




 文章介绍了如何在STM32单片机上使用CUBE-AI工具,将Keras模型转换并部署到STM32F407ZGT6芯片上进行人类活动识别。通过STM32CubeMX配置环境,解决XCOMbug,并详细阐述了模型压缩、验证和部署的过程。
文章介绍了如何在STM32单片机上使用CUBE-AI工具,将Keras模型转换并部署到STM32F407ZGT6芯片上进行人类活动识别。通过STM32CubeMX配置环境,解决XCOMbug,并详细阐述了模型压缩、验证和部署的过程。
摘要:为什么可以在STM上面跑人工智能?简而言之就是通过X-Cube-AI扩展将当前比较热门的AI框架进行C代码的转化,以支持在嵌入式设备上使用,目前使用X-Cube-AI需要在STM32CubeMX版本7.0以上,目前支持转化的模型有Keras、TF lite、ONNX、Lasagne、Caffe、ConvNetJS。Cube-AI把模型转化为一堆数组,而后将这些数组内容解析成模型,和Tensorflow里的模型转数组后使用原理是一样的。
一、环境安装和配置
STM32CubeMX
MDK/IAR/STM32CubeIDE
F4/H7/MP157开发板
芯片平台:stm32F407ZGT6 flash:1024K ram:256K
二、AI神经网络模型搭建
这里使用官方提供的模型进行测试,用keras框架训练:
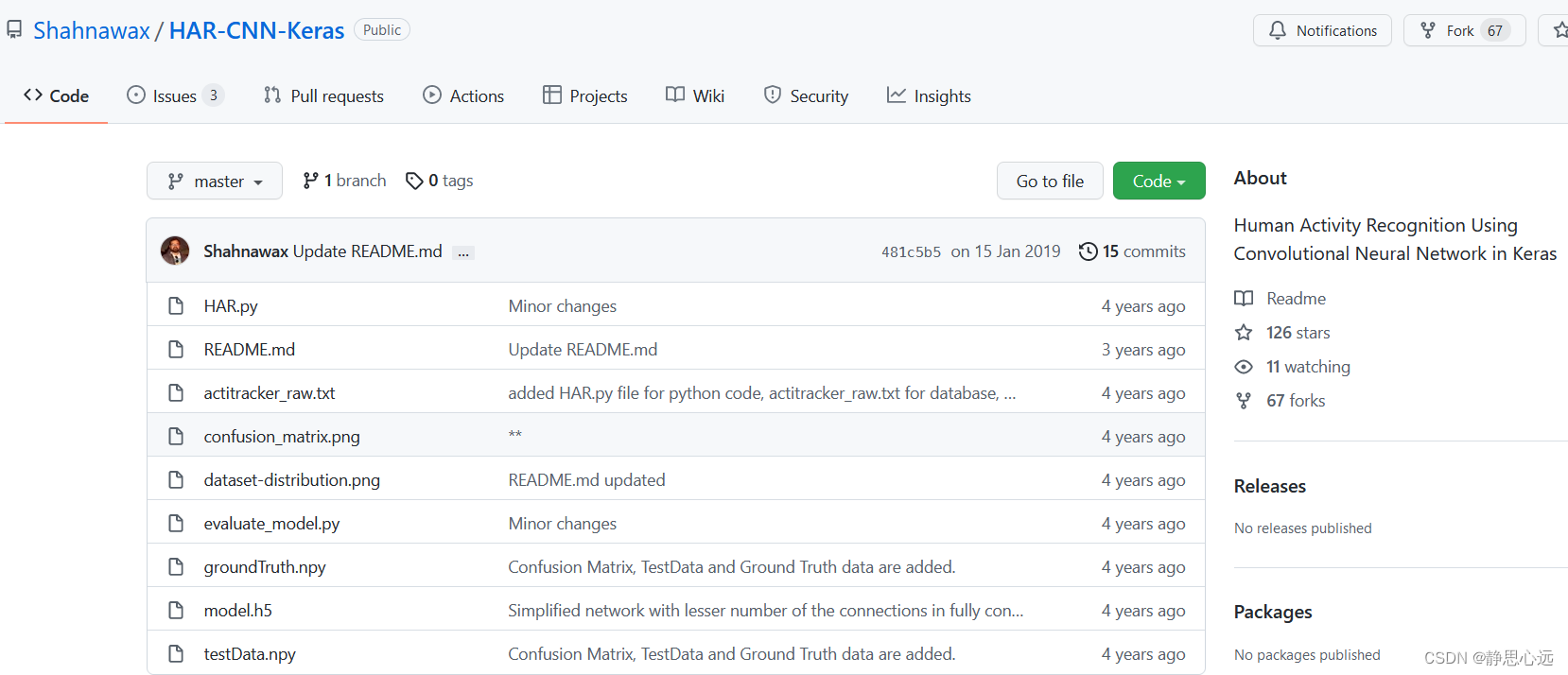
https://github.com/Shahnawax/HAR-CNN-Keras
没有的,我已下载好,直接拿走
链接:https://pan.baidu.com/s/1jbyBvYl2WNuWlmMwULOb-g
提取码:AI23
–来自百度网盘超级会员V5的分享
模型介绍
在Keras中使用CNN进行人类活动识别:此存储库包含小型项目的代码。该项目的目的是创建一个简单的基于卷积神经网络(CNN)的人类活动识别(HAR)系统。该系统使用来自3D加速度计的传感器数据,并识别用户的活动,例如:前进或后退。HAR意为Human Activity Recognition (HAR) system,即人类行为识别。这个模型是根据人一段时间内的3D加速度数据,来判断人当前的行为,比如走路,跑步,上楼,下楼等,很符合Cortex-M系列MCU的应用场景。使用的数据如下图所示。
