



 本文介绍了一种由程序员提出的数据库查询优化方法,通过在数据输入时生成预处理表,减少多表查询耦合,加快数据提取速度,提高用户体验。这种方法类似于物化视图,但在程序端实现,避免了数据库运算瓶颈。
本文介绍了一种由程序员提出的数据库查询优化方法,通过在数据输入时生成预处理表,减少多表查询耦合,加快数据提取速度,提高用户体验。这种方法类似于物化视图,但在程序端实现,避免了数据库运算瓶颈。
在数据库优化的过程中,领教过各种,技术的,非技术的,数据库赋予的特性的,数据库表人工设计中优化非范式的设计。其实众多优化的想法无非是从接受数据的开始通过精准定位需求,格式化数据库表,在设计表时就考虑部分查询的优化,以及后期进行数据表的归档等等工作。
在深入就是利用缓存的技术,将数据预读进来,增加数据提取的时效性,加快数据提取的速度而已。而这些大部分都是 NF。
今天要说的是,我们公司的程序员想出的一个方法,加快数据的某些提取速度,减小表的查询的耦合,提高客户的使用观感的一种方法,这也算是另类的一种数据提取的方式。
画个图说的清楚些,例如某个客户需要输出的信息需要 表 A B C D 组成,多表的无论是子查询,LEFT JOIN , 还是 EXISTS 等等数据量小还好,如果数据量大,那就的在关联字段上建立索引,而建立索引太多,如果表的数据插入频繁又是插入性能低下,这是先有蛋还是先有鸡的问题。
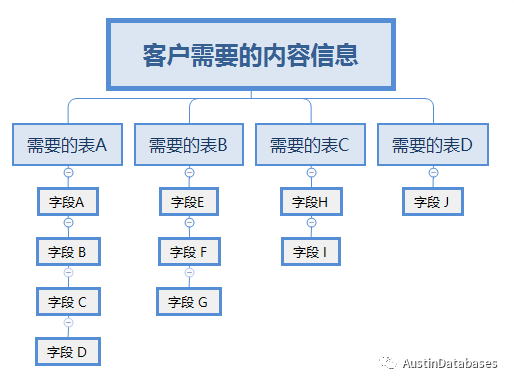
而聪明的程序员,在充分了解客户需求以及客户需求不断变化的情况下,想出了,预先将 B C D 表的信息合并,减少后期数据表查询的耦合,加快信息的提取,而最终实现数据的快速高性能的提取。
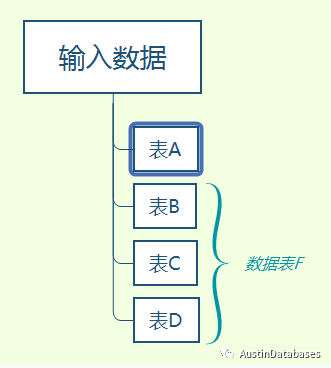
还是的画张图,来说的更清楚, 程序员在数据输入的时候就通过程序来自动生成了 F 表,它是一个根据客户需求的内容来生成的一个单独的表,不需要数据库做任何运算,而是在程序端处理,提前将用户日后需要查询的数据做了一个表。
可能有的DBA 会说,切,这不就是视图的概念,ORACLE 有物化视图的概念,SQL SERVER 有索引视图的概念,都可以轻松的完成上面的工作。我想说的是 NO NO NO 。
虽然通过视图可以完成这个工作,但视图哪怕是 物化视图,或索引视图,它们也都要通过数据库的运算,数据提取,才能获得数据,并存储,或者不存储,每次调用在进行计算。这样的方式DBA已经很熟悉了,但弊端也是显而易见的,无法摆脱数据库自己的运算和数据提取,这也是产生性能瓶颈的可能原因。
所以DEVELOPERS 已经在程序中,自己建立了自己的物化视图,后期查询仅仅需要查询表A + 表 F 即可达到目的。 在我看来这真的是一个好方法,虽然它也有的局限性,但开发的优化精神和不默守陈规的想法,值得“赞”



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









