







缓存
简介
查询:一次次连接数据库,消耗资源。
将一次查询的结果,暂存到一个可以直接渠道的地方 —> 内存,即缓存。
这样,我们再次查询相同数据的时候直接走缓存,就不用走数据库了
- 什么是缓存【catch】?
- 存在内存中的临时数据
- 将用户经常查询的数据放在缓存(内存)中,用户去查询数据就不用从磁盘上(关系型数据库数据文件)查询,从缓存中查询,从而提高查询效率,解决了高并发系统的性能问题。(三高:高并发,高可用,高性能)
- 为什么使用缓存?
- 减少和数据库的交互次数,减少系统开销,提高系统效率。
- 什么样的数据能使用缓存?
- 经常查询并且不经常改变的数据。
MyBatis缓存
MyBatis包含了一个非常强大的查询缓存特性,它可以非常方便的定制和配置缓存。缓存可以极大的提升查询效率。
MyBatis系统中默认定义了两级缓存,一级缓存和二级缓存
-
默认情况下:只有一级缓存开启。(SqlSession级别的缓存,也称为本地缓存)
-
二级缓存需要手动开启和配置,也是基于namespace级别的缓存
-
为了提高拓展性,MyBatis定义了缓存接口Catch。我们可以通过实现catch接口来自定义二级缓存。
// // Source code recreated from a .class file by IntelliJ IDEA // (powered by FernFlower decompiler) // package org.apache.ibatis.cache; import java.util.concurrent.locks.ReadWriteLock; public interface Cache { String getId(); void putObject(Object var1, Object var2); Object getObject(Object var1); Object removeObject(Object var1); void clear(); int getSize(); default ReadWriteLock getReadWriteLock() { return null; } }
缓存
MyBatis 内置了一个强大的事务性查询缓存机制,它可以非常方便地配置和定制。 为了使它更加强大而且易于配置,我们对 MyBatis 3 中的缓存实现进行了许多改进。
默认情况下,只启用了本地的会话缓存,它仅仅对一个会话中的数据进行缓存。 要启用全局的二级缓存,只需要在你的 SQL 映射文件中添加一行:
<cache/>基本上就是这样。这个简单语句的效果如下:
- 映射语句文件中的所有 select 语句的结果将会被缓存。
- 映射语句文件中的所有 insert、update 和 delete 语句会刷新缓存。
- 缓存会使用最近最少使用算法(LRU, Least Recently Used)算法来清除不需要的缓存。
- 缓存不会定时进行刷新(也就是说,没有刷新间隔)。
- 缓存会保存列表或对象(无论查询方法返回哪种)的 1024 个引用。
- 缓存会被视为读/写缓存,这意味着获取到的对象并不是共享的,可以安全地被调用者修改,而不干扰其他调用者或线程所做的潜在修改。
提示 缓存只作用于 cache 标签所在的映射文件中的语句。如果你混合使用 Java API 和 XML 映射文件,在共用接口中的语句将不会被默认缓存。你需要使用 @CacheNamespaceRef 注解指定缓存作用域。
这些属性可以通过 cache 元素的属性来修改。比如:
<cache eviction="FIFO" flushInterval="60000" size="512" readOnly="true"/>这个更高级的配置创建了一个 FIFO 缓存,每隔 60 秒刷新,最多可以存储结果对象或列表的 512 个引用,而且返回的对象被认为是只读的,因此对它们进行修改可能会在不同线程中的调用者产生冲突。
