







 本文深入探讨了维度设计的基础和高级主题,包括维度的概念、设计方法、层次结构、规范化与反规范化。讨论了一致性维度、交叉探查问题以及解决方案,如维度整合、水平和垂直拆分。此外,还涵盖了缓慢变化维、快照维表、历史归档等维度变化策略,以及特殊维度如递归层次、行为维度、多值维度的处理。文章强调了在维度设计中,主从维表的确定和稳定性的重要性。
本文深入探讨了维度设计的基础和高级主题,包括维度的概念、设计方法、层次结构、规范化与反规范化。讨论了一致性维度、交叉探查问题以及解决方案,如维度整合、水平和垂直拆分。此外,还涵盖了缓慢变化维、快照维表、历史归档等维度变化策略,以及特殊维度如递归层次、行为维度、多值维度的处理。文章强调了在维度设计中,主从维表的确定和稳定性的重要性。
维度设计
维度设计基础
维度的基本概念
-
维度是维度建模的基础和灵魂。
-
将度量称为“事实” ,将环境描述为“维度”
-
维度所包含的表示维度的列,称为维度属性
- 查询约束条件
- 分组和报表标签生成的基本来源
- 据易用性的关键
-
维度使用主键标识其唯一性
-
代理键
- 不具有业务含义的键
- 一般用于处理缓慢变化维
- 前台应用系统:商品ID代理键
-
自然键
- 具有业务含义的键
- 数据仓库系统:商品ID自然键
-
维度的基本设计方法
-
选择维度或新建维度
- 维度的唯一性
-
确定主维表
- 一般是 ODS 表
- 直接与业务系统同步
-
确定相关维表
- 与主维表存在关联关系
-
确定维度属性
-
二个阶段
- 第一从相关维表中选择维度属性或生成新的维度属性
- 第二从主维表 中选择维度属性或生成新的维度属性
-
确定维度属性提示
-
尽可能生成丰富的维度属性
-
尽可能多地给出包括一些富有意义的文字性描述
- 一般是编码和文字同时存在
-
区分数值型属性和事实
- 查询约束条件或分组统计为维度
- 参与度量的计算为事实
- 数值型字段是离散值多为维度
- 数值型宇段是连续值多为事实
-
尽量沉淀出通用的维度属性
- 提高下游使用的方便性
- 减少复杂度
- 避免下游使用解析时各自逻辑口径不一致
-
-
维度的层次结构
- 最底层代表最低级别的详细信息
- 最高层代表最高级别的概要信息
- 多为嵌入式层次结构
规范化和反规范化
-
雪花模式
- 属性层次被实例化为一系列维度,而非单一的维度
- 多用于联机事务处理系统( OLTP )底层结构
- 节约存储,减少数据冗余
- 雪花模型图
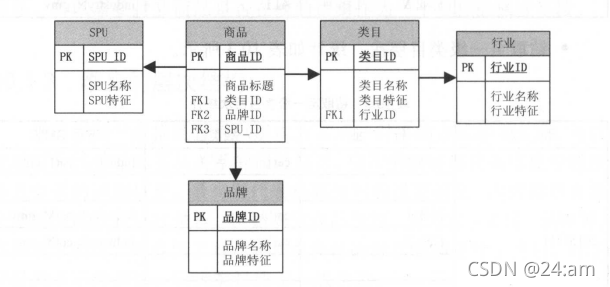
-
单一维
- 将雪花模型进行单一维度宽表化处理
- 多用于OLTP 系统:空间换分析查询性能
- 方便、易用且性能好
- 单一维度反规则化图
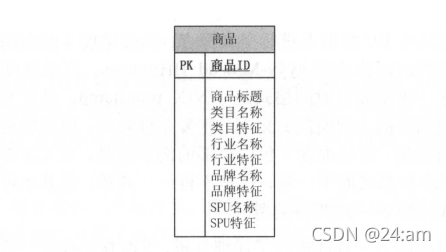
一致性维度和交叉探查
-
交叉探查定义
- 日志数据域:统计了商品维度一天的 PV 和UV
- 易数据域,:统计了商品维度的一天的下单 GMV
- 将不同数据域的商品的事实合并在一起进行数据探查,如计算转化率,成为交叉探查
-
交叉探查问题
- 不同数据域使用维度不一致
-
维度一致性表现
-
共享维表
- 公共维度交叉探查
-
一致性上卷
- 一个维度属性是另 一个维度属性的子集
- 两个维度的公共维度属性结构和内容相同
-
交叉属性
- 两个维度具有部分相同的维度属性
-
维度设计高级主题
维度整合
-
命名规范的统一
- 表名 、 字段名等统一
-
字段类型的统一
