









 本文介绍了在Python中如何处理由numpy.loadtxt读取的字节字符串,并提供了转换为文本字符串的方法。同时对比了Python2与Python3中字节字符串与文本字符串的区别。
本文介绍了在Python中如何处理由numpy.loadtxt读取的字节字符串,并提供了转换为文本字符串的方法。同时对比了Python2与Python3中字节字符串与文本字符串的区别。
前言
在python中字符串是有字节字符串和文本字符串之分的,我们通常说的字符串是指文本字符串。而使用numpy的loadtxt函数读取的字符串默认是字节字符串,输出的话字符串前面会有个b,形如b’……’。通常是需要转换的,如果不转换将会出现问题。
numpy.loadtxt()以文本方式读取字符串
比如今天,我使用numpy的ladtxt函数读取一个存储有文件名的txt文件,输出的文件名是b’result.jpg’,很显然多了b’ ‘导致找不到文件。经过在网上查询,在知乎里发现了一个解决方法。
numpy.loadtxt读入的字符串总是bytes格式,总是在前面加了一个b
原因:np.loadtxt and np.genfromtxt operate in byte mode, which is the default string type in Python 2. But Python 3 uses unicode, and marks bytestrings with this b. numpy.loadtxt中也声明了:Note that generators should return byte strings for Python 3k.解决:使用numpy.loadtxt从文件读取字符串,最好使用这种方式np.loadtxt(filename, dtype=bytes).astype(str)
作者:Cameron
链接:https://www.zhihu.com/question/28690341/answer/164344688
来源:知乎
python2和python3字节字符串与文本字符的区别
首先来看一个python2中的例子:
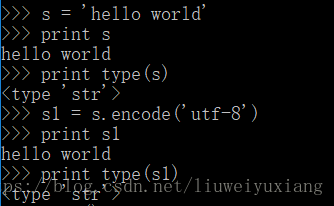
可见在python2中不区分字节字符串和文本字符串。
再看在python3中:
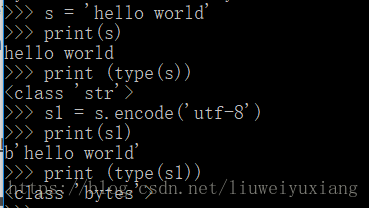
可见,字节字符串与文本字符是不同的。
字节字符串与文本字符串转换
name = 'laogaoyang'
nameBytes = name.encode('utf-8') # 字节
nameStr = nameBytes.decode('utf-8')# 字符串
print(name)
print(nameBytes)
print(nameStr)
















 6120
6120

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