可用的清除策略有:
LRU– 最近最少使用:移除最长时间不被使用的对象。FIFO– 先进先出:按对象进入缓存的顺序来移除它们。SOFT– 软引用:基于垃圾回收器状态和软引用规则移除对象。WEAK– 弱引用:更积极地基于垃圾收集器状态和弱引用规则移除对象。默认的清除策略是 LRU。
flushInterval(刷新间隔)属性可以被设置为任意的正整数,设置的值应该是一个以毫秒为单位的合理时间量。 默认情况是不设置,也就是没有刷新间隔,缓存仅仅会在调用语句时刷新。
size(引用数目)属性可以被设置为任意正整数,要注意欲缓存对象的大小和运行环境中可用的内存资源。默认值是 1024。
readOnly(只读)属性可以被设置为 true 或 false。只读的缓存会给所有调用者返回缓存对象的相同实例。 因此这些对象不能被修改。这就提供了可观的性能提升。而可读写的缓存会(通过序列化)返回缓存对象的拷贝。 速度上会慢一些,但是更安全,因此默认值是 false。
提示 二级缓存是事务性的。这意味着,当 SqlSession 完成并提交时,或是完成并回滚,但没有执行 flushCache=true 的 insert/delete/update 语句时,缓存会获得更新。
使用自定义缓存
除了上述自定义缓存的方式,你也可以通过实现你自己的缓存,或为其他第三方缓存方案创建适配器,来完全覆盖缓存行为。
<cache type="com.domain.something.MyCustomCache"/>这个示例展示了如何使用一个自定义的缓存实现。type 属性指定的类必须实现 org.apache.ibatis.cache.Cache 接口,且提供一个接受 String 参数作为 id 的构造器。 这个接口是 MyBatis 框架中许多复杂的接口之一,但是行为却非常简单。
public interface Cache { String getId(); int getSize(); void putObject(Object key, Object value); Object getObject(Object key); boolean hasKey(Object key); Object removeObject(Object key); void clear(); }为了对你的缓存进行配置,只需要简单地在你的缓存实现中添加公有的 JavaBean 属性,然后通过 cache 元素传递属性值,例如,下面的例子将在你的缓存实现上调用一个名为
setCacheFile(String file)的方法:<cache type="com.domain.something.MyCustomCache"> <property name="cacheFile" value="/tmp/my-custom-cache.tmp"/> </cache>你可以使用所有简单类型作为 JavaBean 属性的类型,MyBatis 会进行转换。 你也可以使用占位符(如
${cache.file}),以便替换成在配置文件属性中定义的值。从版本 3.4.2 开始,MyBatis 已经支持在所有属性设置完毕之后,调用一个初始化方法。 如果想要使用这个特性,请在你的自定义缓存类里实现
org.apache.ibatis.builder.InitializingObject接口。public interface InitializingObject { void initialize() throws Exception; }提示 上一节中对缓存的配置(如清除策略、可读或可读写等),不能应用于自定义缓存。
请注意,缓存的配置和缓存实例会被绑定到 SQL 映射文件的命名空间中。 因此,同一命名空间中的所有语句和缓存将通过命名空间绑定在一起。 每条语句可以自定义与缓存交互的方式,或将它们完全排除于缓存之外,这可以通过在每条语句上使用两个简单属性来达成。 默认情况下,语句会这样来配置:
<select ... flushCache="false" useCache="true"/> <insert ... flushCache="true"/> <update ... flushCache="true"/> <delete ... flushCache="true"/>鉴于这是默认行为,显然你永远不应该以这样的方式显式配置一条语句。但如果你想改变默认的行为,只需要设置 flushCache 和 useCache 属性。比如,某些情况下你可能希望特定 select 语句的结果排除于缓存之外,或希望一条 select 语句清空缓存。类似地,你可能希望某些 update 语句执行时不要刷新缓存。
cache-ref
回想一下上一节的内容,对某一命名空间的语句,只会使用该命名空间的缓存进行缓存或刷新。 但你可能会想要在多个命名空间中共享相同的缓存配置和实例。要实现这种需求,你可以使用 cache-ref 元素来引用另一个缓存。
<cache-ref namespace="com.someone.application.data.SomeMapper"/>
一级缓存
一级缓存也叫作本地缓存,SqlSession
- 与数据库同一次会话期间查询到的数据会放在本地缓存中。
- 如果以后需要获取相同的数据,直接从缓存中拿,没必要再去查询数据库
测试步骤:
-
在核心配置文件中开启日志
<settings> <setting name="logImpl" value="STDOUT_LOGGING"/> </settings> -
接口
package xyz.luck1y.dao; import org.apache.ibatis.annotations.Param; import xyz.luck1y.pojo.User; import java.util.List; public interface UserMapper { // 根据id查询用户 List<User> queryUserById(@Param("id") int id); } -
mapper.xml
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "https://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="xyz.luck1y.dao.UserMapper"> <select id="queryUserById" resultType="user"> select * from mybatis.user where id = #{id} </select> </mapper> -
测试:
在一个session中查询两次相同的记录。
import org.apache.ibatis.session.SqlSession; import org.junit.jupiter.api.Test; import xyz.luck1y.dao.UserMapper; import xyz.luck1y.pojo.User; import xyz.luck1y.utils.MybatisUtils; public class MyTest { @Test public void test() { SqlSession sqlSession = MybatisUtils.getSqlSession(); UserMapper mapper = sqlSession.getMapper(UserMapper.class); User user = mapper.queryUserById(1); System.out.println(user); System.out.println("=============================================="); User user2 = mapper.queryUserById(1); System.out.println(user2); System.out.println(user == user2); sqlSession.close(); } }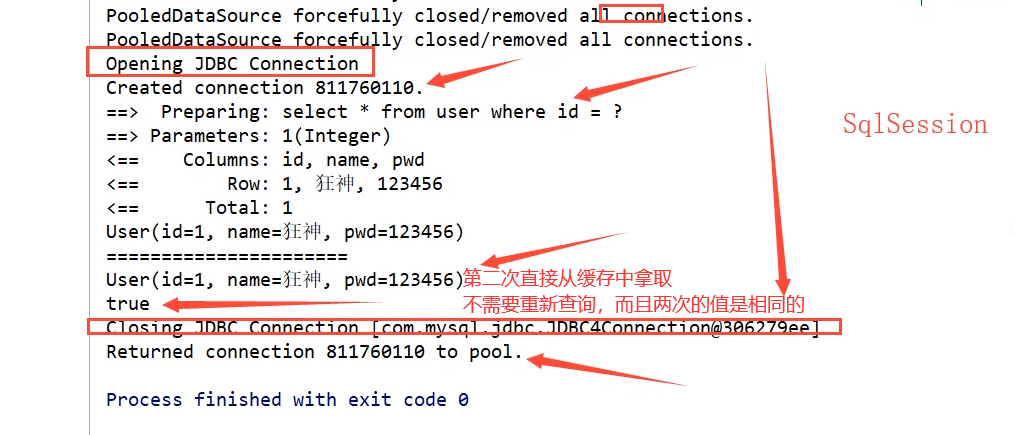
