







一. 正则表达式
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。
构造正则表达式的方法和创建数学表达式的方法一样。也就是用多种元字符与运算符可以将小的表达式结合在一起来创建更大的表达式。正则表达式的组件可以是单个的字符、字符集合、字符范围、字符间的选择或者所有这些组件的任意组合。
正则表达式是由普通字符(例如字符 a 到 z)以及特殊字符(称为"元字符")组成的文字模式。模式描述在搜索文本时要匹配的一个或多个字符串。正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。
二.常用的正则规则
1.字符
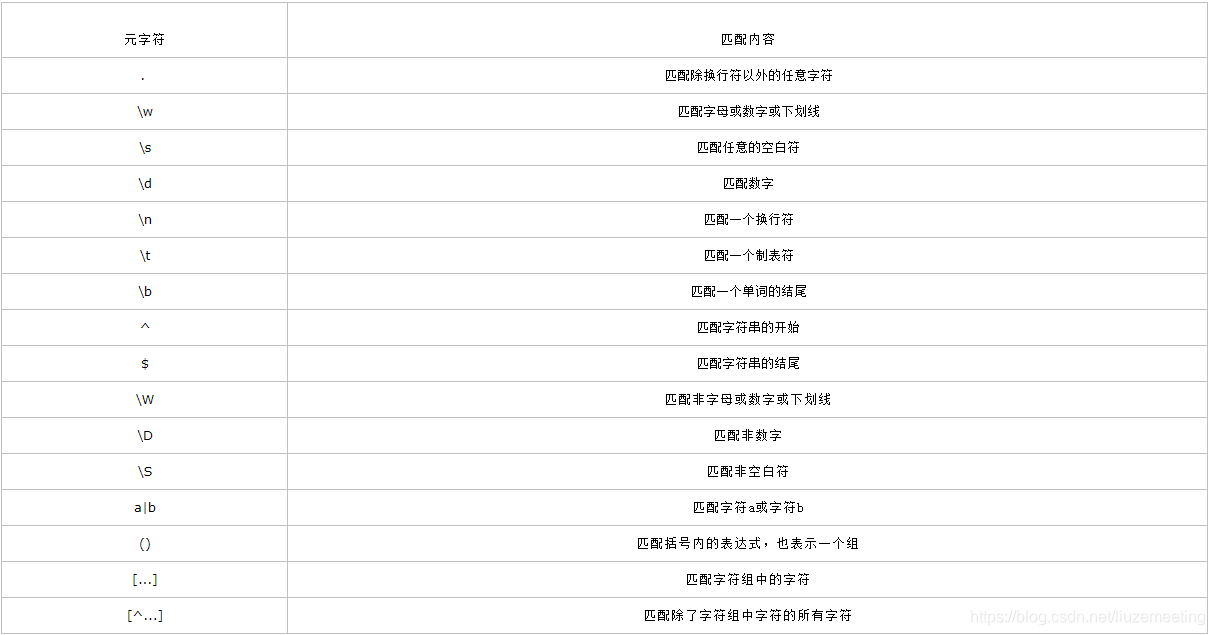
2.量词