- 相同和相似字段的字段类型统一
-
公共代码及代码值的统一
- 公共代码及标志性宇段的数据类型、命名方式等统一
-
业务含义相同的表的统一
-
物理实现原则
- 将业务关系大、源系统影响差异小的表进行整合
- 将业务关系小、源系统影响差异大的表进行分而治之
-
集成方式
-
采用主从表的设计方式
-
两个表或多个表都有的字段放在主表(主要基本信息)
-
从属信息分别放在各自的从表中
-
主表主键
-
复合主键(建议采用)
- 源主键和系统或表区别标志
-
唯一主键
- 源主键和系统或表区别标志生成标识
-
-
-
直接合并
-
共有信息和个性信息都放在同一个表中
如果表字段的重合度较低,则会出现大量空值,对于存储和易用性会有影响,需谨慎选择。
-
-
不合并
- 源表的表结构及主键等差异很大
-
-
不同维度类目属性无法统一,引出如何设计维度?
-
二种方案
- 方案 1 是将维度的不同分类实例化为不同的维度,同时在主维度中保存公共属性
- 方案 2 是维护单一维度,包含所有可能的属性
-
选择方案三个原则
-
扩展性
- 当源系统、业务逻辑变化时,能通过较少的成本快速扩展模型,保持核心模型的相对稳定性
- 高内聚、低耦合思想指导
-
效能
- 性能和成本方面取得平衡
- 牺牲一定的存储成本,达到性能和逻辑的优化
-
易用性
- 模型可理解性高、访问复杂度低
- 用户能够方便地从模型中找到对应的数据表,并能够方便地查询和分析。
-
水平拆分
-
两个依据
-
第一:维度的不同分类的属性差异情况
-
当维度属性随类型变化较大时
-
建议采用方案 1:所有可能维度建立在一个维度不切实际
-
定义一个主维度用于存放公共属性
- 公共属性一般比较稳定,保证了核心维度的稳定性
-
同时定义多个子维度包含各自的特殊属性
- 通过扩展子维度的方式,保证了模型的扩展性
-
-
第二:业务的关联程度
- 相关性较低的业务,耦合在一起弊大于利
-
垂直拆分
- 主表:存放稳定 、 产出时间早、热度高的属性
- 从表:存放变化较快、产出时间晚、热度低的属性
历史归档
-
同前台归档策略(算法归档)
-
问题点
- 前台归档策略复杂,实现成本较高
- 策略可能会经常变化 ,导致数据仓库归档算法也要随之变化
- 维护和沟通成本较高
-
适用场景
- 前台归档策略逻辑较为简单
- 且变更不频繁的情况
-
-
同前台归档策略(binlog解析)
-
处理方式
- binlog日志解析获取每日增量,通过增量 merge方式获取最新的全量数据
- 可以使用增量日志的删除标志 , 作为前台数据归档的标志
-
适用场景
- 物理删除只有在归档时才执行,应用中的删除只是逻辑删除
-
-
数仓自定义策略
- 原则是尽量比前台应用晚归档、少归档
- 避免出现数据仓库中已经归档的数据再次更新的情况
维度变化
缓慢变化维
-
重写维度值
- 不保留历史数据
- 始终取最新数据
-
插人新的维度行
- 保留历史数据
- 维度值变化前的事实和过去的维度值关联
- 维度值变化后的事实和当前的维度值关联
-
添加维度列
- 保留历史数据
- 新增维度列:新维度值、旧维度值
快照维表
-
每日一份维度快照
-
优劣分析
- 简单而有效,开发和维护成本低
- 使用方便,理解性好
- 存储的极大浪费
极限存储
-
历史拉链表存储
-
拉链表处理
-
透明化
- 查询视图操作或语法树解析
-
分月做历史拉链表
- 每月初重新分区拉链表处理
- 减少分区存储
-
-
优劣分析
-
