




 本文深入解析并发编程的基础,包括线程的启动与终止,锁的升级机制,从轻量级锁到重量级锁的转变,以及Java并发工具类如ReentrantLock、Semaphore的使用。探讨了synchronized关键字的底层实现,以及volatile如何确保数据的可见性。
本文深入解析并发编程的基础,包括线程的启动与终止,锁的升级机制,从轻量级锁到重量级锁的转变,以及Java并发工具类如ReentrantLock、Semaphore的使用。探讨了synchronized关键字的底层实现,以及volatile如何确保数据的可见性。
一、并发基础
1、历史:
真空管/穿孔打卡: 计算机大部分时间处于空闲状态;
晶体管/批处理操作问题 :解决了CPU问题,但有IO阻塞问题;
集成电路/多道程序设计: 引入进程概念;引入线程(轻量级的进程) , CPU单核到多核,真正意义达到并行计算
2、基础:
所有阻塞的方法,都可能会抛出InterruptedException;
线程的启动用start方法:可以通看源码的方式来了解;下载hotspot源码;
线程的合适的终止方法:Thread.interrupt() 把isInterrupted设置成true; 或者手动定义run循环中的结束标志;
线程的重置方法,表示当前收到中断信号,但是不会立即中止自己,并且让外部知道中止之前是false;
① Thread.interrupted() 线程状态复位,回到初始状态,即isInterrupted 返回false;;
② 对一个阻塞性的线程(wait sleep join 有条件等待的,提供了interrupt主动结束方法) 进行中断Thread.interrupt() 后,会抛出InterruptedException异常,会进行线程状态复位,即isInterrupted 返回false,同时给应用一个机会,可以自己选择结束run()中的方法,或者不管;
synchronized的控制力度和修饰的方法有关,可以是 实例方法,静态方法,代码块;
实例方法: 不同的线程,访问同一实例的方法是有锁竞争的;访问不同实例,是没有锁竞争的;
静态方法:不同的线程,只要访问到该方法都有锁竞争;
代码块: 取决于代码块的同步对象的范围;