在Keras中使用CNN进行人类活动识别:此存储库包含小型项目的代码。该项目的目的是创建一个简单的基于卷积神经网络(CNN)的人类活动识别(HAR)系统。该系统使用来自3D加速度计的传感器数据,并识别用户的活动,例如:前进或后退。HAR意为Human Activity Recognition (HAR) system,即人类行为识别。这个模型是根据人一段时间内的3D加速度数据,来判断人当前的行为,比如走路,跑步,上楼,下楼等,很符合Cortex-M系列MCU的应用场景。使用的数据如下图所示。
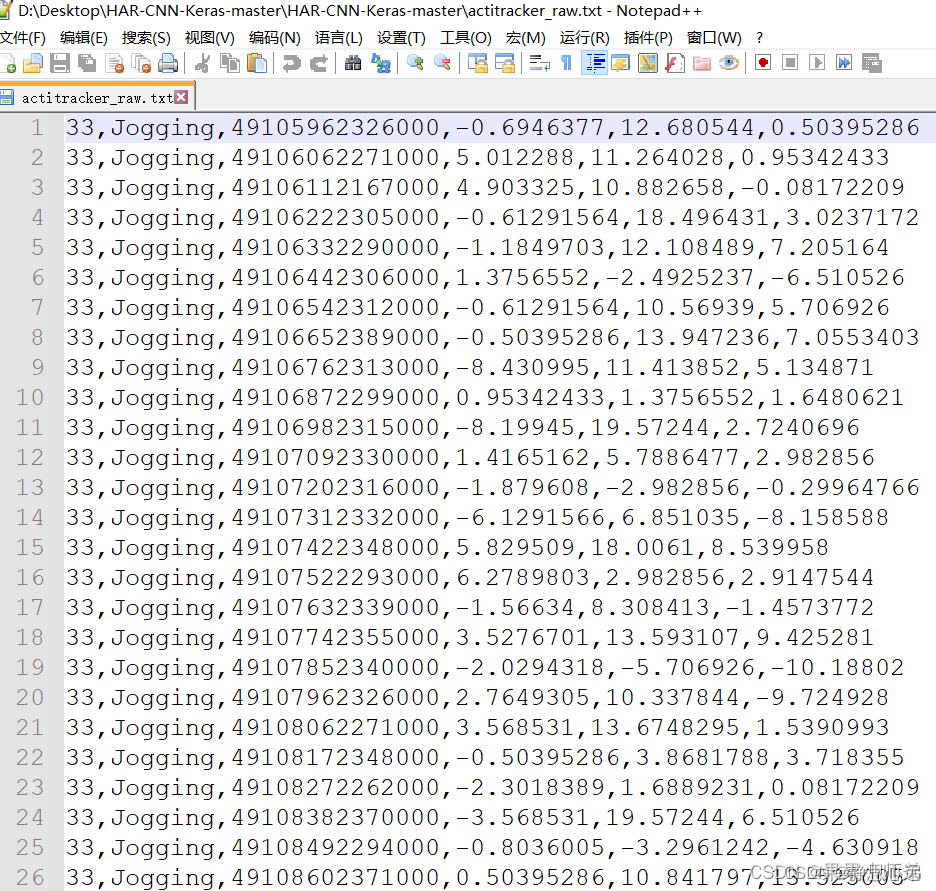
存储库包含以下文件
- 1.HAR.py,Python脚本文件,包含基于CNN的人类活动识别(HAR)模型的Keras实现,
- 2.actitracker_raw.txt、包含此实验中使用的数据集的文本文件,
- 3.model.h5,一个预训练模型,根据训练数据进行训练,