缓存失效的问题:
-
查询不同的数据
-
增删改操作可能会改变原来的数据,所以必定会刷新缓存
public class MyTest { @Test public void test() { SqlSession sqlSession = MybatisUtils.getSqlSession(); UserMapper mapper = sqlSession.getMapper(UserMapper.class); User user = mapper.queryUserById(1); System.out.println(user); // 修改一条数据,缓存刷新 mapper.updateUser(new User(2, "刘子123", "asdqwqeq")); System.out.println("=============================================="); User user2 = mapper.queryUserById(1); System.out.println(user2); System.out.println(user == user2); sqlSession.close(); } }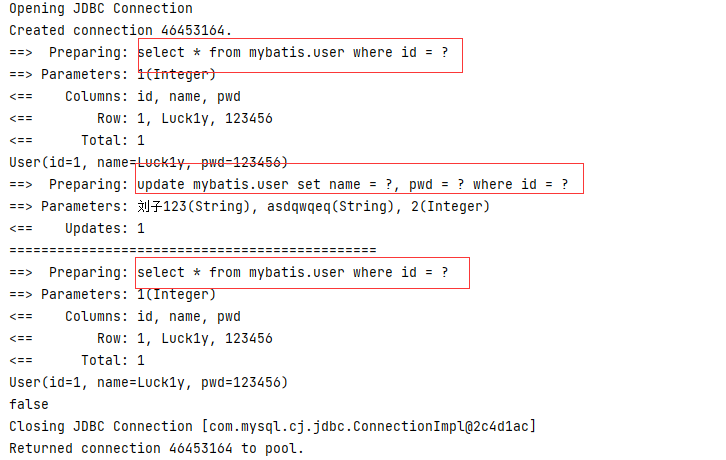
-
查询不同的Mapper.xml
-
手动清理缓存~
// 手动清理缓存 sqlSession.clearCache();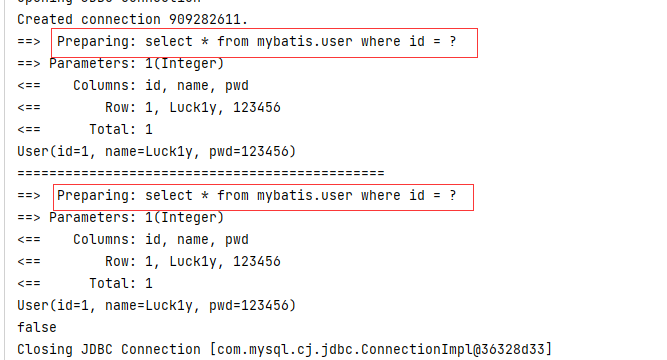
小结:
- 一级缓存默认是开启的,只在一次SqlSession中有效,也就是拿到连接和关闭连接这个区间有效。
- 一级缓存就是一个Map集合,查询时对它进行存取,用完就删掉。
二级缓存
二级缓存也叫作全局缓存,一级缓存的作用域太低了,所以诞生了二级缓存
基于namespace级别的缓存,一个命名空间对应一个二级缓存。
不同的Mapper,但是只要是一个命名空间,那么就是同一个二级缓存
工作机制:
- 一个会话查询一条数据,这个数据就会被放在当前会话的一级缓存中
- 如果当前会话关闭了,这个会话对应的一级缓存就没了,但是我们想要的是会话关闭了,一级缓存中的数据被保存到二级缓存中;
- 新的会话查询信息,就可以从二级缓存中获取内容
- 不同的命名空间查出的数据会放在自己对应的缓存中(map)
步骤:
-
开启全局缓存
配置文件中的设置有一个cacheEnable:

虽然默认开启,但是我们一般会显式地写出来
<!--显式地开启全局缓存--> <setting name="cacheEnabled" value="true"/> -
在要使用二级缓存的mapper中开启配置
<!--在当前Mapper.xml中使用二级缓存--> <!--可以简单写成这样 <cache/> --> <!--<cache/>--> <!--官方给的写法还有这样,可以自定义参数--> <cache eviction="FIFO" flushInterval="60000" size="512" readOnly="true"/> <!--也可以给单独某一条SQL显式地说明使用或不使用cache--> <select id="queryUserById" resultType="user" useCache="true"> select * from mybatis.user where id = #{id} </select> -