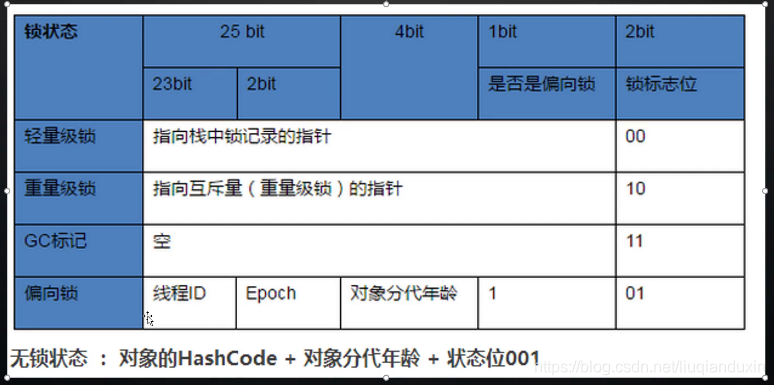
锁的存储: 对象在内存中的布局,对象头32位(MarkWord),有存储锁的信息;锁,具备共享的条件, 互斥的条件;
无锁>偏向锁>轻量锁 >重要锁(真正意义上的加锁);
Java 1.6 之前,synchronized基于重量级锁来实现,既然保证数据安全,也要保证性能;
synchronized(lock){
//同步代码块
}
假如有两个线程ThreadA和ThreadB
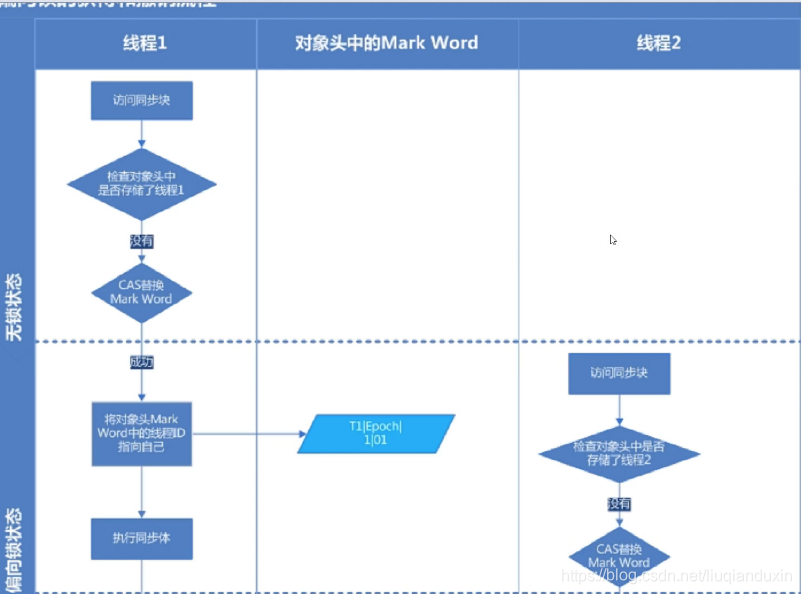
1、只有ThreadA去方法(大部分情况)同步代码块; 引入了 偏向锁(cas乐观锁)
lock锁对象中记录了当前的线程id ,以及 偏向锁标记1;偏向锁有撤销以及全局安全点的时候批量撤销,Epoch值类似版本信息;
2、ThreadA和 ThreadB交替访问;引入了 轻量锁,通过自旋方式;(自旋锁)
绝大数线程在获得锁以后,会很快释放锁;另外一个线程可以主动轮询获得锁的过程即自旋;
自旋会占用 CPU资源,在指定自旋次数后,还 没有获得轻量级锁,膨胀成重量级锁,则进行阻塞;
3、 ThreadA和 ThreadB同时访问;引入了重量锁,阻塞;(重量级锁mutex)
升级到重量级之后,没有获得锁的线程会被阻塞blocked状态;
锁对象头上有监视器,monitor -> Mutexlock(互斥锁),重量级
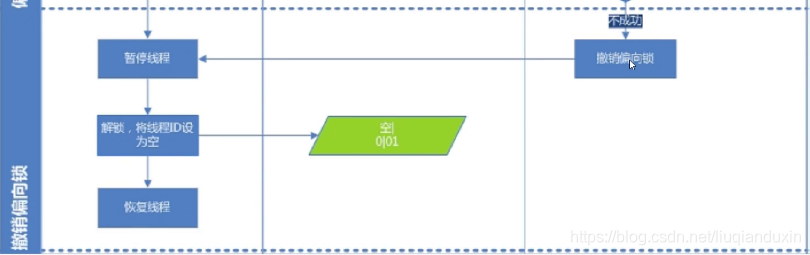
流程:阶段1 线程ThreadA,访问同步块,CAS当前锁对象的对象头字段的线程id,如果没有,则标记ThreadA,以及偏向锁;阶段2 如果线程ThreadA,同步块还没执行完,这时ThreadB去访问同步块,则会进行锁升级,变成轻量锁;如果如果线程ThreadA,同步块已执行完(锁对象的对象头不会主动释放线程ID),这时ThreadB去访问同步块,CAS失败,发起撤销偏向锁动作,那ThreadA会暂停线程,解锁,将线程ID设为空,恢复线程;
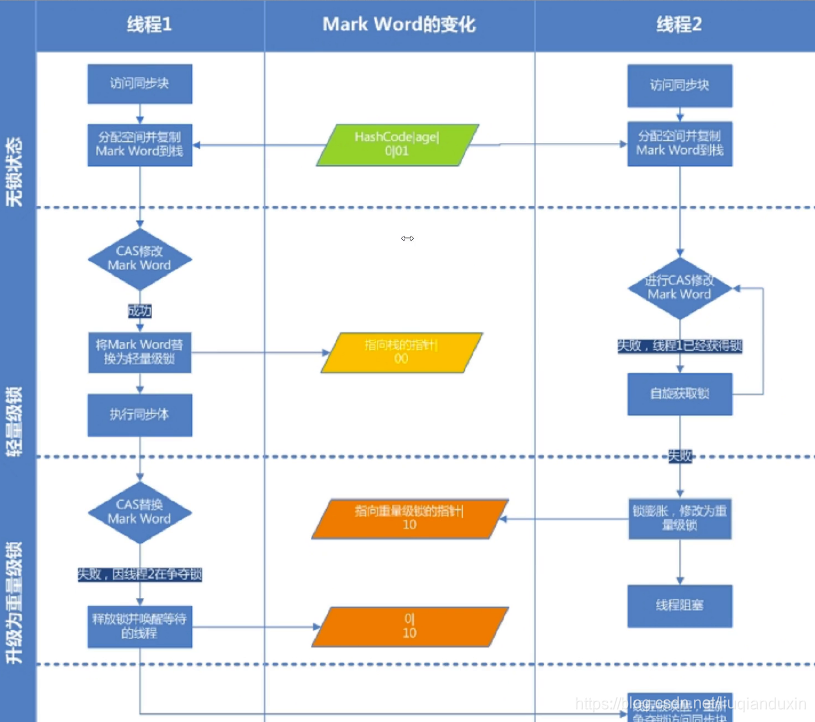
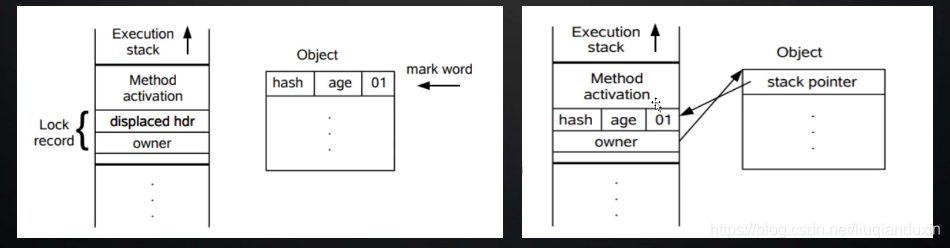
