






 本文详细介绍了DjangoORM中的聚合查询,包括Max、Min、Sum、Count和Avg等函数的使用。接着讲解了分组查询,通过annotate和values方法实现数据分组和统计。此外,还探讨了F查询和Q查询,包括它们在字段运算和逻辑组合中的应用。文章还提到了事务的ACID特性,并展示了如何在Django中开启和使用事务。最后,讨论了ORM中的常用字段类型和参数,以及数据库查询优化技巧,如only、defer、select_related和prefetch_related的用法。
本文详细介绍了DjangoORM中的聚合查询,包括Max、Min、Sum、Count和Avg等函数的使用。接着讲解了分组查询,通过annotate和values方法实现数据分组和统计。此外,还探讨了F查询和Q查询,包括它们在字段运算和逻辑组合中的应用。文章还提到了事务的ACID特性,并展示了如何在Django中开启和使用事务。最后,讨论了ORM中的常用字段类型和参数,以及数据库查询优化技巧,如only、defer、select_related和prefetch_related的用法。
Django-7:django模型层ORM-3
ORM-3
一、聚合查询
作用:
- 通过模块内置的方法,可以做到将数据的值进行处理,得到平均值、最大值、最小值等等。
格式:
-
''' 1.导入模块 2.函数名:aggregate 3.选用需要的聚合查询函数。 ''' from app01 import models from django.db.models import Avg # 所有书的平均价格 res = models.Book.objects.aggregate(Avg('price')) print(res) """ 输出结果示例: {'price__avg': 290.6316667} """
附:
-
聚合查询通常情况下都是配合分组一起使用的(分组在下一节)
-
只要是跟数据库相关的模块,基本上都在django.db.models里面,如果上述没有那么应该在django.db里面,如聚合查询函数
from django.db.models import Max,Min,Sum,Count,Avg
1.1 常用的聚合查询函数
汇总一览:
| 函数名/格式 | 作用 |
|---|---|
| Max(‘字段名’) | 计算字段名对应值中,最大的是哪个。 |
| Min(‘字段名’) | 计算字段名对应值中,最小的是哪个。 |
| Sum(‘字段名’) | 计算字段名对应值的总和。 |
| Count(‘字段名’) | 计算该字段名对应值的总个数(统计有多少数据对象有该字段)。 |
| Avg(‘字段名’) | 计算该字段名对应值的平均值。 |
代码示例:(test.py文件)
import os
if __name__ == "__main__":
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "djangoProject.settings")
import django
from app01 import models
from django.db.models import Max,Min,Sum,Count,Avg
res = models.Book.objects.aggregate(Max('price'),Min('price'),Sum('price'),Count('pk'),Avg('price'))
print(res)
#输出结果示例:
{'price__max': Decimal('521.000'), 'price__min': Decimal('46.000'), 'price__sum': Decimal('1743.790'), 'pk__count': 6, 'price__avg': 290.6316667}
二、分组查询
常用格式:
-
.annotate(别名=聚合函数())
案例-1:统计每一本书的作者个数
data_queryset = models.Book.objects.annotate(author_num=Count('authors__pk'))
print(data_queryset)
res = data_queryset.values('title','author_num')
print(res)
'''
输出结果:
<QuerySet [<Book: Book object>, <Book: Book object>, <Book: Book object>, <Book: Book object>]>
<QuerySet [{'title': '《水浒传》', 'author_num': 2}, {'title': '《红楼梦》', 'author_num': 2}, {'title': '《西游记》', 'author_num': 1},.......]>
'''
-
通过给书籍分组来查询每个书籍对象所拥有的作者个数。
-
Count(‘authors__pk’)计算出来的作者个数,由 author_num变量所接收,随后以属性的形式存入书籍数据对象中,验证:
data_queryset = models.Book.objects.annotate(author_num=Count('bing_authors__pk')) get_bool = hasattr(data_queryset.first(), 'author_num') print(get_bool) ''' 输出结果: True '''由此说明书籍数据对象,是存在author_num属性的,所以后续可以使用values(‘title’,‘author_num’)进行展示书名及作者个数。
案例-2:统计每个出版社卖的最便宜的书的价格
