







DQL查询数据(MySQL重点)
Data Query Language:数据查询语言
- 所有的查询操作都用它 Select
- 简单的查询,负责的查询他都能做
- 数据库中最核心的语言
- 使用频率最高的语言
Select完整的语法,注意[]代表可选的,{}代表必选的
注意:语法顺序严格按照下面顺序,顺序不能随意颠倒
SELECT [ALL | DISTINCT]
{* | table.* | [table.field1[as alias1][,table.field2p[as alias2]][,...]]}
FROM table_name[as table_alias]
[left | right | inner join table_name2] -- 联合查询
[on ...]-- 临时表条件
[where ...] -- 最后结果过滤条件
[group by ...]-- 指定结果按照哪几个字段来分组
[having] -- 过滤分组的记录必须满足的次要条件
[order by...]-- 指定查询记录按照一个或多个条件进行排序
[limit {[offset,]row_count | row_countOFFSET offset}];-- 指定查询的记录从哪条至哪条
注意:[]的内容代表可选;{}内容代表必选
但是SQL的执行顺序是如下的:
在SQLServer中,select语句的执行顺序是:
- FROM JOIN ON
- WHERE
- GROUP BY
- HAVING
- SELECT DISTINCT TOP()
- ORDER BY
指定查询字段(最简单的Select语句)
CREATE DATABASE IF NOT EXISTS `school`;
-- 创建一个school数据库
USE `school`;
-- 创建年级表
DROP TABLE IF EXISTS `grade`;
CREATE TABLE `grade`(
`gradeid` INT(11) NOT NULL AUTO_INCREMENT COMMENT '年级编号',
`gradename` VARCHAR(50) NOT NULL COMMENT '年级名称',
PRIMARY KEY (`gradeid`)
) ENGINE=INNODB AUTO_INCREMENT = 6 DEFAULT CHARSET = utf8;
-- 插入年级数据
INSERT INTO grade (gradeid,gradename) VALUES(1,'大一'),(2,'大二'),(3,'大三'),(4,'大四'),(5,'预科班');
-- 创建成绩表
DROP TABLE IF EXISTS result;
CREATE TABLE result(
studentno INT(4) NOT NULL COMMENT '学号',
subjectno INT(4) NOT NULL COMMENT '课程编号',
examdate DATETIME NOT NULL COMMENT '考试日期',
studentresult INT (4) NOT NULL COMMENT '考试成绩',
KEY subjectno (subjectno)
)ENGINE = INNODB DEFAULT CHARSET = utf8;
-- 插入成绩数据 这里仅插入了一组,其余自行添加
INSERT INTO result(studentno,subjectno,examdate,studentresult)
VALUES
(1000,1,'2013-11-11 16:00:00',85),
(1000,2,'2013-11-12 16:00:00',70),
(1000,3,'2013-11-11 09:00:00',68),
(1000,4,'2013-11-13 16:00:00',98),
(1000,5,'2013-11-14 16:00:00',58);
INSERT INTO result(studentno,subjectno,examdate,studentresult)
VALUES
(1001,1,'2013-11-11 16:00:00',85),
(1001,2,'2013-11-12 16:00:00',70),
(1001,3,'2013-11-11 09:00:00',68),
(1001,4,'2013-11-13 16:00:00',98),
(1001,5,'2013-11-14 16:00:00',58);
-- 创建学生表
DROP TABLE IF EXISTS `student`;
CREATE TABLE student(
studentno INT(4) NOT NULL COMMENT '学号',
loginpwd VARCHAR(20) DEFAULT NULL,
