



项目基础介绍
同步网络(SyncNet) 是一个致力于自动音频到视频同步的开源项目,特别适用于消除视频中音视频流的时间延迟以及在多人场景下识别说话者。。此项目基于Python实现,并依赖一些特定的库和技术来完成其复杂的任务。
项目地址
关键技术和框架
SyncNet利用深度学习方法处理音频与视频数据间的同步问题,核心涉及到神经网络模型的训练与应用。它并不直接依赖于外部框架,内置了对深度学习库(如TensorFlow或PyTorch,虽然项目本身未直接指定)的调用。除此之外,为了处理媒体文件,项目明确要求安装FFmpeg,这是一个强大的音频和视频处理工具。
安装和配置详细步骤
准备工作
安装Python环境。 确保您的系统已安装Python 3.6或更高版本。可以通过运行以下命令检查Python版本
python3 --version安装FFmpeg
安装FFmpeg以进行音视频处理:
brew install ffmpeg # macOS conda install -c conda-forge ffmpeg # Anaconda环境下克隆项目源代码
git clone https://github.com/joonson/syncnet_python.git cd syncnet_pytho安装依赖库
接下来,安装项目所需的Python包,根据项目的requirements.txt文件执行:
pip3 install -r requirements.txt运行演示
查看项目目录中的README.md文件
python demo_syncnet.py --videofile data/example.avi --tmp_dir ~/syncnet_temp验证输出是否正确显示音频视频偏移值,这证明SyncNet正在按预期工作。
AV offset: 3 # 这个指标表示音频和视频之间的时间偏移量,单位通常是毫秒。在这个例子中,AV offset为3,意味着音频相对于视频提前了3毫秒。这个值越接近0,表示同步的准确性越高
Min dist: 5.353 # 音频和视频的特征在不同时间偏移下的最小距离(距离可以理解为一种误差度量)。数值越低,音频和视频的匹配度越高,也就是越同步
Confidence: 10.021 # 衡量音视频同步的置信度分数,数值越高,表示SyncNet越确定音视频是同步的,`Confidence: 10.021` 表示SyncNet对当前音视频同步结果的置信度非常高
运行上述报错情况一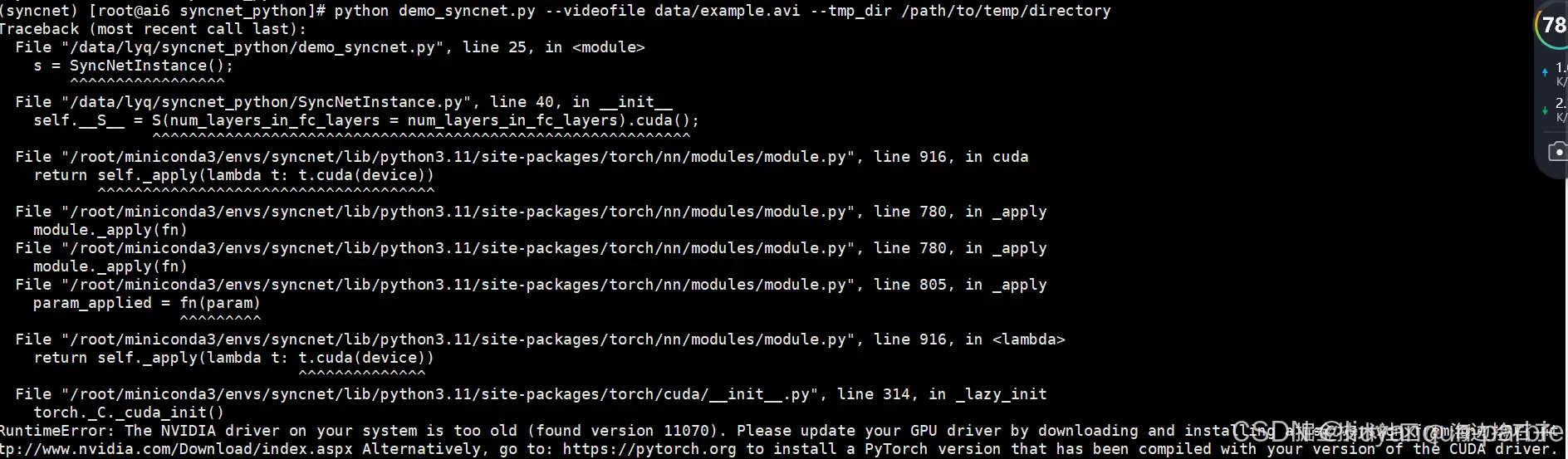
系统的NVIDIA驱动版本太旧,无法与当前PyTorch使用的CUDA版本兼容
方法一是升级CUDA驱动版本
-
检查当前NVIDIA驱动版本:
您可以通过以下命令检查当前安装的驱动版本:
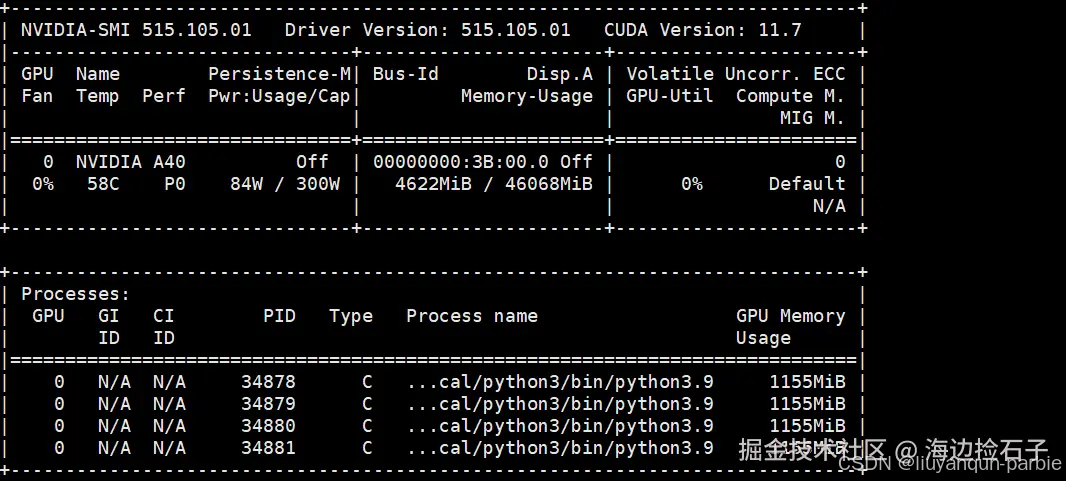
-
下载并更新驱动:
- 根据您的显卡型号,访问NVIDIA驱动下载页面。
- 下载并安装最新的驱动程序,确保安装版本兼容最新的CUDA版本
方法2:使用与旧驱动兼容的PyTorch和CUDA版本
-
查找驱动支持的CUDA版本:
- 在错误信息中显示的版本为