- 由于是反向查询,所以是表名小写。
res = models.Publish.objects.annotate(min_price = Min('book__price')).values('name','min_price')
print(res)
'''输出结果:
<QuerySet [{'name': '《人民文学出版社》', 'min_price': Decimal('49.90')}, {'name': '《作家出版社》', 'min_price': Decimal('39.90')}, ........]>
'''
案例-3:统计作者为一个以上的图书
- 给图书分组,先拿到每个图书有多少个作者。
- 随后再进行“__”双下方法和filter进行过滤。
data_query = models.Book.objects.annotate(authors_num = Count('bing_authors__pk')).filter(authors_num__gt = 1)
res = data_query.values('title','authors_num')
print(res)
'''输出结果:
<QuerySet [{'title': '《水浒传》', 'authors_num': 2}, {'title': '《红楼梦》', 'authors_num': 2}]>
'''
案例-4:统计每个作者出的书的总价格
res = models.Author.objects.annotate(all_book_price=Sum('book__price')).values('name','all_book_price')
print(res)
三、F与Q查询
3.1 F查询
本章案例的数据表如下:
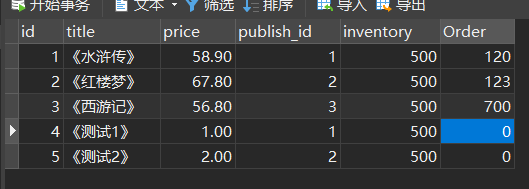
该表为下列案例中进行查询的表,内有书名字段、价格字段、出版社外键、库存字段、订单字段。
案例-1:查询订单数大于库存量的书籍
# 引入
from django.db.models import F
res = models.Book.objects.filter(Order__gt = F('inventory'))
print(res.first().title)
- 在没有F查询的时候,我们只能利用双下方法查询到订单大于等于某一个具体值的数据,而我们现在需要将订单值与库存值进行对比,这两个值都需要进行查询。
- F查询的出现,就可以很好的帮助我们直接获取到表中的某个字段对应的数据,随后作为数据对比的依据(可以跨表),如该案例中,用订单字段的值与库存字段的值进行比较。
案例-2:将订单数大于库存量的书籍,在title处加上“无货”二字
"""
在操作字符类型的数据的时候 F不能够直接做到字符串的拼接
需要借助Concat模块、Value模块
"""
from django.db.models.functions import Concat
from django.db.models import Value
# update(title=F('title') + '无货') # 这样写之后,所有的名称会全部变成空白。
models.Book.objects.filter(Order__gt=F('inventory')).update(title=Concat(F('title'),Value('无货')))
-
Concat用法:Concat(F(‘虚拟字段或表名’),Value(‘拼接的内容’))
所以代码中的意思就是,将通过F查询得到的数据,与Value函数中的数据进行拼接,随后赋值给title字段,update更新数据库。
案例-3:将订单数大于100的书籍,在title处加上“爆款”两个字。
models.Book.objects.filter(Order__gt=100,Order__lt=F('inventory')).update(title=Concat(F('title'),Value('爆款')))
- 订单大于100,但是还要保证订单不能超过库存。
- 随后通过Concat函数对F查询到的数据进行拼接,最后赋值给title字段并更新。
案例-4:临近双12,现将所有书籍的价格打8折。
-
models.py新增一个字段为活动价
activity_price = models.DecimalField(max_digits=8,decimal_places=2,verbose_name='activity_price',default=0)
代码示例:
models.Book.objects.update(activity_price=F('price')*0.8)
- F查询可以直接做数据运算,当涉及到字符串拼接时,就需要用到Concat和Value
3.2 Q查询
作用:
-
Q查询可以实现or关系和not关系,而普通的filter查询为and关系
res = models.Book.objects.filter(inventory__gt=300,order__gte=400).values('title') print(res) ''' filter为and的关系,上述代码为查询库存数大于300,并且订单数大于等于400的书籍。 '''
Q查询的格式:
-
and:Q查询当使用逗号分割时,还是and关系。
-
or:当使用“|”号分割时,为or关系。
-
not:当使用“~”号分割时,为or关系。
models.表.objects.filter(Q(条件1) , Q(条件2)) # and models.表.objects.filter(Q(条件1) | Q(条件2)) # or models.表.objects.filter(~Q(条件1) | Q(条件2), Q(条件3).....)