studentname VARCHAR(20) DEFAULT NULL COMMENT '学生姓名',
sex TINYINT(1) DEFAULT NULL COMMENT '性别,0或1',
gradeid INT(11) DEFAULT NULL COMMENT '年级编号',
phone VARCHAR(50) NOT NULL COMMENT '联系电话,允许为空',
address VARCHAR(255) NOT NULL COMMENT '地址,允许为空',
borndate DATETIME DEFAULT NULL COMMENT '出生时间',
email VARCHAR (50) NOT NULL COMMENT '邮箱账号允许为空',
identitycard VARCHAR(18) DEFAULT NULL COMMENT '身份证号',
PRIMARY KEY (studentno),
UNIQUE KEY identitycard(identitycard),
KEY email (email)
)ENGINE=MYISAM DEFAULT CHARSET=utf8;
-- 插入学生数据 其余自行添加 这里只添加了2行
INSERT INTO student (studentno,loginpwd,studentname,sex,gradeid,phone,address,borndate,email,identitycard)
VALUES
(1000,'123456','张伟',0,2,'13800001234','北京朝阳','1980-1-1','text123@qq.com','123456198001011234'),
(1001,'123456','赵强',1,3,'13800002222','广东深圳','1990-1-1','text111@qq.com','123456199001011233');
-- 创建科目表
DROP TABLE IF EXISTS SUBJECT;
CREATE TABLE SUBJECT(
subjectno INT(11) NOT NULL AUTO_INCREMENT COMMENT '课程编号',
subjectname VARCHAR(50) DEFAULT NULL COMMENT '课程名称',
classhour INT(4) DEFAULT NULL COMMENT '学时',
gradeid INT(4) DEFAULT NULL COMMENT '年级编号',
PRIMARY KEY (subjectno)
)ENGINE = INNODB AUTO_INCREMENT = 19 DEFAULT CHARSET = utf8;
-- 插入科目数据
INSERT INTO SUBJECT(subjectno,subjectname,classhour,gradeid)VALUES
(1,'高等数学-1',110,1),
(2,'高等数学-2',110,2),
(3,'高等数学-3',100,3),
(4,'高等数学-4',130,4),
(5,'C语言-1',110,1),
(6,'C语言-2',110,2),
(7,'C语言-3',100,3),
(8,'C语言-4',130,4),
(9,'Java程序设计-1',110,1),
(10,'Java程序设计-2',110,2),
(11,'Java程序设计-3',100,3),
(12,'Java程序设计-4',130,4),
(13,'数据库结构-1',110,1),
(14,'数据库结构-2',110,2),
(15,'数据库结构-3',100,3),
(16,'数据库结构-4',130,4),
(17,'C#基础',130,1);
简单的查询语句:
-- 查询全部的学生 SELECT 字段 FROM 表
SELECT * FROM student;
SELECT * FROM result;
-- 查询指定字段
SELECT `studentno`,`studentname` FROM student;
-- 别名,给查出来的结果的列名换一个名字 AS(AS可以省略)
SELECT `studentno` AS 学号,`studentname` AS 学生姓名 FROM student;
-- 表也可以起别名,字段和表都可以起别名
SELECT `studentno` AS 学号,`studentname` AS 学生姓名 FROM student AS 学生表1;
-- 函数的使用
-- CONCAT(str1, str2, ...) 拼接字符串
SELECT CONCAT('姓名:',studentname) AS 拼接名字 FROM student;
语法:SELECT 字段, ... ... FROM 表
注意:如果列名不是很通俗易懂,可以自己起一个别名
其他简单用法:
-
去重
DISTINCT:去除SELECT查询出来的结果中重复的数据,重复的数据只显示一条