- 4.evaluate_model.py、Python 脚本文件,其中包含评估脚本。此脚本在提供的 testData 上评估预训练 netowrk 的性能,
- 5.testData.npy,Python 数据文件,包含用于评估可用预训练模型的测试数据,
- 6.groundTruth.npy,Python 数据文件,包含测试数据的相应输出的地面真值和
- 7.README.md.
这么多文件不要慌,模型训练后得到model.h5模型,才是我们需要的。
三、新建工程
1.这里默认大家都已经安装好了STM32CubeMX软件。
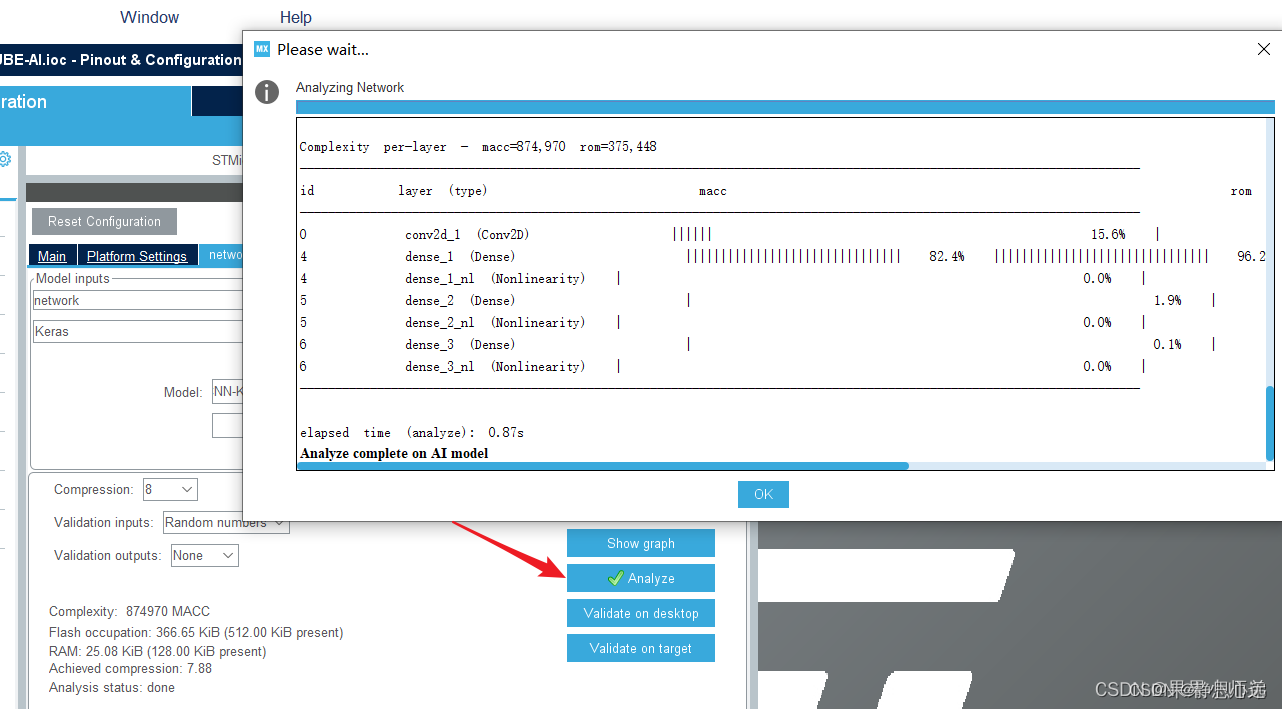
在STM32上验证神经网络模型(HAR人体活动识别),一般需要STM32F3/F4/L4/F7/L7系列高性能单片机,运行网络模型一般需要3MB以上的闪存空间,一般的单片机不支持这么大的空间,CUBEMX提供了一个压缩率的选项,可以选择合适的压缩率,实际是压缩神经网络模型的权重系数,使得网络模型可以在单片机上运行,压缩率为8,使得模型缩小到366KB,验证可以通过;
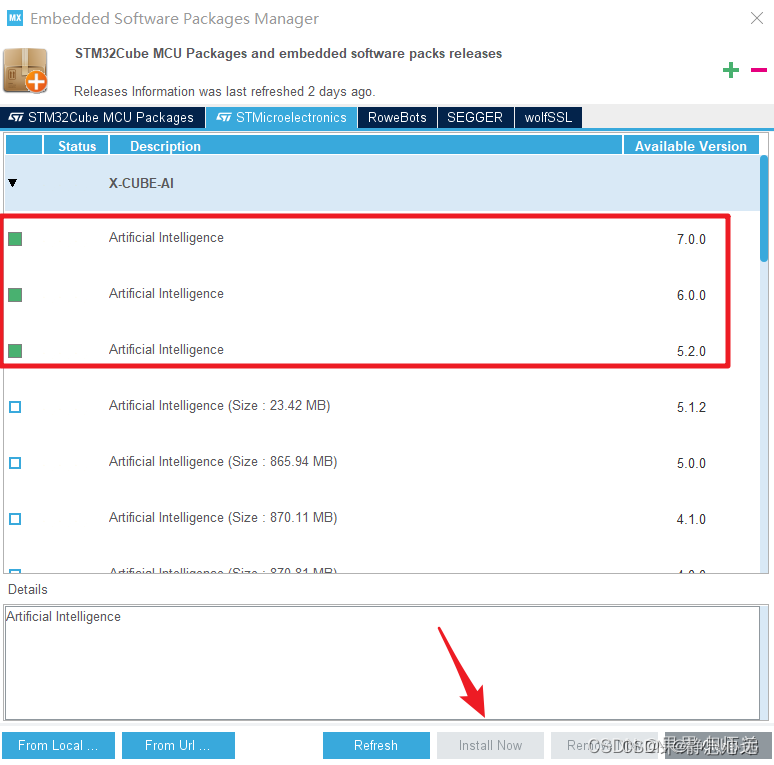