案例-1:查询订单大于500,或者单价小于10的书籍
# 引入
from django.db.models import Q
models.Book.objects.filter(Q(Order__gt=500) | Q(price__lt=10))
- 或者的关系,也就是or,所以要使用“|”号。
案例-2:查询库存数不大于300,且订单数也小于100的书籍
res = models.Book.objects.filter(~Q(inventory__gt=300),Q(order__gte=100)).values('title')
print(res)
- 不大于,也就是小于,可以直接使用__lt,也可以使用“~”号。
- 且,为and关系,所以后续的条件用逗号隔开。
3.2.1 Q高阶用法—BBS项目补充
2.Q的高阶用法 能够将查询条件的左边也变成字符串的形式
'''
上面的案例都有一个共同点,price__gt=50,在这当中price为库中的字段名,并不能作为字符串登场。
而Q的高级用法就是将,查询条件的左边也变成字符串的形式。
随后可以通过用户输入的内容作为条件进行查询。
'''
q = Q()
#q.connector = 'or' 可改成or关系,默认为and
list1 = ['price__gt','50'] # 价格大于50
list2 = ['price__lt','60'] # 价格小于60
q.children.append((list1[0],list1[1])) #双括号
q.children.append((list2[0],list2[1]))
res = models.Book.objects.filter(q)
for i in res:
print(i.title)
四、django中如何开启事务
事务的作用::
- 保证了对数据操作的安全性
事务的四大特性(ACID):
-
原子性:
一个事务是一个不可分割的单位,事务中包含的诸多操作,要么同时成功要么同时失败。
-
一致性:
事务必须是使数据库从一个一致性的状态变到另外一个一致性的状态,一致性跟原子性是密切相关的。
-
隔离性
一个事务的执行不能被其他事务干扰。
(即一个事务内部的操作及使用到的数据对并发的其他事务是隔离的,并发执行的事务之间也是互相不干扰的)
-
持久性
也叫"永久性",一个事务一旦提交成功执行成功,那么它对数据库中数据的修改应该是永久的,接下来的其他操作或者故障不应该对其有任何的影响。
总结:
- 当想让多条sql语句保持一致性,要么同时成功要么同时失败 ,那么就应该考虑使用事务。
开启事务
# 事务
from django.db import transaction
try:
with transaction.atomic():
# sql1
# sql2
...
# 在with代码块内书写的所有orm操作都是属于同一个事务
except Exception as e:
print(e)
print('执行其他操作')
五、orm中常用字段及参数
5.1 常用字段
一、自增字段
# 示例:
id = models.AutoField(primary_key=True)
- AutoField,自增字段。
- primary_key=True,表示设为主键。
- 由于该字段ORM会自动生成,所以一般不需要我们再创建主键。
二、varchar类型字段
username = models.CharField(max_length=32,verbose_name='用户名')
'''
max_length参数必须带上
verbose尽量带上
'''
- max_length,长度,必传参数。
- verbose_name,字段的注释,尽量带上。
三、int类型字段
password = models.IntegerField(verbose_name='')
附:如果是手机号、QQ号等,可以使用大段数字类型
phone_num = models.BigIntegerField(verbose_name='')
四、float浮点类型字段
price = models.DecimalField(max_digits=8,decimal_places=2,verbose_name='价格')
- max_digits=8,表示总长度最多8位。
- decimal_places=2,表示保留小数点2位。
五、邮箱类型字段
**作用:**当字段下的数据为邮箱时,最好用这个,后续校验型组件会对其进行检测,并不是给models看的。
user_email = models.EmailField(verbose_name='用户邮箱')
# 默认为varchar(254)
六、年月日,时间类型字段
birthday = models.DateField(auto_now_add=True,verbose_name='生日')
- 参数1:auto_now_add,只在创建数据的时候,记录创建时间,后续不会自动修改了。
- 参数2:auto_now,每次修改数据的时候,都会自动更新当前时间。
七、年月日时分秒,时间类型字段