-- 查询一下有哪些同学参加了考试,有成绩 SELECT * FROM result; -- 查询全部的考试成绩 -- 查询有哪些同学参加了考试 SELECT `studentno` FROM result; -- 发现重复数据,去重 SELECT DISTINCT `studentno` FROM result; -
数据库中的表达式
-- 查询系统版本(函数) SELECT VERSION(); -- 可以用来计算(表达式) SELECT 100*3-1 AS 计算结果; -- 查询自增的步长(变量) SELECT @@auto_increment_increment; -- 学员考试成绩 +1 分 SELECT `studentno`,`studentresult`+1 AS 加分后 FROM result数据库中的表达式:文本值,列,null,函数,计算表达式,系统变量
语法升级:
SELECT 表达式 FROM 表
where条件子句和模糊查询
作用:检索数据中符合条件的值
搜索的条件由一个或者多个表达式组成,结果为布尔值。
官网参考手册:MySQL :: MySQL 8.0 参考手册 :: 12.1 内置函数和运算符参考
-
逻辑运算符
运算符 语法 描述 and && a and b a&&b 逻辑与,两个都为真,结果为真 or || a or b a || b 逻辑或,有一个为真,则结果为真 not ! not a !a 逻辑非,真为假,假为真 推荐使用英文字母,可读性高
-- ================= where ====================== SELECT `studentno`,`studentresult` FROM result; -- 查询考试成绩在95~100分之间(AND) SELECT `studentno`,`studentresult` FROM result WHERE `studentresult` >= 95 AND `studentresult` <= 100; -- 查询考试成绩在95~100分之间(&&) SELECT `studentno`,`studentresult` FROM result WHERE `studentresult` >= 95 && `studentresult` <= 100; -- 模糊查询 between ... and ...(区间) SELECT `studentno`,`studentresult` FROM result WHERE `studentresult` BETWEEN 95 AND 100; -- 除了1000号学生之外的同学的成绩(NOT) SELECT `studentno`,`studentresult` FROM result WHERE NOT `studentno` = 1000; -- 除了1000号学生之外的同学的成绩(!=) SELECT `studentno`,`studentresult` FROM result WHERE `studentno` != 1000; -
模糊查询:本质是比较运算符
运算符 语法 描述 IS NULL a is null 如果操作符为null,结果为真 IS NOT NULL a is not null 如果操作符不为null,结果为真 BETWEEN a between b and c 若a在b和c之间,则结果为真 LIKE a like b SQL匹配,如果a匹配b,则结果为真 IN a in (a1,a2,a3…) 假设a在a1,或者a2…其中的某一个值中,结果为真 注意:LIKE区分大小写
-- ================= 模糊查询 ====================== -- 查询姓赵的同学 -- 使用 LIKE 结合 % (代表0到任意个字符)和 _ (一个字符) SELECT `studentno`,`studentname` FROM `student` WHERE `studentname` LIKE '赵%'; -- 查询姓赵的同学,后面只有一个字的 SELECT `studentno`,`studentname` FROM `student` WHERE `studentname` LIKE '赵_'; -- 查询姓赵的同学,后面只有两个字的 SELECT `studentno`,`studentname` FROM `student` WHERE `studentname` LIKE '赵__'; -- 查询名字中间有强字的同学 SELECT `studentno`,`studentname` FROM `student` WHERE `studentname` LIKE '%强%'; -- ================= in (具体的一个或多个值,不能模糊匹配,不能使用% ====================== -- 