然后按照下面的步骤安装好CUBE.AI的扩展包
这个我安装了三个,安装最新版本的一个版本就可以。
接下来就是熟悉得新建工程了
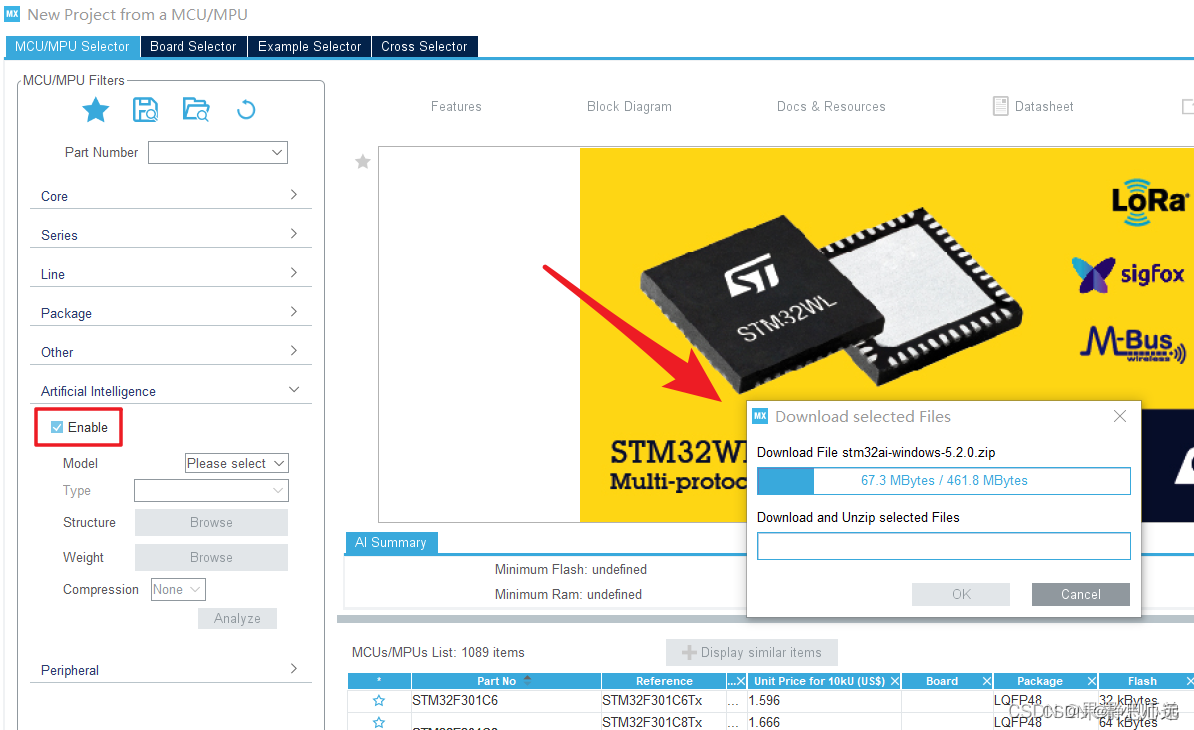
因为安装了AI的包,所以在这个界面会出现artificial intelligence这个选项,点击Enable可以查看哪一些芯片支持AI
接下来就是配置下载接口和外部晶振了。
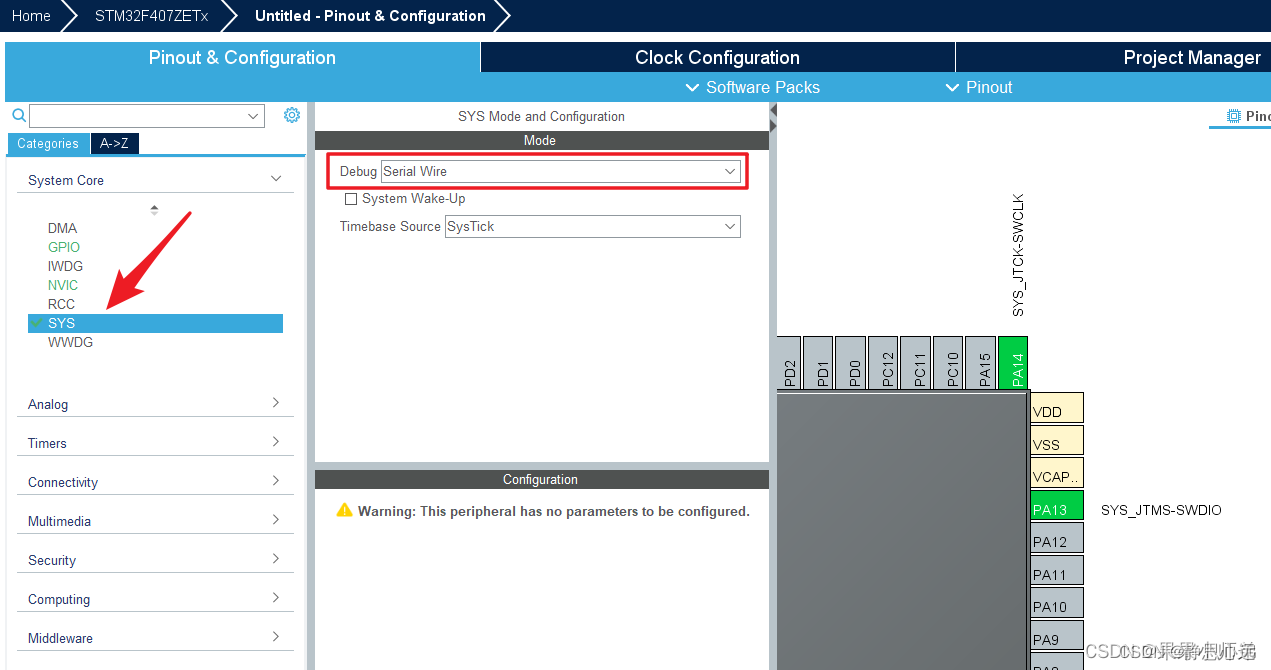
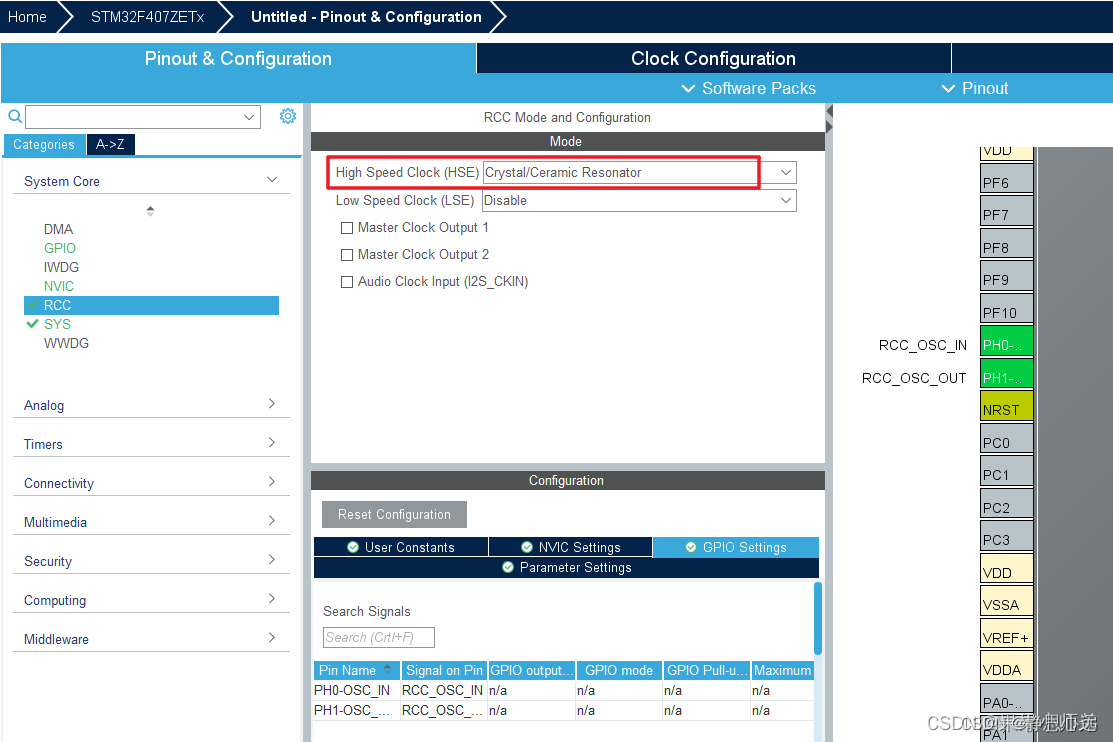
然后记得要选择一个串口作为调试信息打印输出。
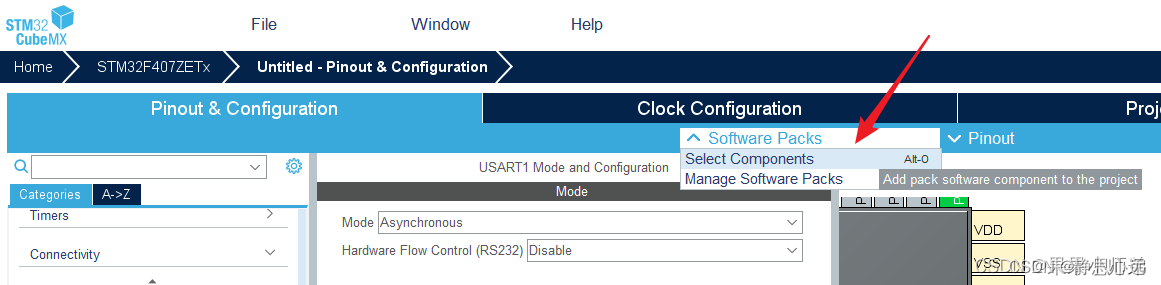
选择Software Packs,进入后把AI相关的两个包点开,第一个打上勾,第一个选择Validation。
- System Performance工程:整个应用程序项目运行在STM32MCU上,可以准确测量NN推理结果,CP∪U负载和内存使用情况。使用串行终端监控结果(e.g.Tera Term)。