- 相对与DateField字段来说,更为精确,因为可以到时分秒。
reg_time = models.DateTimeField(auto_now_add=True,verbose_name='注册时间')
- 参数1:auto_now_add,只在创建数据的时候,记录创建时间,后续不会自动修改了。
- 参数2:auto_now,每次修改数据的时候,都会自动更新当前时间。
八、布尔值类型
- 数据库中没有布尔类型,所以实际存入数据库的数据为0或1
is_vip = models.BooleanField(verbose_name='是否为VIP')
- **注意:**如果是在原有表的基础之上添加字段时,不管是默认值还是允许为空,都会报错,需要使用可为空布尔字段NullBOOleanField。
status = models.NullBooleanField()
# 默认为True,也就是1
九、文本类型字段
content = models.TextField()
- 该字段可以用来存大段内容(文章、博客…),没有字数限制。
十、文件类型
user_photo = models.FileField(upload_to="../data",verbose_name='用户头像')
- upload_to,表示文件保存的路径。
- 注意,路径需要是相对路径,而不是绝对路径。
5.2 自定义字段
# django除了给你提供了很多字段类型之外 还支持你自定义字段
class MyCharField(models.Field):
def __init__(self,max_length,*args,**kwargs):
self.max_length = max_length
# 调用父类的init方法
super().__init__(max_length=max_length,*args,**kwargs) # 一定要是关键字的形式传入
def db_type(self, connection):
"""
返回真正的数据类型及各种约束条件
:param connection:
:return:
"""
return 'char(%s)'%self.max_length
# 自定义字段使用
myfield = MyCharField(max_length=16,null=True)
5.3 外键字段及参数
# 外键字段及参数
unique=True
ForeignKey(unique=True) === OneToOneField()
# 你在用前面字段创建一对一 orm会有一个提示信息 orm推荐你使用后者但是前者也能用
db_index
如果db_index=True 则代表着为此字段设置索引
索引:就是一种数据结构,类似于书的目录。意味着以后在查询数据的应该先找目录再找数据,而不是一页一页的翻书,从而提升查询速度降低IO操作
to_field
设置要关联的表的字段 默认不写关联的就是另外一张的主键字段
on_delete
当删除关联表中的数据时,当前表与其关联的行的行为。
"""
django2.X及以上版本 需要你自己指定外键字段的级联更新级联删除
"""
六、数据库查询优化
前言:
-
为了更好的看出效果,把下列的代码复制到settings.py文件内。
该代码可是实现效果:运行测试文件时可以看到具体执行的sql原生语句。
LOGGING = { 'version': 1, 'disable_existing_loggers': False, 'handlers': { 'console':{ 'level':'DEBUG', 'class':'logging.StreamHandler', }, }, 'loggers': { 'django.db.backends': { 'handlers': ['console'], 'propagate': True, 'level':'DEBUG', }, } }
6.1 only与defer
ORM语句的特点:
- 惰性查询,如果仅仅只是书写了orm语句,在后面根本没有用到该语句所查询出来的数据,那么orm会自动识别直接不执行。
测试:检验惰性查询
一、直接书写orm语句
test.py文件代码
import os if __name__ == "__main__": os.environ.setdefault("DJANGO_SETTINGS_MODULE", "djangoProject.settings") import django django.setup() from app_01 import models models.Book.objects.filter(pk=1)输出信息:无
二、书写orm语句并打印
test.py文件代码
res = models.Book.objects.filter(pk=1) print(res)输出信息:
<QuerySet [<Book: Book object>]> (0.000) SELECT @@SQL_AUTO_IS_NULL; args=None (0.001) SELECT VERSION(); args=None (0.004) SELECT `app_01_book`.`id`, `app_01_book`.`title`, `app_01_book`.`price`, `app_01_book`.`bind_publish_id`, `app_01_book`.`inventory`, `app_01_book`.`order` FROM `app_01_book` WHERE `app_01_book`.`id` = 1 LIMIT 21; args=(1,)
可以发现:
- ORM确实具有惰性查询的特点,当检测到没用到查询出来的数据对象时,不会执行SQL命令。要用数据了才会走数据库。
一、什么是only
- filter与all都是可以获取数据的,但遵循的是默认的惰性查询
- only可以实现的效果与all()是一样的,返回的也是所有数据的QuerySet对象,只不过调用only函数时需要传入字段,当需要该字段的数据时,无需查询。反之,会重新跑数据库查询。
only测试:
book_queryset = models.Book.objects.only('title')
for book_obj in book_queryset:
print(book_obj.title)
'''控制台输出:(打印的书名略,只展示SQL语句)
(0.000) SELECT @@SQL_AUTO_IS_NULL; args=None
(0.000) SELECT `app_01_book`.`id`, `app_01_book`.`title` FROM `app_01_book`; args=()
'''
for book_obj in res:
print(book_obj.inventory)
print(res)
'''
(0.000) SELECT VERSION(); args=None
(0.000) SELECT `app_01_book`.`id`, `app_01_book`.`inventory` FROM `app_01_book` WHERE `app_01_book`.`id` = 1; args=(1,)
(0.000) SELECT `app_01_book`.`id`, `app_01_book`.`inventory` FROM `app_01_book` WHERE `app_01_book`.`id` = 2; args=(2,)
(0.000) SELECT `app_01_book`.`id`, `app_01_book`.`inventory` FROM `app_01_book` WHERE `app_01_book`.`id` = 3; args=(3,)
(0.000) SELECT `app_01_book`.`id`, `app_01_book`.`inventory` FROM `app_01_book` WHERE `app_01_book`.`id` = 4; args=(4,)
'''
- 可以发现,当我们使用到only函数括号内的字段时,无需再次去数据通过**select … from…where…**语句进行查询。
- 而对inventory字段进行操作时,则会因为懒查询而重新去数据库进行查找。
二、什么是defer
- defer与only刚好相反,如果查询的是非括号内的字段,则不需要走数据库。
测试:
res = models.Book.objects.defer('title')
print(res.first().title)
'''
(0.000) SELECT @@SQL_AUTO_IS_NULL; args=None
(0.000) SELECT `app_01_book`.`id`, `app_01_book`.`price`, `app_01_book`.`bind_publish_id`, `app_01_book`.`inventory`, `app_01_book`.`order` FROM `app_01_book` ORDER BY `app_01_book`.`id` ASC LIMIT 1; args=()
(0.000) SELECT VERSION(); args=None
(0.000) SELECT `app_01_book`.`id`, `app_01_book`.`title` FROM `app_01_book` WHERE `app_01_book`.`id` = 1; args=(1,)
'''
print(res.first().price)
'''
(0.000) SELECT @@SQL_AUTO_IS_NULL; args=None
(0.001) SELECT `app_01_book`.`id`, `app_01_book`.`price`, `app_01_book`.`bind_publish_id`, `app_01_book`.`inventory`, `app_01_book`.`order` FROM `app_01_book` ORDER BY `app_01_book`.`id` ASC LIMIT 1; args=()
