




肝了几个晚上,梳理总结了一份万字长文超详述hive企业级优化文章,也整理了一份
hive优化总结思维导图和hive优化详细PDF文档,有需要可关注公众号《大数据阶梯之路》找小编获取,学习和复习都是绝佳,公众号不断分享技术相关文章。话不多说,👇🏻下面就直接开讲吧!
更多精彩好文,首发在微信公众号《大数据阶梯之路》,欢迎关注

文章字数:13271字
预计阅读需:20分钟
一、问题背景
hive离线数仓开发,一个良好的数据任务,它的运行时长一般是在合理范围内的,当发现报表应用层的指标数据总是产出延迟,排查定位发现是有些任务执行了超10小时这样肯定是不合理的,此时就该想想如何优化ETL任务链路,主要从以下几个角度来考虑问题解决:
- 从数据任务本身hive逻辑代码出发,即hive逻辑优化,偏理解业务角度
- 从集群的资源设置出发,即hive参数调优,偏理解技术角度
- 从全局数据链路的任务设置出发,观测是否任务执行调度设置不合理
- 从数仓的数据易用性和模型复用性的角度出发,针对某些中间逻辑过程可以复用的就落地中间模型表
附上一份个人梳理总结的思维导图部分截图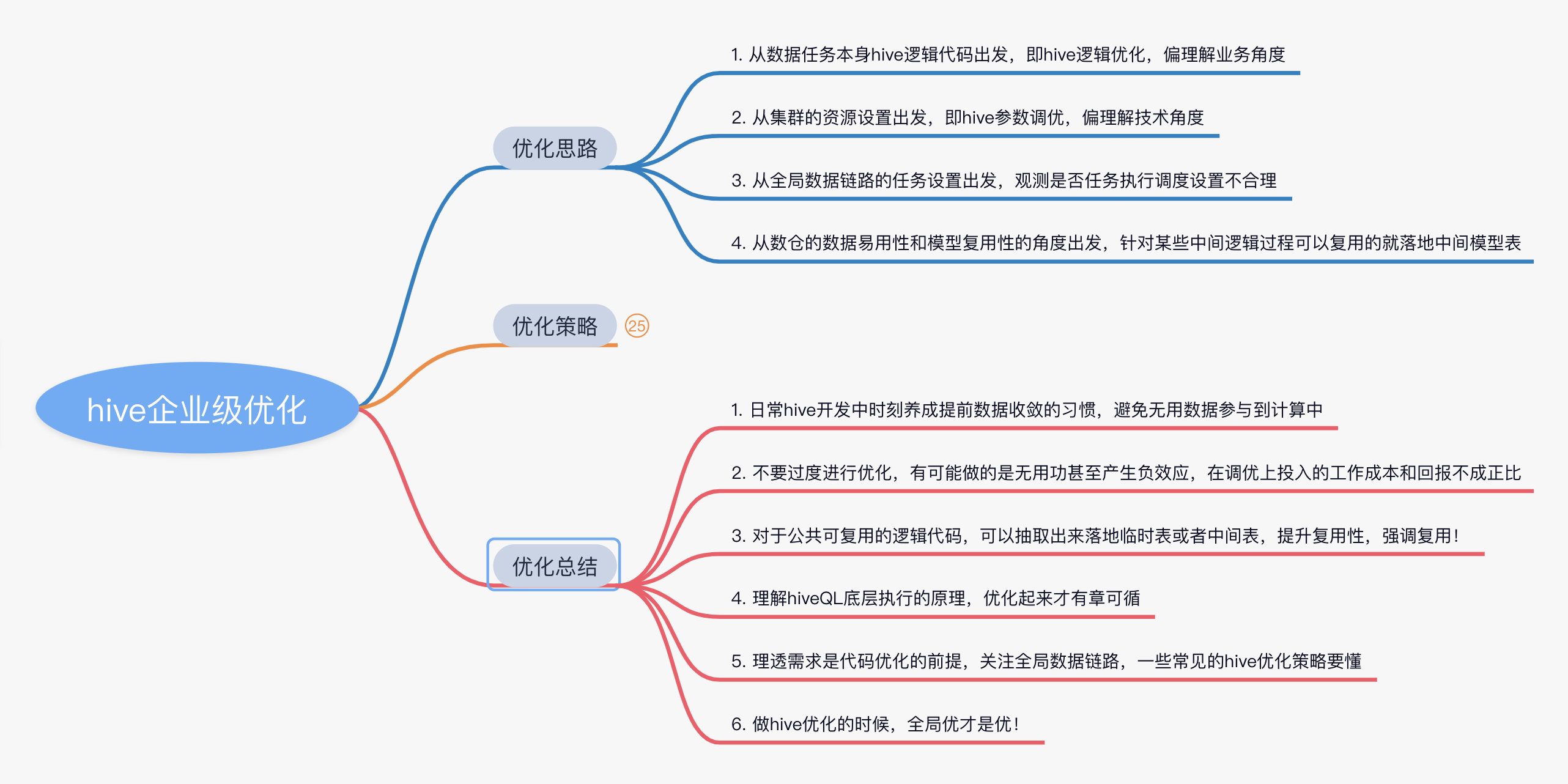
下面就先分享下常见的hive优化策略吧~ 会附带案例实践帮助理解
hive优化文章大纲
- 列裁剪和分区裁剪
- 提前数据收敛
- 谓词下推(PPD)
- 多路输出,减少表读取次数写多个结果表
- 合理选择排序
- join优化
- 合理选择文件存储格式和压缩方式
- 解决小文件过多问题
- distinct 和 group by
- 参数调优
- 解决数据倾斜问题
二、hive优化
1. 列裁剪和分区裁剪
裁剪 顾名思义就是不需要的数据不要多查。
尽量减少直接select * from table这种操作,首先可读性不好,根本不知道具体用到哪几个列,其次列选择多了也会增大IO传输;
分区裁剪就是针对分区表切记要加上分区过滤条件,比如表以时间作为分区字段,要加上分区筛选。
2. 提前数据收敛
在子查询中,有些条件能先过滤的尽量放在子查询里先过滤,减少子查询输出的数据量。
-- 原脚本
select
a.字段a,a.字段b,b.字段a,b.字段b
from
(
select 字段a,字段b
from table_a
where dt = date_sub(current_date,1)
) a
left join
(
select 字段a,字段b
from table_b
where dt = date_sub(current_date,1)