测试
@Test public void test2(){ SqlSession sqlSession = MybatisUtils.getSqlSession(); SqlSession sqlSession2 = MybatisUtils.getSqlSession(); UserMapper mapper = sqlSession.getMapper(UserMapper.class); UserMapper mapper2 = sqlSession2.getMapper(UserMapper.class); User user = mapper.queryUserById(1); System.out.println(user); sqlSession.close(); System.out.println("====================================="); User user1 = mapper2.queryUserById(1); System.out.println(user1); System.out.println(user == user1); sqlSession2.close(); }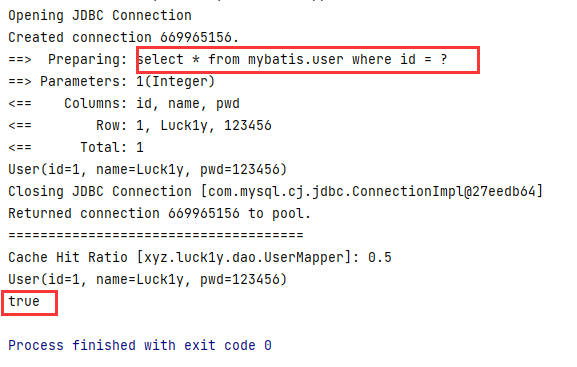
可以看到,第一个session关闭后,通过二级缓存,两次查询只查询了一次。
二级缓存的问题:
- 我们需要将实体类序列化,否则就会报错(参数 readonly设置为true的话,不会报错,但是默认是false)
小结:
- 只要开启了二级缓存,在同一个命名空间下就有效
- 所有的数据都会先放在一级缓存中,只有当会话提交或者关闭的时候,才会保存到二级缓存中。
缓存原理
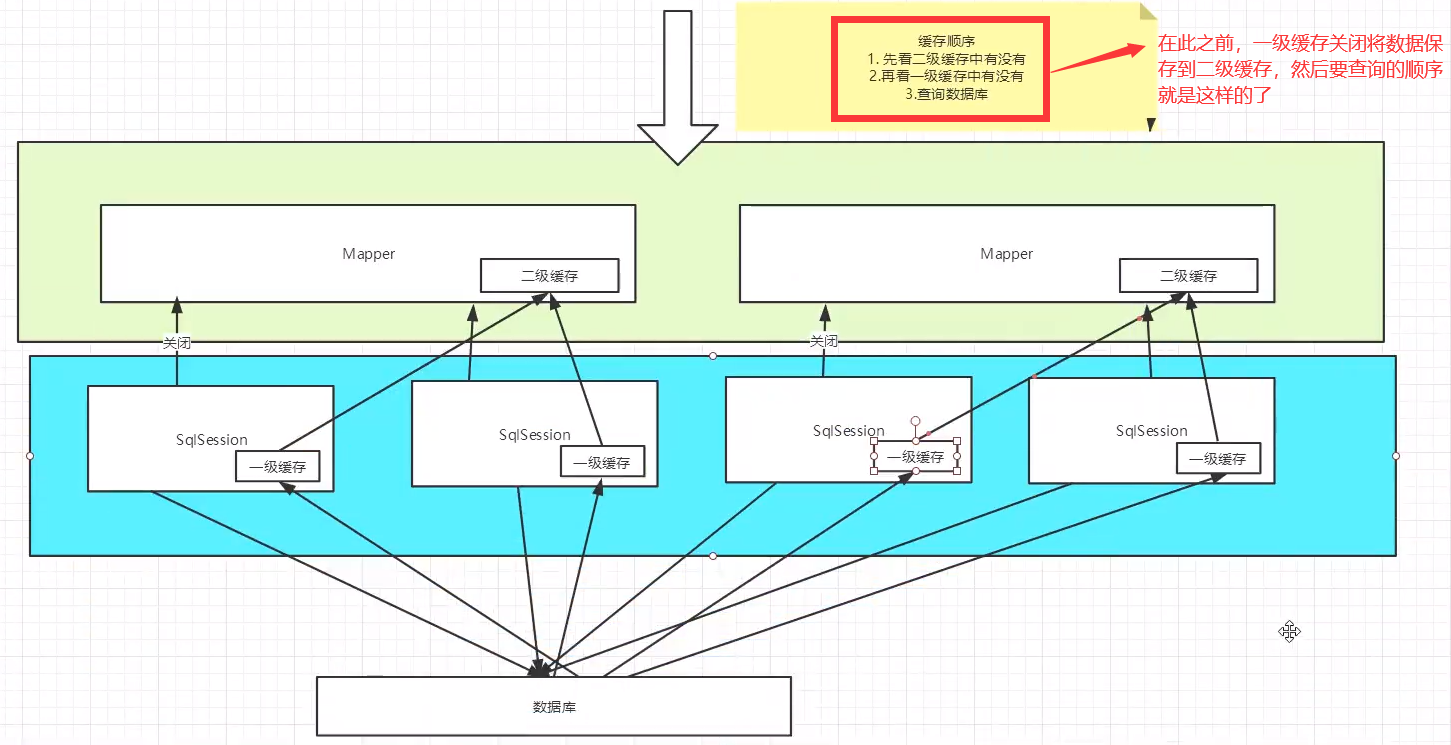
先查一级缓存再查二级缓存,最后去数据库。
自定义缓存ehcache
自定义缓存实现Cache接口即可,然后重写方法,但是重写方法中的内容需要精通数据库才可以,所以我们选择使用已经写好的缓存实现。
Ehcache是一种广泛使用的开源Java分布式缓存。主要面向通用缓存
要在程序中使用ehcache,需要先进行导包:
要在程序中使用ehcache,需要先进行导包:
<dependency>
<groupId>org.mybatis.caches</groupId>
<artifactId>mybatis-ehcache</artifactId>
<version>1.1.0</version>
</dependency>
使用:
-
在Mapper.xml中进行声明使用:
<!--使用二级缓存--> <cache type="org.mybatis.caches.ehcache.EhcacheCache"/> -
类似于log4j,可以自定义单独的配置文件
ehcache.xml:
<?xml version="1.0" encoding="UTF-8" ?> <ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="http://ehcache.org/ehcache.xsd" updateCheck="false"> <!-- diskstore:为缓存路径,ehcache分为内存和磁盘两级,此属性定义磁盘的缓存位置。