- Validation工程:完整的应用程序,在桌面PC和基于STM32 Arm Cortex-m的MCU嵌入式环境中,通过随机或用户测试数据,递增地验证NN返回的结果。与 X-CUBE-A验证工具一起使用。
- Application Template工程:允许构建应用程序的空模板项目,包括多网络支持。
之后左边栏中的Software Packs点开,选择其中的X-CUBE-AI,弹出的Mode窗口中两个复选框都打勾,Configuration窗口中,点开network选项卡。
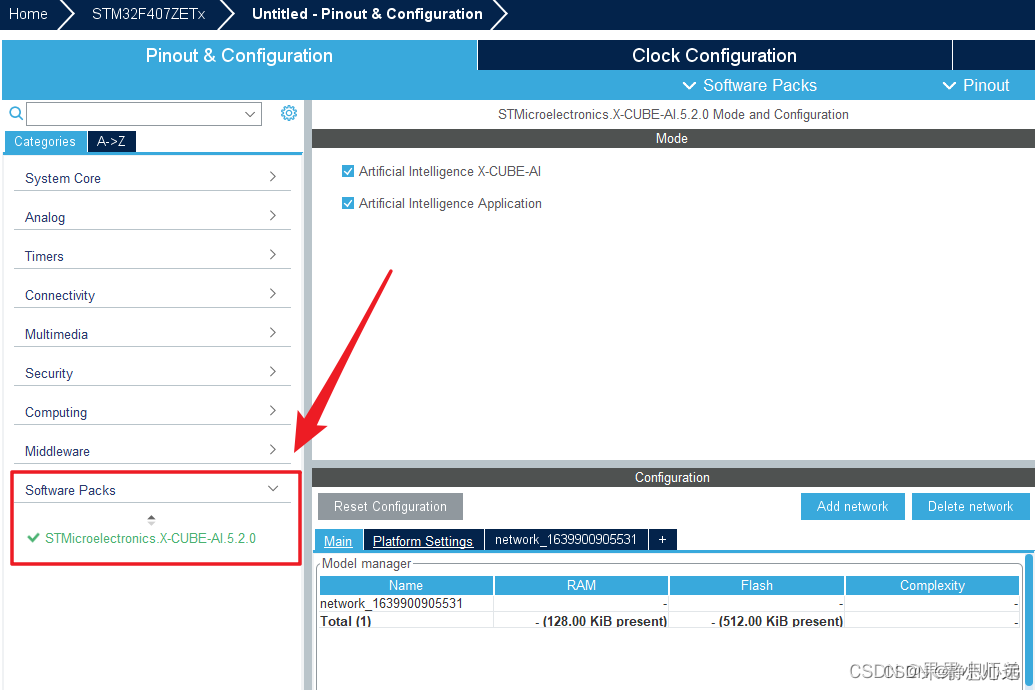
选择刚刚配置的串口作为调试用。
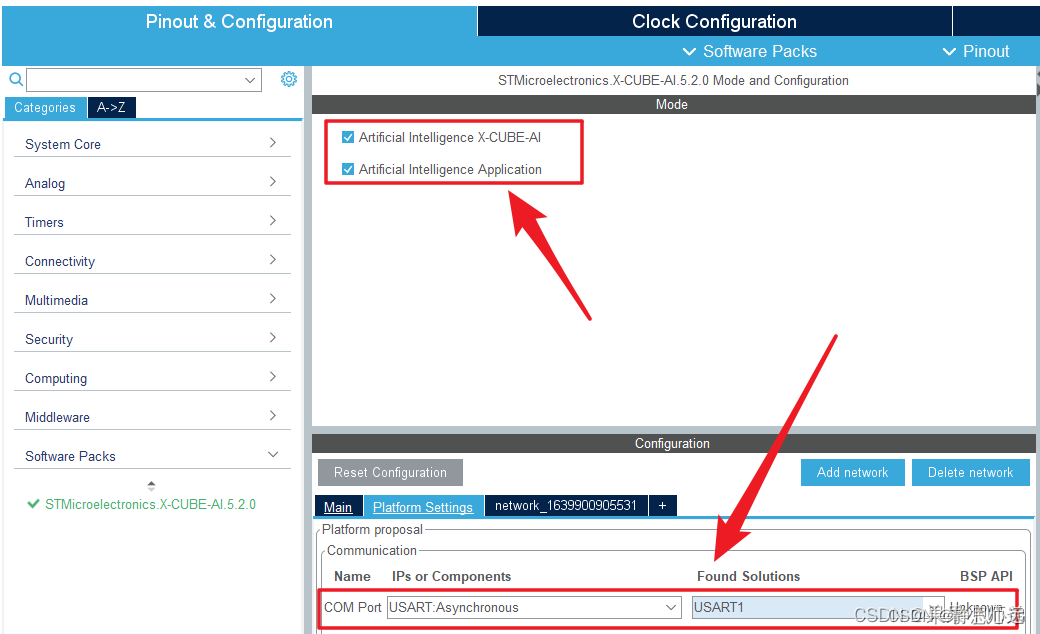
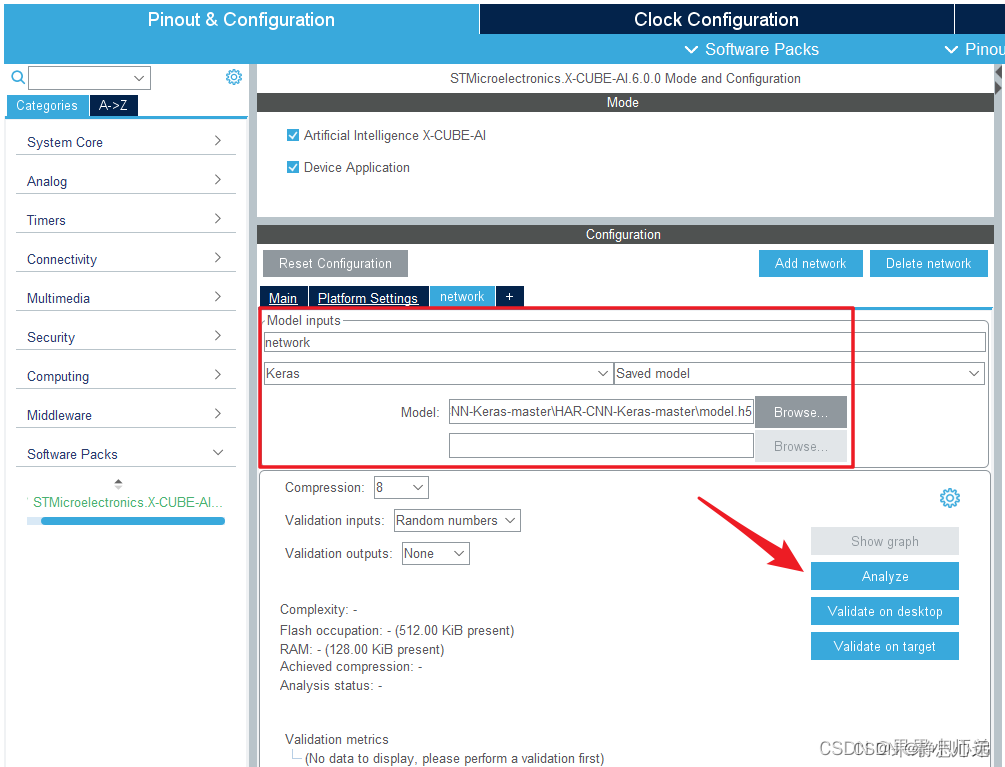
点击add network,选择上述下载好的model点h5模型,选择压缩倍数8;
点击分析,可从中看到模型压缩前后的参数对比
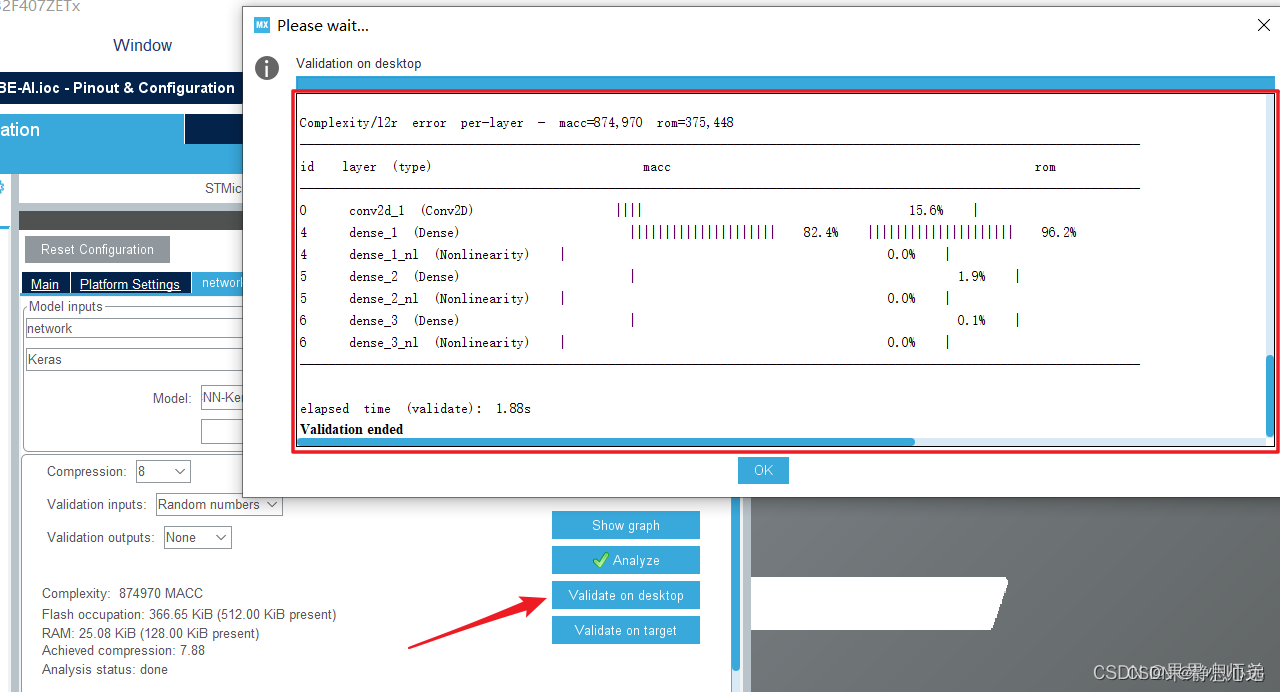
