f34f 中com.learn.jdk8.LambdaTest$1表示当前对象 //5523f34f为一个hash值;名称表示第一个匿名内部类;生成的是LambdaTest$1.class字节码文件 //即上面this表示匿名内部类的对象:开辟了一个新的作用域 } } - 中间操作仅仅返回了StatelessOp对象,做了一些赋值等操作,没有执行里面的实现:如map源码:
public final <R> Stream<R> map(Function<? super P_OUT, ? extends R> mapper) { Objects.requireNonNull(mapper); //完成一些赋值 return new StatelessOp<P_OUT, R>(this, StreamShape.REFERENCE, StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT) { @Override Sink<P_OUT> opWrapSink(int flags, Sink<R> sink) { return new Sink.ChainedReference<P_OUT, R>(sink) { @Override public void accept(P_OUT u) { downstream.accept(mapper.apply(u)); } }; } }; } /** * Construct a new Stream by appending a stateless intermediate * operation to an existing stream. * * @param upstream The upstream pipeline stage * @param inputShape The stream shape for the upstream pipeline stage * @param opFlags Operation flags for the new stage */ StatelessOp(AbstractPipeline<?, E_IN, ?> upstream, StreamShape inputShape, int opFlags) { super(upstream, opFlags); assert upstream.getOutputShape() == inputShape; } //其中super(upstream, opFlags): ReferencePipeline(AbstractPipeline<?, P_IN, ?> upstream, int opFlags) { super(upstream, opFlags); } //其中super(upstream, opFlags):一些赋值等操作 AbstractPipeline(AbstractPipeline<?, E_IN, ?> previousStage, int opFlags) { if (previousStage.linkedOrConsumed) throw new IllegalStateException(MSG_STREAM_LINKED); previousStage.linkedOrConsumed = true; previousStage.nextStage = this; this.previousStage = previousStage; this.sourceOrOpFlags = opFlags & StreamOpFlag.OP_MASK; this.combinedFlags = StreamOpFlag.combineOpFlags(opFlags, previousStage.combinedFlags); this.sourceStage = previousStage.sourceStage; if (opIsStateful()) sourceStage.sourceAnyStateful = true; this.depth = previousStage.depth + 1; } //opWrapSink方法的实现 * Accepts a {@code Sink} which will receive the results of this operation, * and return a {@code Sink} which accepts elements of the input type of * this operation and which performs the operation, passing the results to * the provided {@code Sink}. abstract Sink<E_IN> opWrapSink(int flags, Sink<E_OUT> sink); - 对于foreach则是终止操作:
// Terminal operations from Stream @Override public void forEach(Consumer<? super P_OUT> action) { evaluate(ForEachOps.makeRef(action, false)); } //ForEachOps类: * Factory for creating instances of {@code TerminalOp} that perform an * action for every element of a stream. Supported variants include unordered * traversal (elements are provided to the {@code Consumer} as soon as they are * available), and ordered traversal (elements are provided to the * {@code Consumer} in encounter order.) //其中makeRef: * Constructs a {@code TerminalOp} that perform an action for every element * of a stream. public static <T> TerminalOp<T, Void> makeRef(Consumer<? super T> action, boolean ordered) { Objects.requireNonNull(action); return new ForEachOp.OfRef<>(action, ordered); } //evaluate:完成终止操作,返回结果 //Evaluate the pipeline with a terminal operation to produce a result. final <R> R evaluate(TerminalOp<E_OUT, R> terminalOp) { assert getOutputShape() == terminalOp.inputShape(); if (linkedOrConsumed) throw new IllegalStateException(MSG_STREAM_LINKED); linkedOrConsumed = true; return isParallel() ? terminalOp.evaluateParallel(this, sourceSpliterator(terminalOp.getOpFlags())) : terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags())); } //terminalOp.evaluateSequential(于TerminalOp接口中)在forEachOps中的实现: @Override public <S> Void evaluateSequential(PipelineHelper<T> helper, Spliterator<S> spliterator) { return helper.wrapAndCopyInto(this, spliterator).get(); } //wrapAndCopyInto(于PipelineHelper接口中)在AbstractPipeline中的实现: @Override final <P_IN, S extends Sink<E_OUT>> S wrapAndCopyInto(S