







 本文详细介绍了Hadoop集群的搭建流程,包括虚拟机配置、SSH无密码登录设置、JDK与Hadoop安装,以及WordCount测试案例的运行。同时,提供了在Windows环境下使用Eclipse开发并运行MapReduce程序的教程。
本文详细介绍了Hadoop集群的搭建流程,包括虚拟机配置、SSH无密码登录设置、JDK与Hadoop安装,以及WordCount测试案例的运行。同时,提供了在Windows环境下使用Eclipse开发并运行MapReduce程序的教程。
文章目录
一、下载安装VMware Workstation及相关配置
1.VMware Workstation的虚拟网络配置
1.1点击编辑选项中的虚拟网络编辑器

1.2点击右下角更改设置

选择配置VMnet8,下面选择[NAT模式],勾选两个复选框,子网IP和子网掩码设置如下:

2.虚拟机的创建
2.1点击创建虚拟机

3.Xshell远程连接的创建及使用
3.1下载Xshell并安装
3.2配置连接
点击左侧新建按钮:

填写名称和主机(IP):名称用于区分就好

然后点击左侧用户身份验证,填写用户名和密码,即所要连接的主机的用户名和密码:

首次连接到虚拟机会提示是否保存主机密钥,选择<接受并保存>:

正确连接之后如下:

文件传输:为了实现简单的文件传输,需要在虚拟机的 Linux 系统里安装一个小 工具,首先刷新 Linux 软件库:(sudo apt-get update),稍等片刻后,输入(sudo apt-get install lrzsz)安装 lrzsz:
说明:lrzsz 是一款在 Linux 里可代替 ftp 上传和下载的程序,安装后在终端里输入 rz 回车,就可以在弹出的窗口中选择本地文件上传到远程主机的当前目录下,而输入 sz filename 就可以把远程主机里的文件下载到本地。
二、Hadoop及相关环境的安装与WordCount测试
实验环境:64Ubuntu18.04虚拟机(master,slave1,slave2),创建好对应连接的Xshell或者guacamole,默认个虚拟机之间可以相互ping通,需要软件如下:jdk-8u171-linux-x64.tar.gz、hadoop-3.1.0.tar.gz
1.修改各个hosts文件,在本地植入部分DNS映射(每个节点都需要运行)
将对应的角色名与IP匹配起来,然后尝试相互ping通:(中间部分master、slave1、slave2为增加部分)

保障了 Hadoop 可以通过角色名在局域网里找到各个节点,为了让 Hadoop 可以进 一步读取、操作各个节点,需要赋予其登录的权限,意即让 Hadoop 拥有各个节点的普通用户账 号,从而在需要操作各个节点时直接用对应的账号登录获取操作权限。SSH 协议可以为节点上的 账户创建唯一的公私钥,然后利用这些公私钥实现无密码登录,从而让 Hadoop 直接绕开传统的 账号密码登录过程,直接用公私钥访问节点。
2.配置SSH无密码登录
2.1生成各个节点的SSH公私钥(每个节点都需运行)
若没有安装ssh,则运行一下命令:
sudo apt-get install openssh-server #安装
sudo /etc/init.d/sshstart #启动
sudo /etc/init.d/sshstop #停止
生成SSH公私钥
cd ~/.ssh # 如果没有该目录,先执行一次 ssh localhost
rm ./id_rsa* # 删除之前生成的公匙(如果有)
ssh-keygen -t rsa # 一直按回车就可以

可以看到生成了id_rsa, id_rsa.pub文件,authorized_keys等其他文件是后续过程中生成的,当前步骤下忽略。
2.2将slave1和slave2的公钥id_rsa.pub传给master(slave1、slave2运行)
#传送时可能需要密码
scp ~/.ssh/id_rsa.pub hadoop@master:/home/hadoop/.ssh/id_rsa.pub.slave1
scp ~/.ssh/id_rsa.pub hadoop@master:/home/hadoop/.ssh/id_rsa.pub.slave2
scp是linux下的远程拷贝,使用scp命令需要服务端linux提供ssh服务,ssh默认端口是22
命令:
(1)将本地文件拷贝到远程:scp 文件名 用户名@计算机IP或者计算机名称:远程路径
(2)从远程将文件拷回本地:scp 用户名@计算机IP或者计算机名称:文件名本地路径
(3)将本地目录拷贝到远程:scp -r目录名 用户名@计算机IP或者计算机名称:远程路径
(4)从远程将目录拷回本地:scp-r 用户名@计算机IP或者计算机名称:目录名本地路径

authorized_keys是后续过程中生成的,当前步骤下忽略。
2.3将master、slave1、slave2的公钥信息追加到master的authorized_keys文件中(master运行)
cat id_rsa.pub >> authorized_keys
cat id_rsa.pub.slave1 >> authorized_keys
cat id_rsa.pub.slave2 >> authorized_keys