点击validation on desktop 在PC上进行模型验证,包括原模型与转换后模型的对比,下方也会现在验证的结果。
致此,模型验证完成,下面开始模型部署
四、模型转换与部署
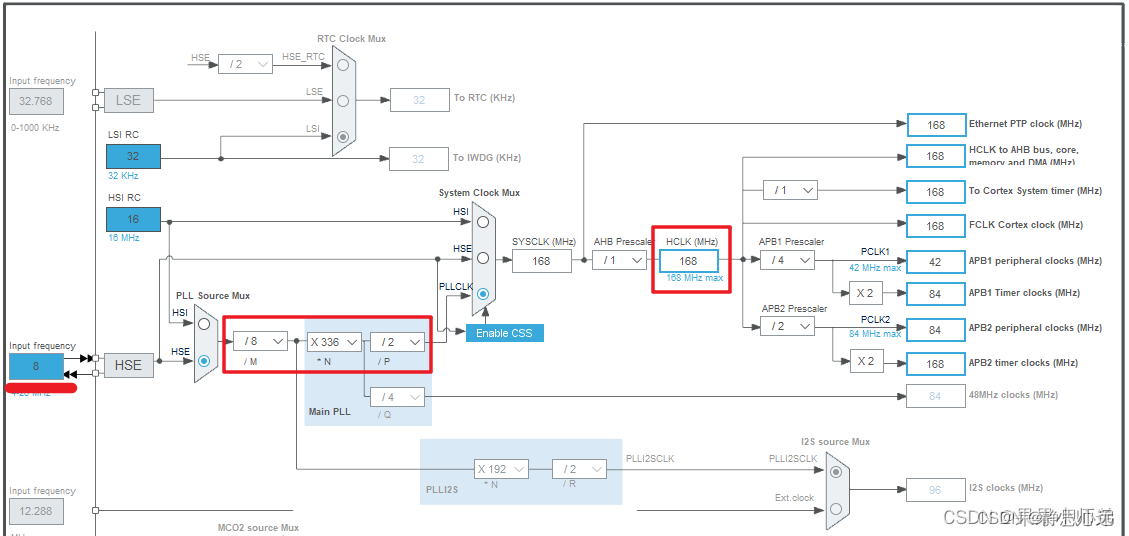
时钟配置,系统会自动进行时钟配置。按照你单片机的实际选型配置时钟就可以了。
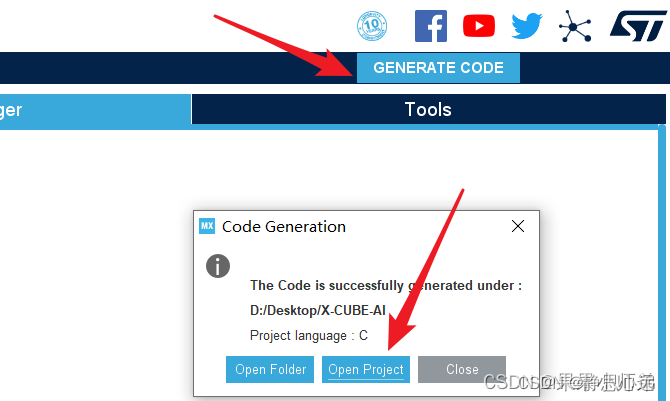
最后点击GENERATE CODE生成工程。
然后在MDK中编译链接。
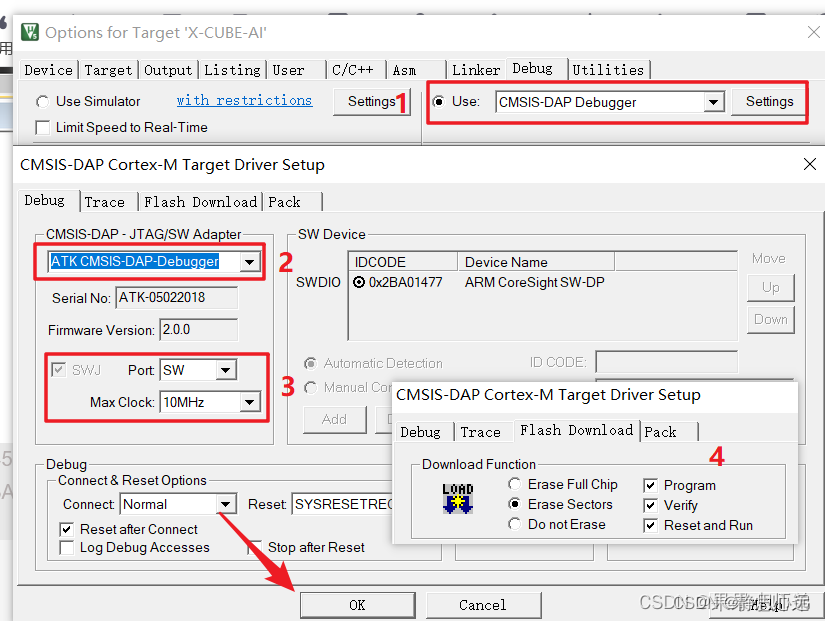
选择好下载器后就可以下载代码了。
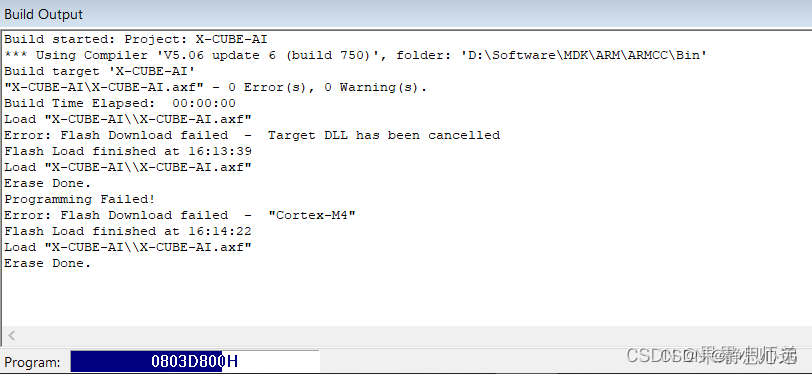
然后打开串口调试助手就可以看到一系列的打印信息了。
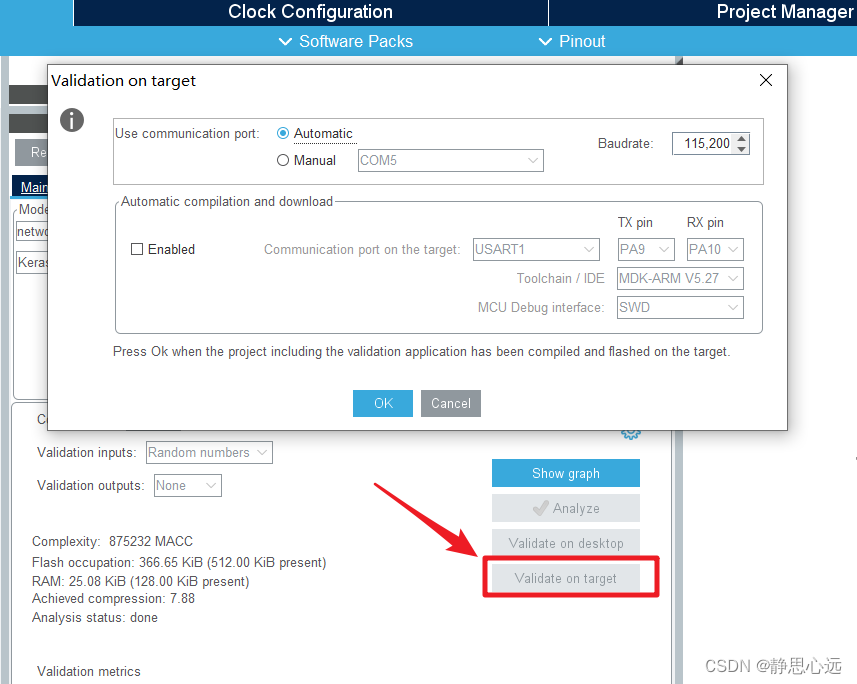
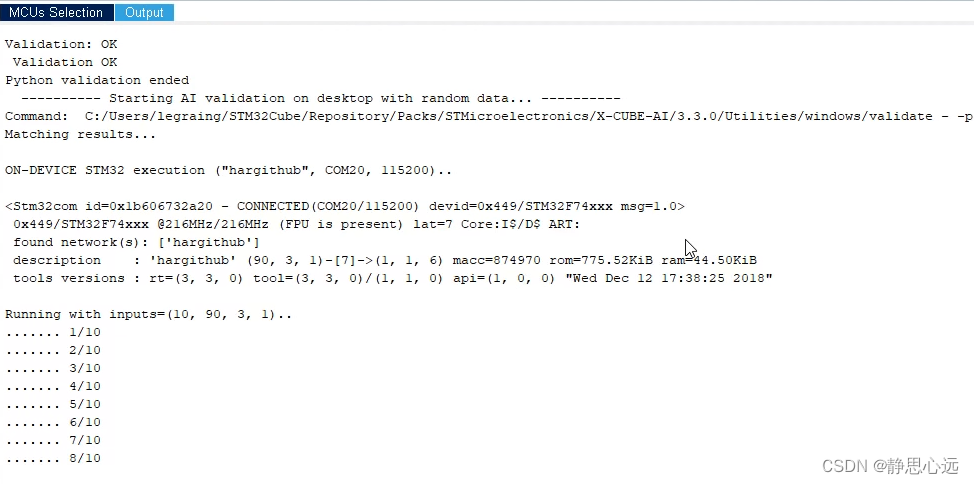
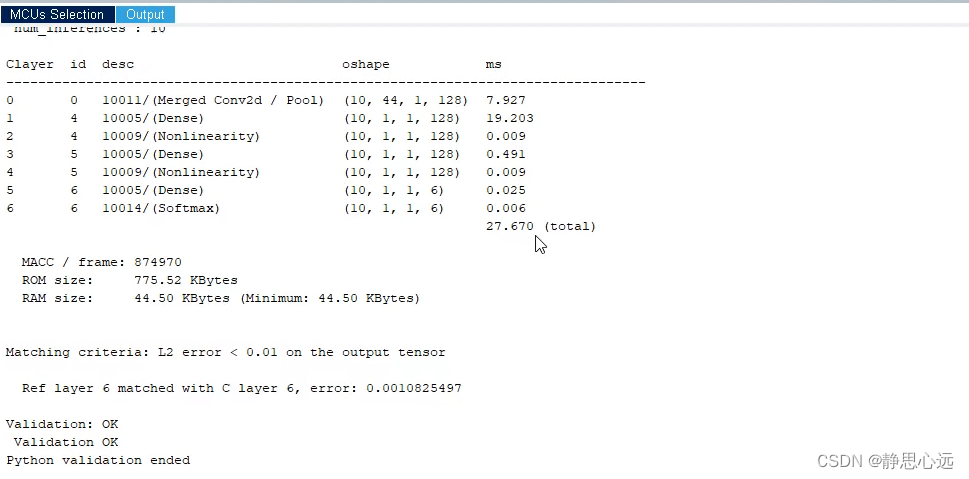