轻量级锁指针的变化示意图;两幅图显示的变化过程,每幅图的左边是线程对象,右边是锁对象;
重量级锁的过程 ,基于monitorenter和monitorexit指令;
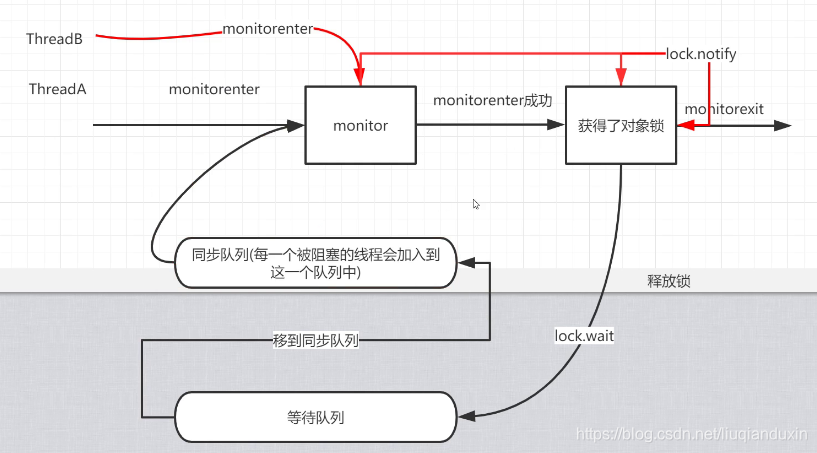
sleep: 释放CPU资源,不释放锁;
wait: 实现线程阻塞;释放当前同步锁;释放CPU资源
notify/notifyall : 唤醒
3、 线程安全性
volatile 保证可见性;可通过hsdis插件查看;
现象:如果没有这个修饰符,threadA 对一个变量 var=5,另外一个线程threadA修改这个变量 var=6,在threadA看见的仍然是var=5;
原理:volatile 会增加Lock汇编指令;
可见性的分析:①硬件层面:
cpu增加高速缓存 L1/L2/L3;会带来缓存不一致问题,通过缓存一致性协议(MESI)来解决;MESI又带了通信问题,cpu0给cpu1发送指令等待ACK确认会阻塞,所以引入了storebuffer,将指令写入到storebuffer中;但是还是不能解决可见性问题,CPU提供了内存屏障(硬件层面没法彻底解决不了可见性问题,由JMM来调用内存屏障指令来彻底解决),强制将storebuffer更新到主内存;
引入线程和进程;
指令重排序;
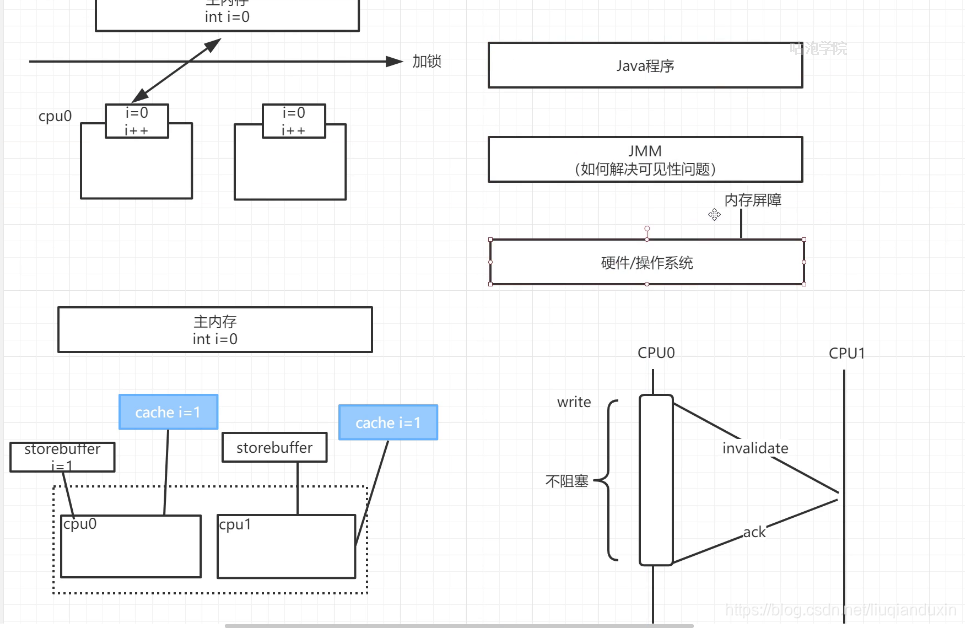
② jmm层面,语言级别抽象内存模型,解决有序性 ,可见性;(可见性的根本原因:高速缓存,重排序):
volatile、解决可见性,禁止指令重排序来达到可见性效果;不解决原子性问题;
synchronized、可解决原子性、有序性、可见性;
final、
源代码》编译器的重排序》cpu层面的重排序》最终执行的指令
不是所有的程序都会进行重排序,不管怎么重排序,单线程的执行结果不能变:数据依赖规则;
在单线程允许重排序的条件下,解决多线程重排序导致的问题,引入了jmm -> 内存屏障,包括编译器级别(语言级别volatile )和cpu层面(内存屏障)
Happens-Before: A happens-before B,认为A的结果,B是可见的;