成功生成authorized_keys文件
2.4将authorized_keys文件发给salve1和salve2(master运行)
scp authorized_keys hadoop@slave1:/home/hadoop/.ssh/authorized_keys
scp authorized_keys hadoop@slave2:/home/hadoop/.ssh/authorized_keys
2.5每个节点尝试使用ssh <角色名>直接登陆其他节点

如果所有节点正常运行,则配置成功。
3.安装JDK(每个节点都需运行)
3.1上传JDK压缩包
在命令行输入rz:

在弹出的对话框中选择JDK安装包即可,此时安装包放在了/home/hadoop,和rz执行所在的目录一致
3.2解压缩
sudo mkdir -p /usr/local/jvm
tar -zxvf jdk-8u171-linux-x64.tar.gz -C /usr/local/jvm
3.3配置环境变量
打开.bashrc文件(配置/etc/profile也可以)

可以在.bashrc中配置环境变量,追加最后面的三句话,注意安装的jdk版本及目录

然后执行以下代码:
source ~/.bashrc
java -version
javac -version
配置成功应为

4.安装hadoop(每个节点都需运行)
4.1解压重命名hadoop
tar -zxvf hadoop-3.1.0.tar.gz -C /usr/local/
sudo mv /usr/local/hadoop-3.1.0 /usr/local/hadoop #mv重命名
sudo chown -R hadoop:hadoop /usr/local/hadoop
https://blog.csdn.net/jinpengncu/article/details/77879844 #chown命令
然后查看权限更改情况(下图所示为正确情况):

4.2配置环境变量
sudo vi /etc/environment


在最后面追加:/usr/local/hadoop/bin:/usr/local/hadoop/sbin;
然后在控制台输入source /etc/environment使得配置文件生效;

如上图所示及配置成功。
4.3修改slaves文件
vi /usr/local/hadoop/etc/hadoop/slaves

4.4修改core-site.xml文件
vi /usr/local/hadoop/etc/hadoop/core-site.xml

4.5修改hdfs-site.xml文件
vi /usr/local/hadoop/etc/hadoop/hdfs-site.xml

4.6修改mapred-site.xml文件
vi /usr/local/hadoop/etc/hadoop/mapred-site.xml

4.7修改yarn-site.xml文件
vi /usr/local/hadoop/etc/hadoop/yarn-site.xml

4.8修改hadoop-env.sh文件
vi /usr/local/hadoop/etc/hadoop/hadoop-env.sh修改JAVA_HOME

5.启动及验证Hadoop
5.1对hadoop进行namenode的格式化(master下运行)
/usr/local/hadoop/bin/hdfs namenode -format


该处没有截图,成功效果与上图类似。
5.2启动hdfs和yarn(所有节点下运行)
/usr/local/hadoop/sbin/start-dfs.sh
/usr/local/hadoop/sbin/start-yarn.sh
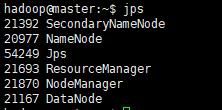
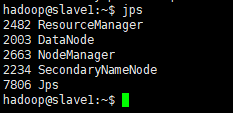
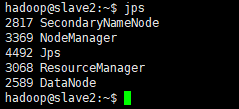
jps # 每个节点都查看一次
#停止操作如下
/usr/local/hadoop/sbin/stop-dfs.sh #停止hdfs
/usr/local/hadoop/sbin/stop-yarn.sh #停止yarn
master:
slave1、slave2:
可能遇到的问题:
-
master下DataNode节点未启动,jps查看不到:
出现该问题的原因:在第一次格式化dfs后,启动并使用了hadoop,后来又重新执行了格式化命令(hdfs namenode -format),这时namenode的clusterID会重新生成,而datanode的clusterID 保持不变。
打开hdfs-site.xml里配置的datanode和namenode对应的目录,分别打开current文件夹里的VERSION,可以看到clusterID项正如日志里记录的一样,确实不一致,修改datanode里VERSION文件的clusterID 与namenode里的一致,再重新启动dfs(执行start-dfs.sh)再执行jps命令可以看到datanode已正常启动。
查看
/usr/local/hadoop/hdfs/name和/usr/local/hadoop/hdfs/data下current文件夹内的VERSION:

我在这里DataNode正常启动,所以clusterID相同;若不同,修改为相同的即可。
-
slave1、slave2下DataNode节点未启动:
执行以下语句:
#在两台slave机器上进入 /usr/local/hadoop/hdfs/data目录下,将current文件删除即可 #然后运行: /usr/local/hadoop/sbin/start-dfs.sh /usr/local/hadoop/sbin/start-yarn.sh -
如何重新格式化namenode:
- 删除hdfs-site.xml中dfs.name.dir和dfs.data.dir指定的目录
- 删除core-site.xml中hadoop.tmp.dir指定的目录
- 重新执行命令:
/usr/local/hadoop/bin/hdfs namenode -format
5.3利用hdfs创建文件夹并上传文件
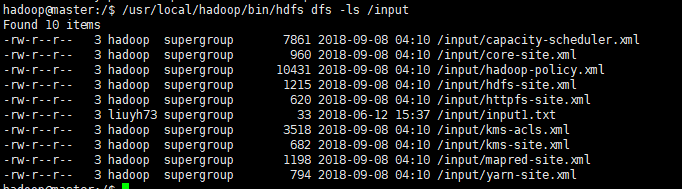
/usr/local/hadoop/bin/hdfs dfs -mkdir /input #创建文件夹
/usr/local/hadoop/bin/hdfs dfs -put /usr/local/hadoop/etc/hadoop/*.xml /input #上传文件
创建文件夹失败:

(解决方法:创建失败时,master节点jps查看服务发现少了NameNode,然后将所有节点的服务都进行了重启)
上传文件之后,可以利用hadoop fs -ls /input或者/usr/local/hadoop/bin/hdfs dfs -ls /input查看input文件夹下的文件。
删除文件可以使用hadoop -rm <filename>或者/usr/local/hadoop/bin/hdfs dfs -rm <filename>
删除文件夹使用hadoop -rm -r <directoryname>或者/usr/local/hadoop/bin/hdfs dfs -rm -r <directoryname>

(上图报错,网友说是hadoop的一个bug,可以正常上传文件)
尝试在宿主机下用google浏览器打开192.168.142.137:50070网址:(注意:Microsoft Edge打不开该网址)

点击Browse the file system:查看input文件夹内容

可能遇到的问题:
-
hadoop无法访问50070端口:
-
排查NameNode是否部署成功
-
排查DataNode是否部署成功
-
防火墙是否关闭
-
如果防火墙关闭了,可按照以下方式进行设置:
netstat –ant #查看本地开发端口
127.0.0.150070
在hdfs-site.xml中,更改开放端口的绑定IP:
<property> <name>dfs.http.address</name> <value>0.0.0.0:50070</value> </property>将绑定IP改为0.0.0.0,而不是本地回环IP,这样,就能够实现外网访问本机的50070端口了
-
-
网站中DataNode节点(slave1、slave2)没有显示:
原因是slave1、slave2上DataNode进程没有正常启动。
参照前面5.2的解决方案即可。
5.4使用hadoop自带的WordCount
/usr/local/hadoop/bin/hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.0.jar wordcount /input /output
#查看运行结果
/usr/local/hadoop/bin/hdfs dfs -cat /output/*
-
正常运行之后结果如下:


(若有中文字符,则可能未正常显示)。
可能遇到的问题:
-
找不到org.apache.hadoop.mapreduce.v2.app.MRAppMaster:
解决方法:根据提示修改mapred-site.xml:(自己将所有节点都修改了)

-
可能出现内存空间不足而异常退出:

有时会报错,但也可算出结果,若输入文件过多则算不出结果。可以调整虚拟机内存大小,或者缩减一些input文件夹下文件数目。 -
运行时显示文件夹已存在:

hadoop -rm -r /output、hadoop -rm -r /tmp删除output和tmp即可。
三、在宿主机windows下编写mapreduce程序然后在Ubuntu上运行
所需工具及安装包(与Ubuntu尽量保持一致):
Eclipse:

jdk:

hadoop:

默认jdk已经配置成功,确保可以正常运行。
1.安装Hadoop3
1.1将hadoop-3.1.0.tar.gz解压到指定目录
我解压到:E:\hadoop-3.1.0,然后前往https://download.youkuaiyun.com/download/junior19/10292556下载

解压该文件夹,并将其文件夹下的文件,替换掉E:\hadoop-3.1.0\bin下的文件;然后将hadoop.dll复制到C:\Windows\System32中。
1.2配置环境变量
新增一个环境变量指定为hadoop的bin目录。