'''
-
可以发现,defer函数内传入的字段为title,所以当查询该字段的数据时,会重新到数据库查询。
当defer函数内传入的字段,与实际使用的字段不一致,则不需要再去数据库。
6.2 select_related
一、观察默认的跨表查询,SQL语句是如何执行的
-
res = models.Book.objects.all() for i in res: print(i.publish.name) -
输出结果如下图:
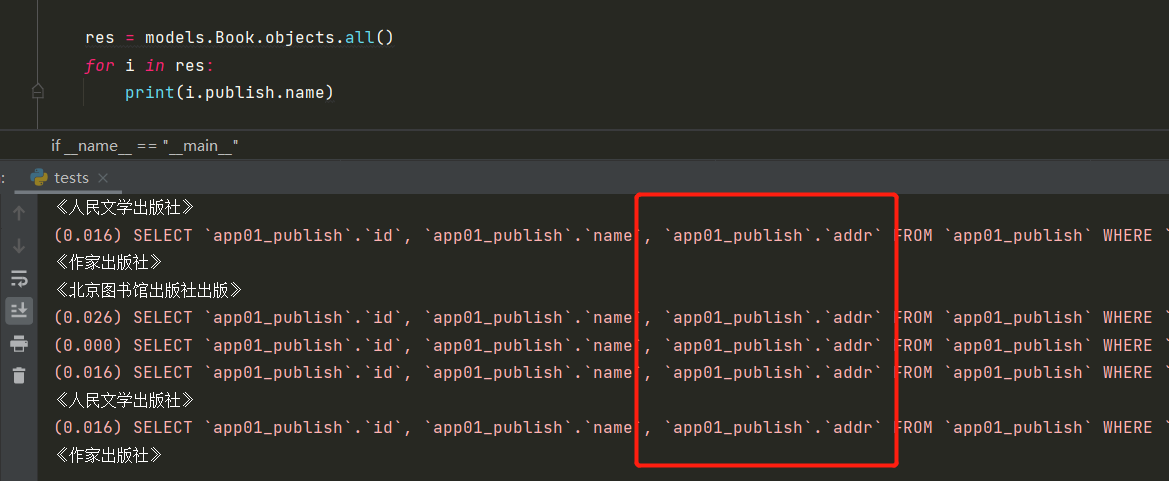
可以看到,使用**all()**获取的数据对象,跨表查询字段数据时,每循环查询一次就要走一次数据库。
二、使用 select_related
作用:
- select_related函数与only/defer一样,需要传入参数,该参数为虚拟外键字段,随后通过该虚拟外键字段来将两张表连起来,然后一次性将大表里面的所有数据,全部封装给查询出来的对象,这个时候对象无论是 . 哪张表,都无需再走数据库查询了。(相当于数据库的INNER JOIN)
- 注:select_related括号内只能放外键字段,并且只支持:一对多、一对一,多对多不行。
代码示例:
res = models.Book.objects.select_related('bind_publish')
for book_obj in res:
print(book_obj.bind_publish.name,book_obj.bind_publish.addr)
- 图书与出版社为一对多关系,出版社可以出版多本图书,而一本图书只能在一个出版社出版。 因为符合select_related的使用规则,所以可以进行链表。
- bind_publish为book表中的虚拟外键字段,通过select_related函数返回的数据对象,只要是跨到出版社表查询字段数据时,都不会再走数据库。
# 代码对应的原生SQL语句如下:
(0.001) SELECT `app_01_book`.`id`, `app_01_book`.`title`, `app_01_book`.`price`, `app_01_book`.`bind_publish_id`, `app_01_book`.`inventory`, `app_01_book`.`order`, `app_01_publish`.`id`, `app_01_publish`.`name`, `app_01_publish`.`addr` FROM `app_01_book` INNER JOIN `app_01_publish` ON (`app_01_book`.`bind_publish_id` = `app_01_publish`.`id`); args=()
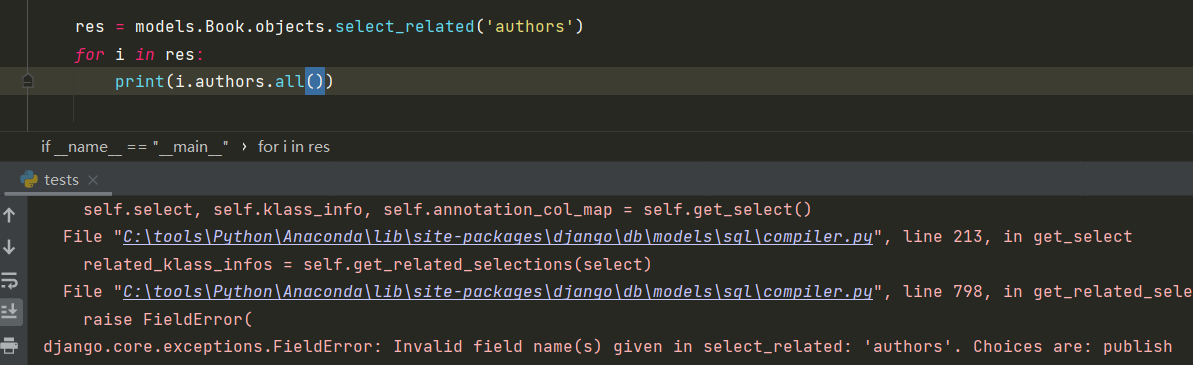
三、多对多使用select_related的情况
# 多对多
'''
通过图书表,查询作者表,多对多。
最终现象:报错
'''
res = models.Book.objects.select_related('authors')
for i in res:
print(i.authors.all())
6.3 prefetch_related
prefetch_related:
- 该方法内部其实就是子查询 (mysql中的 in ),将子查询所查询出来的所有结果,也封装到对象中。
- 支持多对多。
代码示例:
res = models.Book.objects.prefetch_related('bind_publish')
for book_obj in res:
print(book_obj.bind_publish.name,book_obj.bind_publish.addr)
'''SQL
(0.000) SELECT `app_01_publish`.`id`, `app_01_publish`.`name`, `app_01_publish`.`addr` FROM `app_01_publish` WHERE `app_01_publish`.`id` IN (1, 2, 3, 4); args=(1, 2, 3, 4)
'''
- 当需要用查询到的数据时,则会先请求获取关联表的数据,随后再查询字段的值时,不需要再次去数据库。
prefetch_related与select_related的异同
相同点:
- 相对于select_related来说,prefetch_related与它所要实现的目的都是相同的,都是为了阻止由访问相关对象,而导致的数据库查询泛滥。
不同点:
- select_related不支持多对多,而prefetch_related全都支持。
- prefetch_related会比select_related多查询一次,但会更性能的消耗会更少。


















 535
535

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