) b
on a.字段a = b.字段a
where a.字段b <> ''
and b.字段b <> 'xxx'
;
-- 优化脚本 (数据收敛)
select
a.字段a,a.字段b,b.字段a,b.字段b
from
(
select 字段a,字段b
from table_a
where dt = date_sub(current_date,1)
and 字段b <> ''
) a
left join
(
select 字段a,字段b
from table_b
where dt = date_sub(current_date,1)
and 字段b <> 'xxx'
) b
on a.字段a = b.字段a
;
3. 谓词下推(Predicate Pushdown)
谓词下推Predicate Pushdown是什么?简称PPD,指的是在不影响数据结果的情况下,将过滤表达式尽可能移动至靠近数据源的位置,以使真正执行时能直接跳过无关的数据,这样在map执行过滤条件,可以减少map端数据输出,起到了数据收敛的作用,降低了数据在集群上传输的量,节约了集群的资源,也提升了任务的性能。
hive默认是开启谓词下推该参数设置的,hive.optimize.ppd=true
所谓下推,即谓词过滤在map端执行;所谓不下推,即谓词过滤在reduce端执行。
关于谓词下推的规则,主要分为join的on条件过滤下推和where条件过滤下推,我整理了一张图方便理解。

核心判断逻辑:join的on条件过滤不能下推到保留行表中;where条件过滤不能下推到null补充表中。
-- 举例说明:以下脚本 on后面的a表条件过滤没有下推至map端运行而是在reduce端运行,where后面的b表条件过滤则有下推至map端运行
select
a.字段a,a.字段b,b.字段a,b.字段b
from table_a a
left join table_b b
on a.字段a <> '' -- a表条件过滤
where a.字段b <> 'xxx' -- a表条件过滤
;
谓词下推注意事项:
如果在表达式中含有不确定函数,整个表达式的谓词将不会被下推。例如下面脚本,则整个条件过滤都是在reduce端执行:
select a 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 605
605

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