控制台可以输出hadoop版本号即配置成功。

2.开放Hadoop权限(master下面的即可)
为了可以在Ecplise上对Ubuntu上的HDFS文件操作,需要设置权限。
修改Ubuntu里面的hdfs-site.xml,添加下面代码:
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
确保已经在hadoop上创建了input文件夹:
/usr/local/hadoop/bin/hdfs dfs -mkdir /input
执行以下命令:
hadoop fs -chmod 777 /
3.在Eclipse上安装Hadoop插件
3.1下载插件:hadoop-eclipse-plugin-2.7.3.jar
将其放置在Eclipse安装目录的plugins目录下,重启Eclipse:

3.2配置hadoop3
- 打开Ecplise,点击
window->Preferences找到Hadoop Map/Reduce,点击Browse配置hadoop安装路径

若找不到Hadoop Map/Reduce选项,是因为插件安装未被识别,解决方法如下:
把eclipse安装目录下的configuration/org.eclipse.update和org.eclipse.core.runtime的目录整个删除,重启eclipse。(org.eclipse.update 文件夹下记录了插件的历史更新情况,它只记忆了以前的插件更新情况,而新安装的插件它并不记录,所以删除掉这个文件夹就可以解决这个问题了,不过删除掉这个文件夹后, eclipse 会重新扫描所有的插件,此时再重新启动 eclipse 时可能会比刚才稍微慢点)
其他解决方案:https://blog.youkuaiyun.com/u010887744/article/details/50666716
-
点击
window->show view->other->map/reduce locationsOPEN -
右上角田字样的按钮切换到map/reduce项目(以后可以在这里切回去Resource界面)


-
右键点击控制台黄色小象的空白处,点击New Hadoop location

-
配置如下:
-
Location name可以任意填写
-
Host为主机IP,可以填写IP地址,也可以填写主机名并在windows下hosts文件中添加IP映射
-
Map/Reduce(V2)Master中Port为mapred-site.xml中的端口,没设置可以忽略
-
DFS Master中Port与core-site.xml中端口保持一致

-
然后点击Advanced parameters:设置hadoop.tmp.dir,与core-site.xml保持一致

-
-
在Ubuntu Hadoop集群启动之后,效果如下:

output和tmp文件可以忽略。
4.运行WordCount实例
4.1上传input文件
可以在Ubuntu下用命令行上传,或书写文件;也可以在右键点击input文件夹,选择Upload files to DFS来上传文件。可以建立一些input1.txt、input2.txt等文件,里面填一些单词即可。
4.2创建一个新项目
新建项目,File->new->Project->Map/Reduce project ,包名最好留空!否则最后运行会遇到”找不到class”错误。
4.3新建类文件WordCount
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public WordCount() {
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
if(otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCount.TokenizerMapper.class);
job.setCombinerClass(WordCount.IntSumReducer.class);
job.setReducerClass(WordCount.IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for(int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true)?0:1);
}
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public TokenizerMapper() {
}
public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
this.word.set(itr.nextToken());
context.write(this.word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public IntSumReducer() {
}
public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
IntWritable val;
for(Iterator<IntWritable> i$ = values.iterator(); i$.hasNext(); sum += val.get()) {
val = (IntWritable)i$.next();
}
this.result.set(sum);
context.write(key, this.result);
}
}
}
右键点击class选择run as->Run configuations设置如下,Arguments中设置input和output地址,IP填写集群主机IP,然后RUN即可。

4.4运行效果


4.5配置&运行时报错
问题一:
An internal error occurred during: “Map/Reducelocation status updater” .java.lang.NullPointerException
我们hadoop-eclipse-plugin-2.7.3.jar放到Eclipse的plugins目录下,重启一下Eclipse,然后,打开Window–>Preferens,可以看到Hadoop Map/Reduc选项,然后点击出现了An internal error occurredduring: “Map/Reduce location status updater”.java.lang.NullPointerException,如图所示:

解决:
我们发现刚配置部署的Hadoop2还没创建输入和输出目录,先在hdfs上建个文件夹 。
/usr/local/hadoop/bin/hdfs dfs -mkdir /input
我们在Eclipse的DFS Locations目录下看到我们这两个目录,如图所示:

问题二:
log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
这种情况一般是由于log4j这个日志信息打印模块的配置信息没有给出造成的,可以在项目的src目录下,新建一个文件new->other->general->file,命名为“log4j.properties”,填入以下信息:
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appenderlogfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
保存后重新运行即可成功。
其他问题:

















 590
590

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