代码烧写在芯片里后,回到CubeMX中下图所示位置,我们点击Validate on target,在板上运行验证程序,效果如下图,可以工作,证明模型成功部署在MCU中。
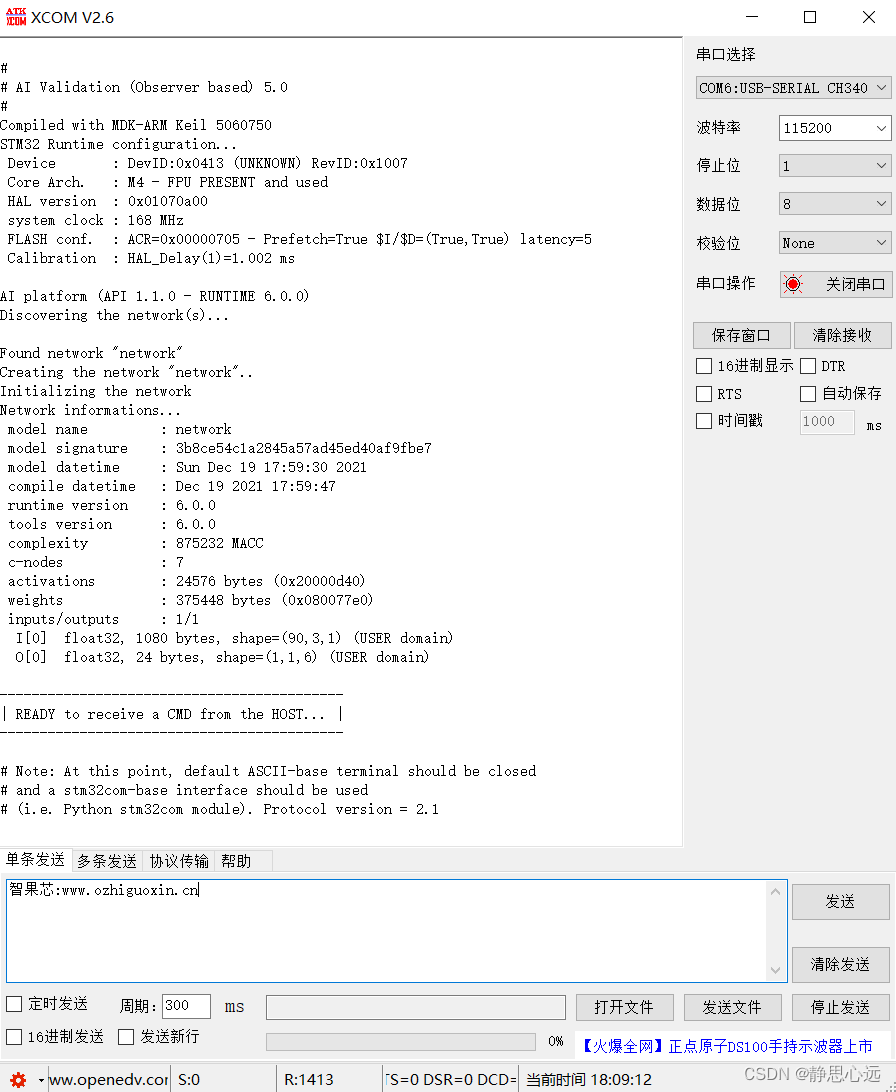
XCOM
链接:https://pan.baidu.com/s/1DKKGt61qQ5V7e5Od86-BNQ
提取码:AI23
–来自百度网盘超级会员V5的分享
bug解决
L6221E: Execution region ER_RO with Execution range [0x00000000,0x000001。
学习stm32的时候,使用keil5编译编译空的工程时候遇到的问题,在网上找了很久没找到答案,自己瞎操作解决了问题,其实也不知道有没有解决,仅供参考。
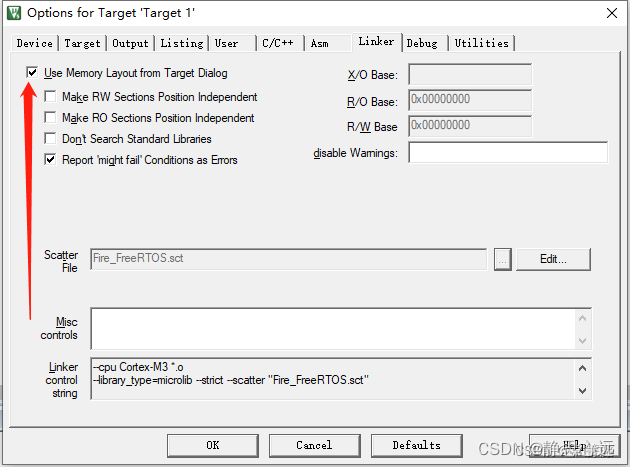
只需要将上图位置打勾,再编译即可。


















 667
667

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