sink, Spliterator<P_IN> spliterator) { copyInto(wrapSink(Objects.requireNonNull(sink)), spliterator); return sink; } ////////////其中wrapSink方法的实现: @Override @SuppressWarnings("unchecked") final <P_IN> Sink<P_IN> wrapSink(Sink<E_OUT> sink) { Objects.requireNonNull(sink); for ( @SuppressWarnings("rawtypes") AbstractPipeline p=AbstractPipeline.this; p.depth > 0; p=p.previousStage) { sink = p.opWrapSink(p.previousStage.combinedFlags, sink);/////p.opWrapSink //从后一个sink往前不断的链接 } return (Sink<P_IN>) sink; } /////////////而在其中opWrapSink方法的实现则在map源码中(见上一个源码分析)实现的。 /** * Pushes elements obtained from the {@code Spliterator} into the provided * {@code Sink}. If the stream pipeline is known to have short-circuiting * stages in it (see {@link StreamOpFlag#SHORT_CIRCUIT}), the * {@link Sink#cancellationRequested()} is checked after each * element, stopping if cancellation is requested. * * @implSpec * This method conforms to the {@code Sink} protocol of calling * {@code Sink.begin} before pushing elements, via {@code Sink.accept}, and * calling {@code Sink.end} after all elements have been pushed. * */ abstract<P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator); //copyInto的具体实现: @Override final <P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator) { Objects.requireNonNull(wrappedSink); if (!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags())) { wrappedSink.begin(spliterator.getExactSizeIfKnown()); spliterator.forEachRemaining(wrappedSink); //多个中间操作及一个终止操作(封装为了wrappedSink), //最终操作就是通过这个方法来完成的 wrappedSink.end(); } else { copyIntoWithCancel(wrappedSink, spliterator); } } - 断点调试分析:$3表示ReferencePipeline类中第三个StatelessOp匿名内部类(见map源码)。
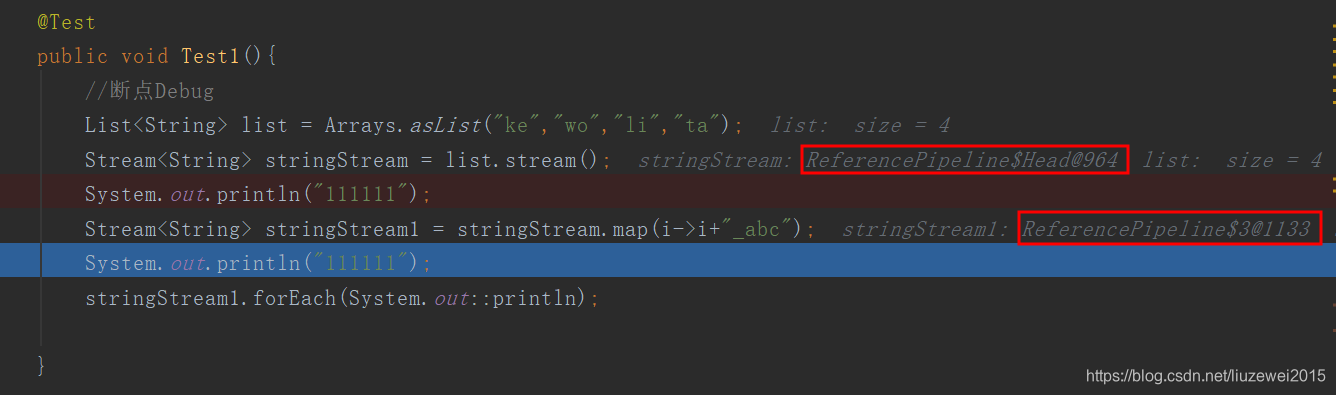

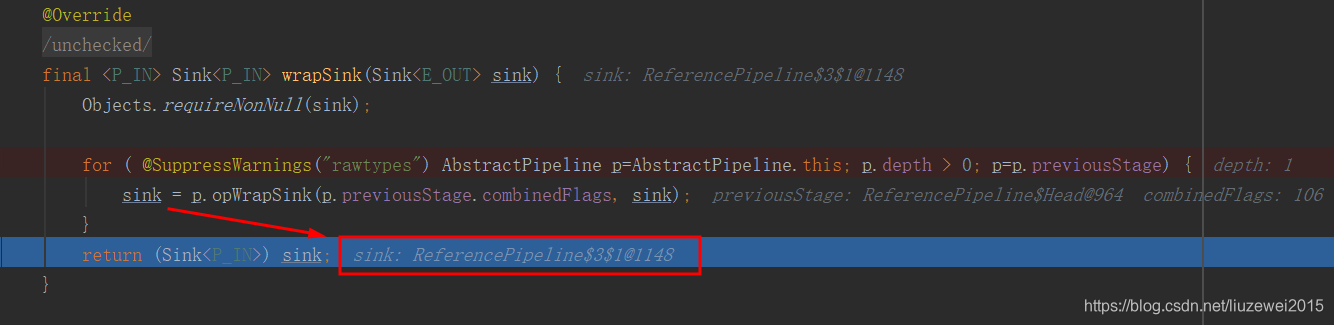
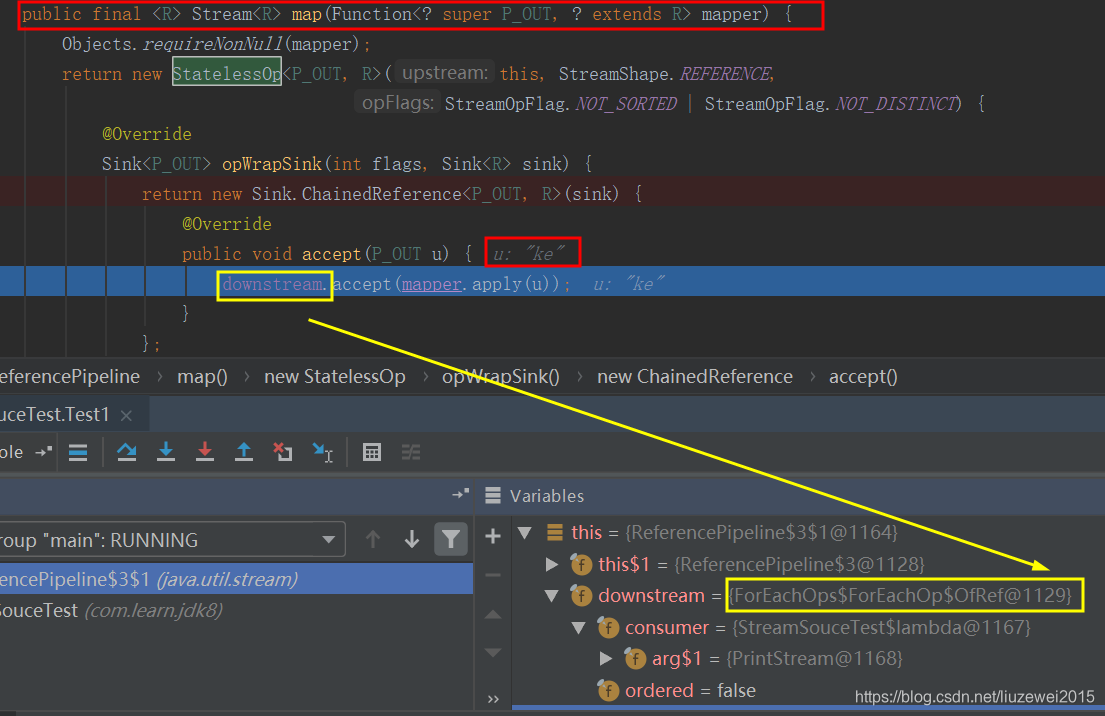
- 层次关系
JAVA新特性(7)Stream接口源码分析
最新推荐文章于 2024-03-15 01:39:30 发布


















 593
593

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