11070,这通常对应CUDA 11.7。 - 您可以通过查阅NVIDIA官方文档确认该驱动支持的CUDA版本。
- 在错误信息中显示的版本为
-
安装与该CUDA版本兼容的PyTorch:
- 访问PyTorch官网并选择与您CUDA版本兼容的PyTorch版本。
- 比如,如果您的驱动支持CUDA 11.7,可以安装PyTorch2.0.0或其他与该版本CUDA兼容的版本。
例如,安装命令可能如下:
pip install torch==1.13.0+cu116 torchvision==0.14.0+cu116 torchaudio==0.13.0 --extra-index-url https://download.pytorch.org/whl/cu116报错二 numpy版本过高报错
AttributeError: module 'numpy' has no attribute 'int'. Did you mean: 'inf'?
降低numpy版本安装失败,至少需要 pip install numpy==1.24.0,针对上面的代码,只能改下代码,np.array(keep).astype(np.int) 更改成np.array(keep).astype(int)
报错三 scenedetect包代码处理失败
升级secenedetct包到0.6.4
pip install scenedetect==0.6.4报错四:moviePy包不兼容
MoviePy AudioFileClip.to_soundarray 报错 TypeError: arrays to stack must be passed as a “sequence“
使用 python3.11 时,遇到了上述问题。 使用早期版本的 python(python 3.8),并且 to_soundarray() 成功运行。 直接使用moviePy以前的包
pip install git+https://github.com/Zulko/moviepy.git@bc8d1a831d2d1f61abfdf1779e8df95d523947a5高级使用:完整流程
下载预训练模型:
./download_model.sh 进行完整的视频处理管道测试:
sh run_pipeline.sh --videofile <你的视频路径>.mp4 --reference <参考视频名> --data_dir <输出数据目录> 使用SyncNet处理视频:
python run_syncnet.py --videofile <你的视频路径>.mp4 --reference <参考视频名> --data_dir <输出数据目录> 可视化结果:
python run_visualise.py --videofile <你的视频路径>.mp4 --reference <参考视频名> --data_dir <输出数据目录>至此,您已经成功安装配置了SyncNet项目,并可以开始探索它的各种功能,用于实现视频中的音频视觉同步分析。享受您的编码之旅吧!
参考


















 2732
2732

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