查询1001,1000`,`studentname` FROM `student` SELECT `studentno`,`studentname` FROM `student` WHERE studentno IN (1001,1000); -- 查询在北京的学员的信息 SELECT `studentno`,`studentname` FROM `student` WHERE address IN ('北京','安徽'); -- ================= NULL NOT NULL ====================== -- 查询地址为空的学生 null 或 '' SELECT `studentno`,`studentname` FROM `student` WHERE address='' OR address IS NULL; -- 查询有出生日期的同学(不为空) SELECT `studentno`,`studentname` FROM `student` WHERE `borndate` IS NOT NULL; -- 查询没有出生日期的同学(为空) SELECT `studentno`,`studentname` FROM `student` WHERE `borndate` IS NULL;
联表查询(JOIN ON)以及 自连接查询
-
JOIN ON
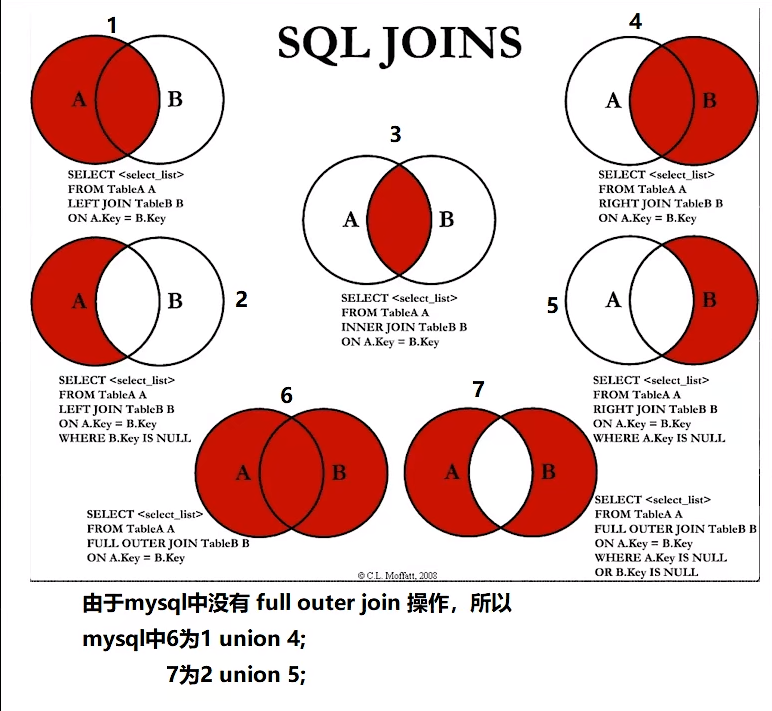
| 操作 | 描述 |
|---|---|
| Inner join | 以两个表都有的值为基准,表中至少有一个匹配就返回该行 |
| Left join | 从左表中返回所有的值,即使右表中没有匹配 |
| Right join | 从右表中返回所有的值,即使左表中没有匹配 |
-- ================= 联表查询 JOIN ======================
-- 查询参加了考试的同学(学号,姓名,科目的编号,分数),发现成绩表里没有姓名,这时候就需要联表查询
/*
思路:
1.分析需求,分析查询的字段来自哪些表,如果超过一张表就需要联表查询
2.分析使用哪种联表查询,共有七种,需要确定交叉点,这两个表中哪个数据是相同的(studentno)
判断的条件:学生表中的studentno = 成绩表中的studentno
*/
SELECT s.`studentno`,`studentname`,`subjectno`,`studentresult`
FROM student AS s
INNER JOIN result AS r
WHERE s.studentno = r.studentno;
-- RIGHT JOIN
SELECT s.`studentno`,`studentname`,`subjectno`,`studentresult`
FROM student AS s
RIGHT JOIN result r -- AS 可以省略
ON s.studentno = r.studentno; -- WHERE可以对ON条件里的内容再次进行过滤
-- LEFT JOIN
SELECT s.`studentno`,`studentname`,`subjectno`,`studentresult`
FROM student AS s
LEFT JOIN result r -- AS 可以省略
ON s.studentno = r.studentno; -- WHERE可以对ON条件里的内容再次进行过滤
-- 查询缺考的同学
SELECT s.`studentno`,`studentname`,`subjectno`,`studentresult`
FROM student AS s
LEFT JOIN result r -- AS 可以省略
ON s.studentno = r.studentno; -- WHERE可以对ON条件里的内容再次进行过滤
WHERE studentresult IS NULL;
-- 思考题(查询了参加考试的同学的信息:学号,学生姓名,科目名称,分数)
/*
思路:
1.分析需求,分析查询的字段来自哪些表,student、result、subject(连接查询)
2.分析使用哪种联表查询,共有七种,需要确定交叉点,这两个表中哪个数据是相同的(studentno)
判断的条件:学生表中的studentno = 成绩表中的studentno
*/
SELECT s.`studentno`,`studentname`,`subjectname`,`studentresult`
FROM student s
RIGHT JOIN result r
ON r.studentno=s.studentno
INNER JOIN `subject` sub
ON r.subjectno=sub.subjectno;
-- 我要查询哪些数据 SELECT...
