







 本文介绍了机器学习的三大要素:数据、模型和算法。数据通过向量空间模型转化为计算机可处理的形式,有标注数据用于指导模型训练。模型是训练的结果,可以视为一个函数,算法则是确定模型参数的过程。有监督学习中,算法的目标是最小化损失函数,以找到最佳模型参数。
本文介绍了机器学习的三大要素:数据、模型和算法。数据通过向量空间模型转化为计算机可处理的形式,有标注数据用于指导模型训练。模型是训练的结果,可以视为一个函数,算法则是确定模型参数的过程。有监督学习中,算法的目标是最小化损失函数,以找到最佳模型参数。
机器学习三要素包括数据、模型、算法。简单来说,这三要素之间的关系,可以用下面这幅图来表示:
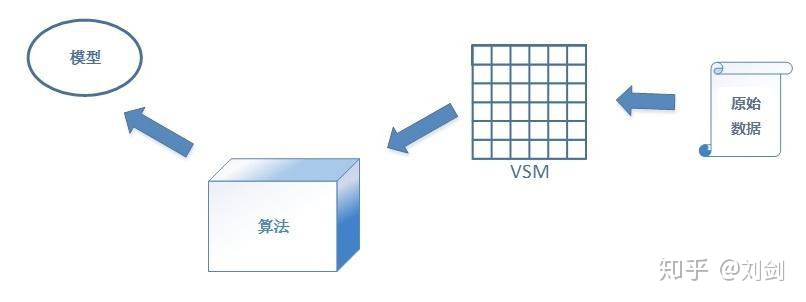
总结成一句话:算法通过在数据上进行运算产生模型。
下面我们先分别来看三个要素。
数据
关于数据,其实我们之前已经给出了例子。
源数据
上一篇中,图1老鼠和其他动物和图2小马宝莉六女主就是现实中的两份样本集合。如果我们要训练“老鼠分类器”,或者做“小马种族聚类” 分析的话,它们就是原始数据(Raw Data)。
不过,我们之前也说了,计算机能够处理的是数值,而不是图片或者文字。
向量空间模型和无标注数据
那么,我们就需要构建一个向量空间模型(Vector Space Model,VSM)。VSM 负责将格式(文字、图片、音频、视频)转化为一个个向量。
然后开发者把这些转换成的向量输入给机器学习程序,数据才能够得到处理。
比如图2小马宝莉中的6为女主角,我们要给她们做聚类,而且已经知道了,要用她们的两个特征来做聚类,这两个特征就是:独角和翅膀。
那么我们就可以定义一个二维的向量 A=[a_1,a_2]。a_1 表示是否有独角,有则 a_1 = 1, 否则 a_1 = 0。而 a_2 表示是否有翅膀。
那么按照这个定义,我们的6匹小马最终就会被转化为下面6个向量:
这样,计算机就可以对数据 X_1,……,X_6 进行处理了。这6个向量也就叫做这份数据的特征向量(Feature Vector)。
这是无标注数据。
有标注数据
和无标注对应的是有标注。
数据标注简
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 973
973

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









