






 本文详细解析了InnoDB引擎中索引下推的原理,通过对比无索引下推和有索引下推的执行流程,说明了其如何减少回表次数,降低IO成本。重点讲解了索引下推在查询覆盖索引和聚簇索引时的优势,并举例说明了适用场景。
本文详细解析了InnoDB引擎中索引下推的原理,通过对比无索引下推和有索引下推的执行流程,说明了其如何减少回表次数,降低IO成本。重点讲解了索引下推在查询覆盖索引和聚簇索引时的优势,并举例说明了适用场景。
一、索引下推
1、数据表准备
CREATE TABLE `s1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`key1` varchar(100) DEFAULT NULL,
`key2` int(11) DEFAULT NULL,
`key3` varchar(100) DEFAULT NULL,
`key_part1` varchar(100) DEFAULT NULL,
`key_part2` varchar(100) DEFAULT NULL,
`key_part3` varchar(100) DEFAULT NULL,
`common_field` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `uk_key2` (`key2`) USING BTREE,
KEY `idx_key1` (`key1`) USING BTREE,
KEY `idx_key3` (`key3`) USING BTREE,
KEY `idx_key_part` (`key_part1`,`key_part2`,`key_part3`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=10001 DEFAULT CHARSET=utf8;
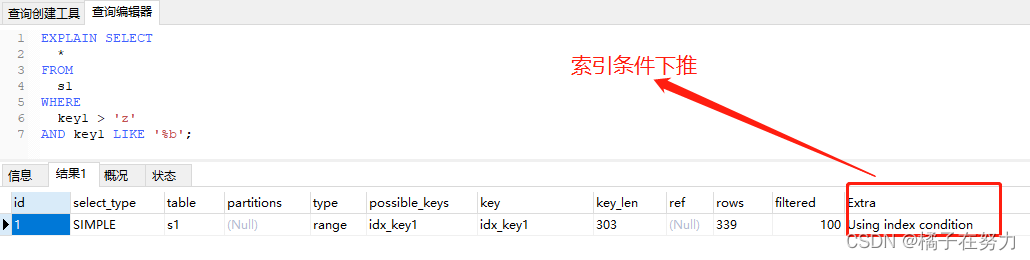
EXPLAIN SELECT
*
FROM
s1
WHERE
key1 > 'z'
AND key1 LIKE '%b';
分析执行计划如下:
2、索引下推解释
2.1、前置知识
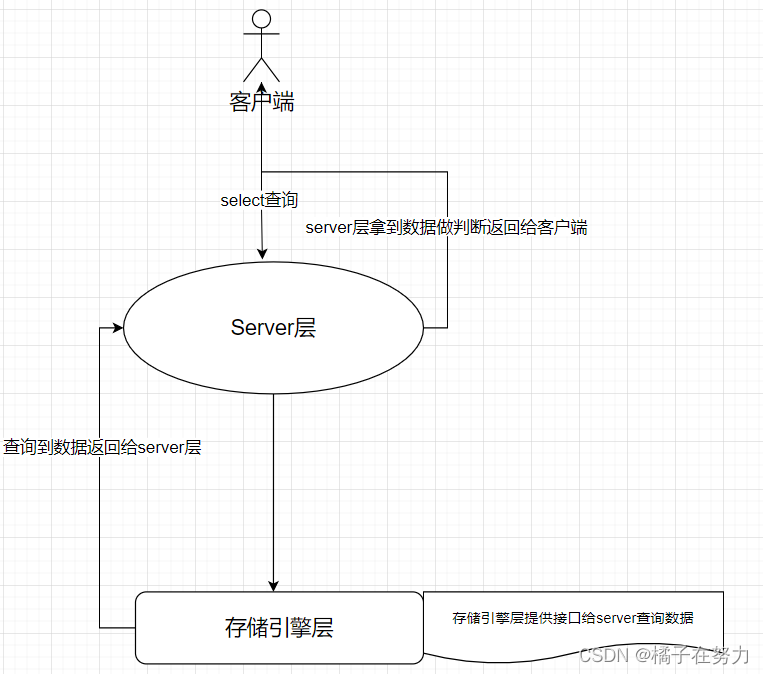
这是innodb的分层的模式,每一层有自己的功能,在一次查询中分层工作。
在这个分层的时候,就有了索引下推和不下推的区别。
2.2、没有索引下推之前
EXPLAIN SELECT * FROM s1 WHERE key1 > ‘z’ AND key1 LIKE ‘%b’;
这条sql在没有索引下推的时候是这样执行的:
1、server层首先调用存储引擎的接口,找到满足key1 > 'z’的第一条二级索引记录。后面那个like无法形成扫描区间就不说了。
2、存储引擎接口在第一步被调用,然后在key1的B+树索引上定位到第一条符合条件的数据,因为我们查的列表是 *,所以需要到聚簇索引去回表,将完整的数据返回给server层。
3、server层拿到完整数据继续判断其他的条件是不是成立,也就是在完整数据上判断key1 like '%b’这个条件是不是成立,如果成立这个数据结果将会发给客户端,否则就跳过,然后向存储引擎层查询下一条数据。
4、因为每个记录都有一个next_record属性,所以很快就能定位到下一条数据,然后回表,然后判断,然后。。。重复上述步骤就行了。注意,这里面第二次在引擎层取数据就很简单了,无需再次连接数据库,直接根据next_record获取就行。
直到索引key1形成的扫描区间(z,+无穷)的记录扫描完为止。
我们看到上面没有索引下推,他每次在引擎层拿到数据,需要先回表再返回到server,这时候才判断其余条件。
但是我们想想,另一个条件就是key1,就是索引啊,我们完全可以在引擎层获取到的时候就判断了,不符合就不用
回表了,前面我们写过,回表等同于IO一个数据页的成本。所以这个开销其实很大。
所以这个优化很有必要。
2.3、有了索引下推之后
1、server层首先调用存储引擎的接口,找到满足key1 > 'z’的第一条二级索引记录。后面那个like无法形成扫描区间就不说了。
2、存储引擎接口在第一步被调用,然后在key1的B+树索引上定位到第一条符合条件的数据,但是此时不会直接回表,而是在key1的索引树上判断条件WHERE key1 > ‘z’ AND key1 LIKE ‘%b’;是不是成立,如果不成立,则跳过,直接走下一条数据。如果成立此时才会回表,将完整记录返回给server层。
3、server拿到回表获取的完整数据之后,会判断其他条件是否成立。比如要是还有个key2='lyx’这样,没在key1的树上的条件会在server层去做判断。如果成立,则返回给客户端。如果不成立就跳过,继续向存储引擎层索要下一条数据。
我们看到,这里其实少了很多回表操作。这就是索引下推的优化结果。
其次有一点,在第一步的时候,引擎层调用接口查的是key1>'z'的数据,在定位后,不会直接回表而是判断了WHERE key1 > 'z' AND key1 LIKE '%b';是不是成立,这里又把key1>'z'判断了一遍,照着我们自己写代码,这时候就判断
AND key1 LIKE '%b';即可,但是mysql源码人们说是屎山不是没有理由的。
2.4、总结
索引下推是为了减少回表次数,降低IO成本的。所以当你是覆盖索引,或者聚簇索引查询的时候,不会有回表发生,也就不会产生索引下推。
所以索引下推就是在二级索引的时候存在的。

















 699
699




 到【灌水乐园】发言
到【灌水乐园】发言