参数解释如下; user.home -用户主目录 user.dir —用户当前工作目录 java.io.tmpdir-默认临时文件路径 --> <diskStore path="./tmpdir/Tmp_EhCache"/> <defaultCache eternal="false" maxElementsInMemory="10000" overflowToDisk="false" diskPersistent="false" timeToIdleSeconds="1800" timeToLiveSeconds="259200" memoryStoreEvictionPolicy="LRU"/> <cache name="cloud_user" eternal="false" maxElementsInMemory="5000" overflowToDisk="false" diskPersistent="false" timeToIdleSeconds="1800" timeToLiveSeconds="1800" memoryStoreEvictionPolicy="LRU"/> <!-- defaultCache:默认缓存策略,当ehcache找不到定义的缓存时,则使用这个缓存策略。只能定义一个。 --> <!-- name:缓存名称。 maxElementsInMemory:缓存最大数目 maxElementsonDisk:硬盘最大缓存个数。 eternal:对象是否水久有效,但设置了,timeout将不起作用。 overflowToDisk:是否保存到磁盘,当系统当机时 timeToIdleSeconds:设置对象在失效前的允许闲置时间(单位:秒)。仅当eternal=false对象不是永 久有效时使用,可选属性,默认值是0,也就是可闲置时间无穷大。 timeToLiveSeconds:设置对象在失效前允许存活时间(单位:秒)。最大时间介于创建时间和失效时间之间。仅当eternal=false对象不是永久有效时使用,默认是0.,也就是对象存活时间无穷大。 diskpersistent:是否缓存虚拟机重启期数据 whether the disk store persists between restarts of the virtual Machine.The default value is false. diskSpoolBuffersizeMB:这个参数设置Diskstore(磁盘缓存)的缓存区大小。默认是30MB。每个 Cache都应该有自己的一个缓冲区。 diskExpiryThreadintervalseconds:磁盘失效线程运行时间间隔,默认是120秒。 memorystoreEvictionPolicy:当达到maxElementsInMemory限制时,Ehcache将会根据指定的策略 去清理内存。默认策略是LRU(最近最少使用)。你可以设置为FIFO(先进先出)或是LFU(较少使用)。 clearonFlush:内存数量最大时是否清除。 memoryStoreEvictionPolicy:可选策略有:LRU(最近最少使用,默认策略)、FIFO(先进先出)、 LFU(最少访问次数) clearonFlush:内存数量最大时是否清除。 memorystoreEvictionPolicy:可选策略有:LRU(最近最少使用,默认策略)、FIFO(先进先出)、 LFU(最少访问次数)。 FIFO,first in first out,这个是大家最熟的,先进先出。 LFU,Less Frequently Used,就是上面例子中使用的策略,直白一点就是讲一直以来最少被使用的。如上面所讲,缓存的元素有一个hit属性,hit值最小的将会被清出缓存。 LRU,Least Recently Used,最近最少使用的,缓存的元素有一个时间截,当缓存容量满了,而又需要腾出地方来缓存新的元素的时候,那么现有缓存元素中时间戳离当前时间最远的元素将被清出缓存。 --> </ehcache>
后续我们的缓存使用Redis数据库来做缓存!K-V键值对~



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