-- 从哪几个表中查 FROM 表 xxxx JOIN 连接的表 ON 交叉条件
-- 假设存在多张表查询,慢慢来,先查询两张表,再慢慢增加
-- FROM a LEFT JOIN b 以a表为基准(左连接以左边为基准
on 和where条件的放置详解
总结:
对于left join,不管on后面跟什么条件,左表的数据全部查出来,因此要想过滤需把条件放到where后面
对于inner join,满足on后面的条件表的数据才能查出,可以起到过滤作用。也可以把条件放到where后面。
数据库在通过连接两张或多张表来返回记录时,都会生成一张中间的临时表,然后再将这张临时表返回给用户。
在使用left jion时,on和where条件的区别如下:
on条件是在生成临时表时使用的条件,它不管on中的条件是否为真,都会返回左边表中的记录。
where条件是**在临时表生成好后,再对临时表进行过滤的条件。**这时已经没有left join的含义(必须返回左边表的记录)了,条件不为真的就全部过滤掉。
假设有两张表:
表1:tab2
id size 1 10 2 20 3 30 表2:tab2
size name 10 AAA 20 BBB 20 CCC 两条SQL:
select * form tab1 left join tab2 on (tab1.size = tab2.size) where tab2.name=’AAA’ select * form tab1 left join tab2 on (tab1.size = tab2.size and tab2.name=’AAA’)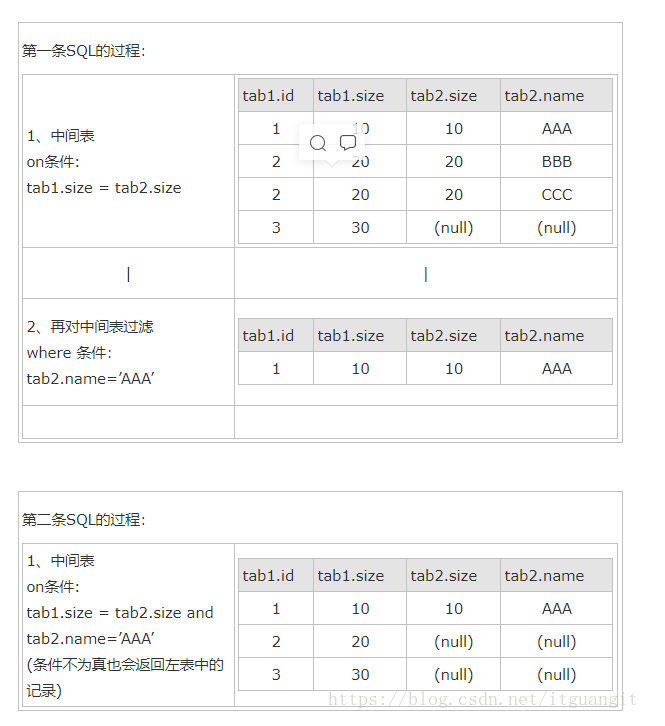
其实以上结果的关键原因就是left join,right join,full join的特殊性,不管on上的条件是否为真都会返回left或right表中的记录,full则具有left和right的特性的并集。 而inner join没这个特殊性,则条件放在on中和where中,返回的结果集是相同的。
总结:
在多表联接查询时,on比where更早起作用。系统首先根据各个表之间的联接条件,把多个表合成一个临时表后,再由where进行过滤,然后再计算,计算完后再由having进行过滤。由此可见,要想过滤条件起到正确的作用,首先要明白这个条件应该在什么时候起作用,然后再决定放在哪里。
原文链接:https://blog.youkuaiyun.com/itguangit/article/details/83011781
-
自连接查询
自己的表和自己的表连接,核心:一张表拆为两张一样的表即可
建表语句:
CREATE TABLE `category`( `categoryid` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主题id', `pid` INT(10) NOT NULL COMMENT '父id', `categoryname` VARCHAR(50) NOT NULL COMMENT '主题名字', PRIMARY KEY (`categoryid`) ) ENGINE=INNODB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8; INSERT INTO `category` (`categoryid`, `pid`, `categoryname`) VALUES ('2','1','信息技术'), ('3','1','软件开发'), ('5','1','美术设计'), ('4','3','数据库'), ('8','2','办公信息'), ('6','3','web开发'), ('7','5','ps技术');得到该表:
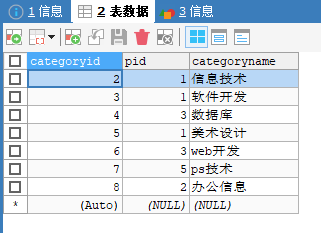
对这张表进行拆解:
-
(父类)因为categoryid没有为1的,所以pid为1的是父类(顶级ID):
categoryid categoryname 2 信息技术 3 软件开发 5 美术设计 -
(子类)子类的pid指向父类的categoryid:
pid categoryid categoryname 3 4 数据库 2 8 办公信息 3 6 web开发 5 7 ps技术 操作:查询父类对应的子类关系(就是要得到以下的表)