那些操作会建立happens-before原则:① 程序的顺序规则(单个方法里的语句顺序执行) ②volatile规则 ③传递性规则 1 happens-before2 , 2 happens-before3, 那么 1 happens-before 3 ④ start规则 主线程修改了变量A,然后再启动子线程,那边新的变量A的值会体现到子线程中; ⑤join规则(阻塞主线程) ,子线程修改变量A,会体现到主线程中;⑥synchronized锁的规则(监视器),线程A修改的内容,会体现到后续拿到锁的线程B中;
4、java.util.concurrent
Lock
4.1 重入锁ReentrantLock:线程再次获得锁,不需要抢占锁,记入次数即可 eg 比如2个方法,都是同一个锁对象,同一个线程进入第2个方法时,就只记录进入次数,不需要再次抢占锁;
多个线程竞争锁的时候,其他线程怎么办? 会阻塞;
同步工具AQS( AbstractQueuedSynchronizer) ,1.独占 > 互斥 2. 共享 》读写锁
AQS基本实现:state 锁标记,0是 无锁;>=1 是 有锁状态;
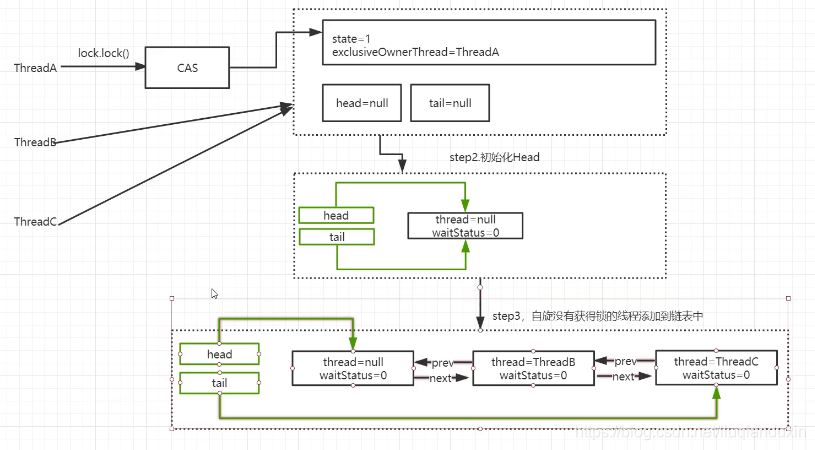
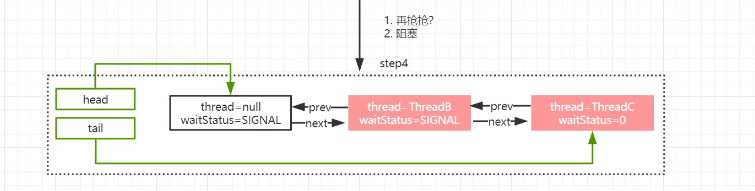
公平锁和非公平锁区别:非公平锁,允许线程插队,优先获得锁;同理,公平锁,如果发现有等待队列,就不允许尝试获得锁;
4.2 读写锁ReentrantReadWriteLock: 读写、写写是互斥,会阻塞;读读不会阻塞;
参见 https://www.cnblogs.com/memoryXudy/p/readWriteMathod.html
4.3 Condition,生产者和消费者的通信;
4.4 CountDownLatch 共享锁;使用场景 计数器,await会阻塞所有线程,计数结束后,会唤醒所有被阻塞的线程;
4.5 Semaphore 共享锁;应用场景 限流;公平和非公平;
4.6 CyclicBarrier 可以使得一组线程达到一个同步点之前阻塞,类似CountDownLatch