三.python re模块常用一些规则详解
1.re常用的一些方法
match: 从头开始匹配 一旦匹配失败就返回None
search: 在整个字符串进行匹配
共同点: 1、只对字符串查询一次 2 返回值都是 re.match对象
finditer: 返回可迭代对象 查找所有匹配数据放到一个可迭代对象
findall: 将所有查找到的字符串的列表放到一个列表里
fullmatch: 完整匹配 字符串需要完全满足规则
注: 调用 re.match re.search 或者对re.finditer 结果进行遍历 结果都是re.match对象
四.一些函数方法使用的示例
1.获取到research匹配字符串的结果
data_str = "qwert12yui3o5p6a7d8fkglctsdfstg"
p1 = re.search(r'2.*3.*5.*7.*8', data_str)
# 获取到匹配字符串的结果
# 用group表示正则表达式的分组
# 如果没有分组 默认只有一组
# 分组下表从0开始
p2 = re.search(r'(2.*)3.*5.*(7.*8)', data_str)
# 在正则表达式中使用()表示一个分组
# (?P<name> 表达式) 可以给分组起名字
p3 = re.search(r'(?P<name>2.*)3.*5.*(7.*8)', data_str)
2.同一个规则匹配不同字符串
data_str = "qazxs13wedc12cdews12123\nxzaq12313"
r = re.compile(r'.*e')
print(r.search(data_str))
3.正则修饰符
# 正则表达式规则
# 数字和字母表示本事
# 很多字母前面添加 \ 会有特殊含义
# 绝大多数标点符号都有特殊含义
# 如果想要使用标点符号需要加\
print(re.search(r'x', "hello xyz"))
print(re.search(r'5', "dst56"))
print(re.search(r'\d', "dsdfs242"))
print(re.search(r'\+', "ddd+++"))
# \s表示任意非打印字符
print(re.search(r'\s', "hello \sworld "), "ffffff")
# \n表示换行
print(re.search(r'\n', "hello \nnworld "), "ffffff")
# \t 制表符
x = "hello world"
print(re.search(r'\s', x)) # 空格
# # 特殊字符
# # () 用来表示一个分组
# . 表示除了换行以外的任意字符 如果想要匹配 需要使用、\.
print(re.search(r'h(\d+)x', "dddsdh43xfad"))
print(re.search(r'(.*)', '(1+1)*3+5'))
print(re.search(r'\(.*\)', '(1+1)*3+5'))
4.区间可选项
# [] 用来表示区间可选项 [x-y]从x到y区间 包含x和y [0-9]从1-9
m2 = re.search(r'f[0-9]+m', 'fmf421513453m')
m3 = re.search(r'f[a-z]m', 'f5mfgm')
# 或者关系 0<value<1 或者a<value<d 或者value=x
m4 = re.search(r'f[0-1a-dx]+m', 'fmf421513453mafsfdm')
print(m2)
# | 表示或者 和[]区别 []里面表示的是区间 |中间表示可选值
m2 = re.search(r'f(x|v|d)m', 'fvmf421513453mafsfdm')
5.用来规定出现的次数
# {}用来规定出现的次数 {n,}表示n次以上 {, n} 表示前面出现n次及n次以下 {m, n}表示出现次数m到n次
m3 = re.search(r'o{2,}', "goooooood")
print(m3)
# * 表示前面的元素出现任意次数(0) 次以上 + 表示前面元素至少出现一次 等价于{1, }
m4 = re.search(r'go*d', "goooood")
print(m4)
m5 = re.search(r'go+d', "goooood")
print(m5)
6.贪婪模式与非贪婪模式
在python的匹配中默认是贪婪模式 尽可能多的匹配 添加?可将贪婪模式转化为非贪婪模式 尽可能少的匹配
# 只匹配到aa2
print(re.search(r'aa\d+?', "aa2233ddd"))
# 能够匹配到aa2233
print(re.search(r'aa\d+', "aa2233ddd"))
#因为后面有ddd所以会将数字全部匹配
print(re.search(r'aa(\d+?)ddd', "aa2233ddd"))
print(re.search(r'aa(\d+)ddd', "aa2233ddd"))
五.一些常用的匹配规则
1.判断用户输入内容是否是数字,如果是数字 则转换成数据类型
re.fullmatch(r'\d+(\.?\d+)?', num)
2.以非数字开头,后面偶字母数字_ 组成的长度4到14位的字符串
re.search(r'^\D[a-zA-Z_\-]{4, 13}', data)
3.手机号匹配
re.fullmatch(r'^((13[0,5-9])|(15[0-9]))[0-9]{8}$', data)
4.身份证号匹配
re.fullmatch(r'^[1-9]\d{5}(18|19|20|21)\d{2}(([0-2][1-9])|10|11|12)(([0-2][1-9])|10|20|30|31)\d{3}[0-9X]', data)
5.车牌号匹配
re.fullmatch(r'^[京豫警军A-Z][A-Z][A-Z0-9]{4}[A-Z0-9挂学警]', data)

















 116
116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