父类 子类 信息技术 办公信息 软件开发 数据库 软件开发 web开发 美术设计 ps技术 -- 查询学员所属年级(学号、学生姓名、年级名称) SELECT studentno,studentname,gradename FROM student s INNER JOIN `grade` g ON s.gradeid=g.gradeid; -- 查询科目所属的年级(科目名称,年级名称) SELECT `subjectname`,`gradename` FROM `subject` sub INNER JOIN `grade` g ON sub.`gradeid`=g.`gradeid`; -- 查询参加了数据库结构考试的同学的信息(学号,学生姓名,科目名,分数) SELECT s.`studentno`,`studentname`,`subjectname`,`studentresult` FROM student s INNER JOIN `result` r ON s.studentno=r.studentno INNER JOIN `subject` sub ON r.`subjectno`=sub.`subjectno` WHERE subjectname = '数据库结构-1';
-
分页(LIMIT)和排序(ORDER BY)
-
排序(也可以利用前段排序)
ORDER BY 排序:升序 ASC,降序 DESC
ORDER BY 通过哪个字段排序 怎么排-- 排序:升序ASC,降序DESC -- ORDER BY 通过哪个字段排序,怎么排 -- 查询的结果根据成绩降序,排序 SELECT s.`studentno`,`studentname`,`subjectname`,`studentresult` FROM student s INNER JOIN `result` r ON s.studentno=r.studentno INNER JOIN `subject` sub ON r.`subjectno`=sub.`subjectno` WHERE subjectname = '数据库结构-1'; ORDER BY studentresult ASC -- ASC升序 SELECT s.`studentno`,`studentname`,`subjectname`,`studentresult` FROM student s INNER JOIN `result` r ON s.studentno=r.studentno INNER JOIN `subject` sub ON r.`subjectno`=sub.`subjectno` WHERE subjectname = '数据库结构-1'; ORDER BY studentresult DESC -- DESC降序 -
分页
- 某一页的分页公式:
limit (n-1)*pageSize,pageSize(n代表当前页,pageSize代表该页显示的数据量,即页面大小) - 总页数:数据总数/页面大小(记得做一个向上取整的处理)
-- 分页 LIMIT -- 假设有100万条数据 -- 为什么要分页? -- 缓解数据库压力,给人的体验更好 -- 目前还有一种处理叫瀑布流,一次加载一部分,能一直无限刷下去 -- 分页,每页只显示五条数据 -- 语法:limit起始值,页面的大小 -- LIMIT n,m 起始行(首项为0),显示m条数据 -- LIMIT 0,5 显示第1~5行数据 -- LIMIT 1,5 显示第2~6行数据 -- LIMIT 6,5 (第二页的数据) -- 网页应用:显示当前页,总页数,一页显示多少条数据 -- 按照降序排序 SELECT s.`studentno`,`studentname`,`subjectname`,`studentresult` FROM student s INNER JOIN `result` r ON s.studentno=r.studentno INNER JOIN `subject` sub ON r.`subjectno`=sub.`subjectno` WHERE subjectname = '数据库结构-1'; ORDER BY studentresult DESC -- DESC降序 LIMIT 0,1; -- 总结:假设每页显示五条 -- 第一页:limit 0,5 -- 第二页:limit 5,5 -- 第三页:limit 10,5 -- 第n页:limit (n-1)*pageSize,pageSize -- 规律: -- 1. 某一页的分页公式:limit (n-1)*pagesize,pagesize (n代表当前页,pagesize代表该页显示的数据量,即页面大小) -- 2. 总页数:数据总数/页面大小(记得做一个向上取整的处理) - 某一页的分页公式:
综合小练习:
-- 查询Java第一学年 课程成绩排名前十的学生,并且分数要大于80分的学生信息(学号,姓名,课程名称,分数)
SELECT s.`studentno`,`studentname`,`subjectname`,`studentresult`
FROM student s
INNER JOIN result r
ON s.studentno=r.studentno
INNER JOIN `subject` sub
ON sub.subjectno=r.subjectno
WHERE subjectname LIKE '%Java%'
AND studentresult>=80
ORDER BY studentresult DESC
LIMIT 0,10;
分组(GROUP BY)和过滤(HAVING)
-- ============== 分组 =================
-- 查询不同课程的平均分,最高分,最低分
-- 核心:根据不同的课程分组
SELECT subjectname, AVG(studentresult) AS 平均分,MAX(studentresult) AS 最高分,MIN(studentresult) AS 最低分
FROM result r
INNER JOIN `subject` sub
ON r.`subjectno`=sub.`subjectno`
GROUP BY r.subjectno -- 通过什么字段来分组
-- WHERE AVG(studentresult)>=80 会发现这里用where会报错,where条件不能过滤聚合函数
HAVING 平均分 > 80 -- 函数进行过滤用having
where和having的区别:
先看一段代码:
1.
SELECT name,SUM(score) FROM table_name
GROUP BY name
HAVING name='小明';
2.
SELECT name,SUM(score) FROM table_name
WHERE name='小明'
GROUP BY name;
这两段语句得到的结果是一样的。
那么他们两者的区别在哪呢?
首先,Where 子句是用来指定 “行” 的条件的,而Having 子句是指定 “组” 的条件的,即
Where 子句 = 指定行所对应的条件
Having 子句 = 指定组所对应的条件
因此,2 语句会比较合适。
WHERE语句在GROUP BY语句之前;SQL会在分组之前计算WHERE语句。
HAVING语句在GROUP BY语句之后;SQL会在分组之后计算HAVING语句。
其次,当在Where子句和Having子句中都可以使用的条件,从语句的执行效率来看,最好写在Where子句中。
此外,Where子句中不能使用聚合函数,而Having子句中可以。
两者的执行顺序:
where>聚合函数(sum,min,max,avg,count)>having
若须引入聚合函数来对group by 结果进行过滤 则只能用having。
select sum(score) from student where sex='man' group by name having sum(score)>210
注意事项 :
- where 后不能跟聚合函数,因为where执行顺序大于聚合函数。
- where 子句的作用是在对查询结果进行分组前,将不符合where条件的行去掉,即在分组之前过滤数据,条件中不能包含聚组函数,使用where条件显示特定的行。
- having 子句的作用是筛选满足条件的组,即在分组之后过滤数据,条件中经常包含聚组函数,使用having 条件显示特定的组,也可以使用多个分组标准进行分组。
在执行速度上来说:
在使用Count函数等对表中的数据进行聚合操作时,DBMS内部会进行排序处理,而排序操作会增加机器的负担,减少排序的行数,可以增加处理速度。
使用Where子句指定条件时,由于排序之前就对数据进行了过滤,所以能够减少排序的数据量。但是Having子句是在排序之后才对数据进行分组的,因此与前者相比,需要排序的数据量就要多得多。
使用Where子句更具速度优势的另一个理由是,可以对Where子句指定条件所对应的列创建索引,这样可以大幅提高处理速度。
子查询(嵌套查询)