4.7 ConcurrentHashMap , jdk1.8 取消了sengment的设计;增加了红黑树的设计;初始化了长度16的数组,每个长度的元素以链表存储,如果长度超过;
4.8 阻塞队列 :FIFO的队列;线程级别的生产和消费者模型;
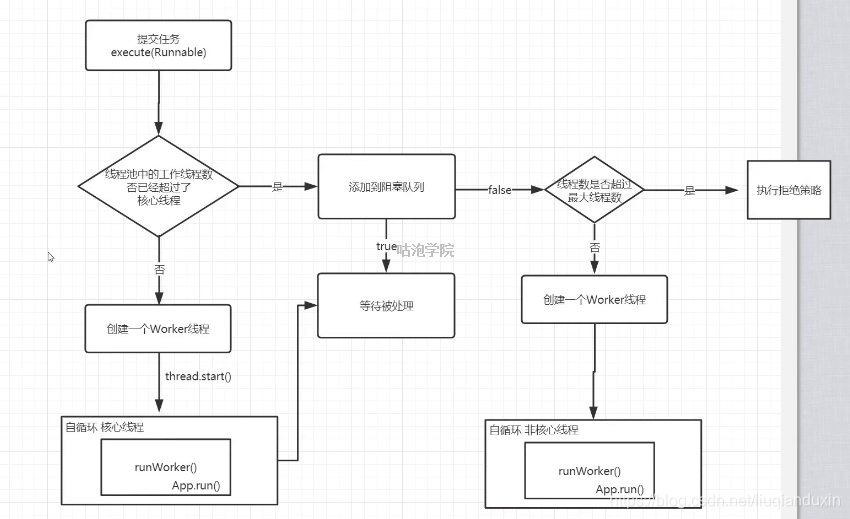
4.9 线程池实现原理: 复用已有资源;控制资源的数量;
一、
Thread 的初始化属性group,daemon,priority 来源于创建该对象的线程;
Runnable 执行的取决于 Runnable.run()方法;
Executor : void execute(Runnable command);
ExecutorService : 增加了shutdown,shutdownNow,submit,invokeAll,invokeAny;
Executors : 工厂方法用于创先线程池,返回的线程池都实现了ExecutorService 接口
ThreadPoolExecutor的工作原理: <corepoolsize,先创建线程运行任务 ;>=corepoolsize,放到队列中; 如果队列已满,且池中线程<maxpoolsize,则创建新的线程去跑新的任务,这就意味着在 队列已满 && 线程未达到最大的场景下,后面来的任务先跑;
悲观锁synchronized,ReentrantReadWriteLock ,适合场景:读少,写多,已发生冲突的场景;因为CAS 自旋的概率比较大,浪费cpu资源;
乐观锁 version或者 CAS(java.util.concurrent.AtomicInteger)操作 适合场景:读多,写少,冲突小的场景;如果用synchronized同步锁进行线程阻塞和唤醒切换以及用户态内核态切换回浪费cpu消耗,CAS基于硬件,不进入内核,不进行线程切换,自旋几率较少,可以获得更高性能;
二、锁只能保证同一时间只有一个线程执行,但不能保证后续线程竞争执行的顺序;
三、synchronized(String.intern() ) 字符串锁;

















 1260
1260

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