产出效率很低,大部分极限存储通常需要t-2
-
变化频率高的数据并不能达到节约成本的效果
-
结合劣势处理
- 在做极限存储前有一个全量存储表 ,全量存储表仅保留最近一段时间的全量分区数据
- 对于部分变化频率频繁的宇段需要过滤
-
微型维度
-
将一部分不稳定的属性从主维度中移出
-
将它们放置到拥有自己代理键的新表中来实现的
-
处理逻辑举例
- 用户 VIP 等级:8 个值
- 用户信用评价等级:18 个值
- 两者组合生成:代理键 1~ 144
-
未使用&劣势分析
- 局限性:计算所有可能值的组合加载,必须是枚举
- ETL 逻辑复杂:维护开发成本高
- 破坏了维度的可浏览性
特殊维度
递归层次
-
层次结构扁平化
-
所属层级及结构铺平化结构处理
-
存在问题
- 钻或下钻之前,需知类目层级
- 向下钻取,填充向上类目无法统计
- 固定层级结构,扩展性差
-
-
层次桥接表
- 加工逻辑复杂,使用逻辑复杂
行为维度
-
采用算法计算得到
- 最近一段时间消费地点
- 行为维度\事实衍生的维度”
-
行为维度划分
-
另一个维度的过去行为
- 买家最近一次访问淘宝的时间
- 最近一次发生淘宝交易的时间等
-
快照事实行为维度
- 买家从年初截至当前的淘宝交易金额
- 买家信用分值
- 卖家信用分值
-
分组事实行为维度
将数值型事实转换为枚举值
- 买家从年初截至当前的淘宝交易金额按照金额划分的等级
- 买家信用分值按照分数划分得到的信用等级等
-
复杂逻辑事实行为维度
通过复杂算法加工或多个事实综合加工得到
- 买家主营类目
- 商品热度根据访问、收藏、加人购物车、交易等情况综合计算得到
-
行为维度两个处理原则
- 第一 ,避免维度过快增长
- 第二,避免稠合度过高
-
多值维度
-
第一种处理方式是降低事实表的粒度
- 子订单粒度
- 采用分摊到子订单的方式
-
第二种处理方式是采用多字段
- 通过预留宇段的方式
-
第三种处理方式是采用较为通用的桥接表
- 灵活高、扩展性更好,但逻辑复杂、开发和维护成本较高
- 双重计算的风险
多值属性
-
维表中的某个属性字段同时有多个值,称之为“多值属性”
-
常见三种处理方式
-
第一种处理方式是保持维度主键不变,将多值属性放在维度的一个属性字段中
- 通过 k-v 对的形式放
- 扩展性好,但数据使用较为麻烦
-
第二种处理方式也是保持维度主键不变,但将多值属性放在维度的多个属性字段中
- 数量不固定,则可以采用预留字段的方式
- 扩展性较差
-
第三种处理方式是维度主键发生变化, 一个维度值存放多条记录
- 扩展性好,使用方便
- 考虑数据的急剧膨胀情况
-
杂项维度(Junk Dimension)
-
杂项维度是由操作型系统中的指示符或者标志宇段组合而成的,一般不在一致性维度之列
-
举列说明
- 淘宝交易订单的交易类型宇段
- 话费充值、司法拍卖、航旅等类型
- 支付状态、物流状态
- 直接保存在交易表中
-
将这些字段建立到一个维表中,在事实表中只需保存一个外键即可
总结:
阿里大数据之道里面说了这么多,关于维度建设的核心思想两点:1、主从维表的确定的。2、主从表维度的稳定性,使用度广,脏乱差的数据从表处理。
大家在实践过程中根据自己的应用差异定义主从维表的逻辑,再根据统计与分析逻辑确定维表的更新机制以及维度结构。

















 448
448

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