前面我们写的where语句都是固定的,是具体的,具体到是否相等,是否在某个区间,那么,如何让where后面的语句是计算出来的,这就是子查询
where(此处值为计算出来的)
本质:where语句中嵌套一个子查询语句 where(select * from…)
-- ======== 子嵌套 =========
-- 查询数据库结构课程的所有考试结果(学号,科目名,成绩),并进行降序排列
-- 方法一:连接查询
SELECT `studentno`,`subjectname`,`studentresult`
FROM `result` r
INNER JOIN `subject` sub
ON r.subjectno=sub.subjectno
WHERE subjectname LIKE '%数据库%'
ORDER BY studentresult DESC;
-- 方式二:子查询(先查询里面的,再查询外面的,由里及外执行)
SELECT `studentno`,`subjectname`,`studentresult`
FROM `result`
WHERE subjectno=(
-- 查询所有数据库结构课程的编号
SELECT subjectno
FROM `subject`
WHERE subjectname='%数据库%'
)
ORDER BY studentresult DESC;
-- 分数小于80分的学生的学号和姓名
SELECT DISTINCT s.`studentno`,`studentname`
FROM student s
INNER JOIN result r
ON r.studentno=s.studentno
WHERE `studentresult`>=80
-- 在这个基础上,增加一个科目,高等数学-2
-- 查询 高等数学-2 的编号
SELECT DISTINCT s.`studentno`,`studentname`
FROM student s
INNER JOIN result r
ON r.studentno=s.studentno
WHERE `studentresult`>=80 AND `subjectno` = (
SELECT subjectno FROM `subject` WHERE subjectname='高等数学-2'
)
-- 查询高等数学-2的考试分数不低于80分的学生的序号和姓名
SELECT DISTINCT s.studentNo,studentname
FROM student s
INNER JOIN result r
ON r.studentno=s.studentno
INNER JOIN `subject` sub
ON r.subjectno = sub.subjectno
WHERE sub.subjectname = '高等数学-2'
AND r.studentresult >=80 ;
-- 再改造(也是由里及外)
SELECT DISTINCT studentno,studentname
FROM student
WHERE studentno IN(
SELECT studentno FROM result WHERE studentresult>=80 AND subjectno= (
SELECT subjectno FROM `subject` WHERE subjectname='高等数学-2'
)
)
查询C语言-1的前五名同学的成绩的信息(学号,姓名,分数)
-- 查询c语言-1的前五名同学的成绩的信息(学号,姓名,分数 )
SELECT s.`studentno`,`studentname`,`studentresult`
FROM student s
INNER JOIN result r
ON s.studentno=r.studentno
WHERE r.subjectno=(
SELECT subjectno FROM `subject`
WHERE subjectname = 'c语言-1'
)
ORDER BY studentresult DESC
LIMIT 0,5;
SELECT小结
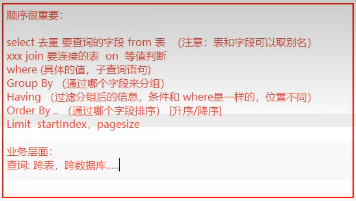
在业务层面,数据库可能需要跨表,甚至跨地区,一个页面,可能用到了很多种数据库。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











