




目录
本文作者:徐强,张均杰,黄威
专业在线打字练习平台-巧手打字通,只输出有价值的知识。
一 背景
部门中维护了一个老系统,功能都耦合在一个单体应用中(300+接口),表也放在同一个库中(200+表),导致系统存在很多风险和缺陷。经常出现问题:如数据库的单点、性能问题,应用的扩展受限,复杂性高等问题。
从下图可见。各业务相互耦合无明确边界,调用关系错综复杂。
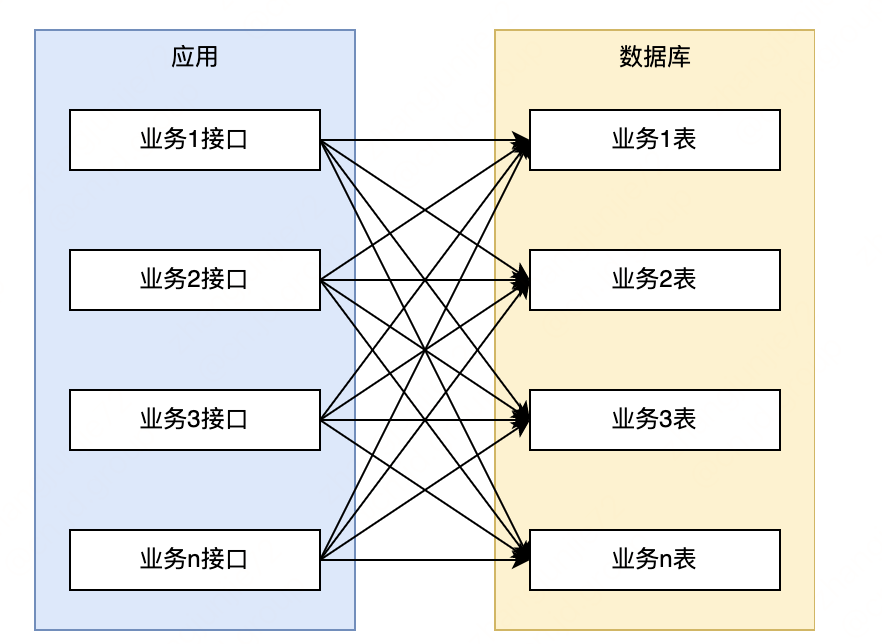
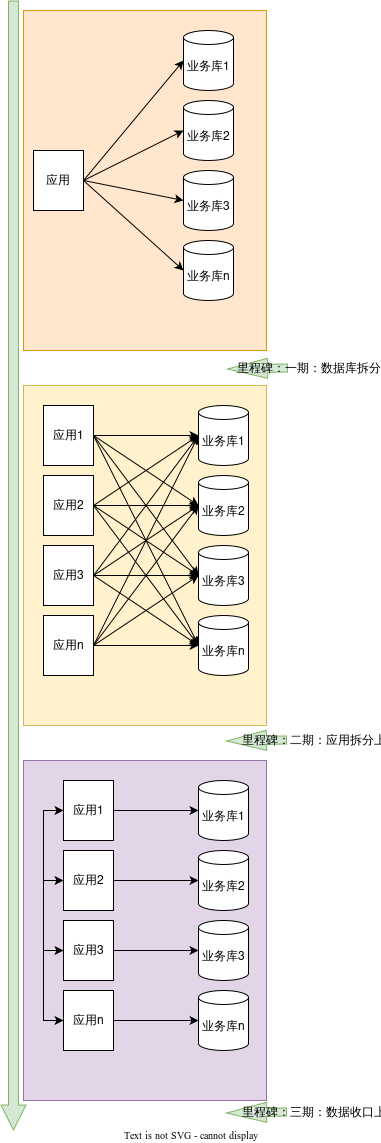
随着业务快速发展,各种问题越来越明显,急需对系统进行微服务改造优化。经过思考,整体改造将分为三个阶段进行:
-
数据库拆分:数据库按照业务垂直拆分。
-
应用拆分:应用按照业务垂直拆分。
-
数据访问权限收口:数据权限按照各自业务领域,归属到各自的应用,应用与数据库一对一,禁止交叉访问。
二 数据库拆分
单体数据库的痛点:未进行业务隔离,一个慢SQL易导致系统整体出现问题;读写压力大,性能下降;
数据库改造
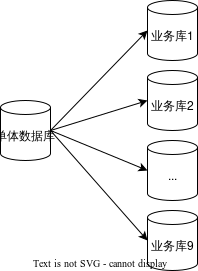
根据业务划分,我们计划将数据库拆分为9个业务库。数据同步方式采用主从复制的方式,我们提前整理好表和新数据库的对应关系交给运维同学,运维同学通过binlog过滤将对应的表和数据同步到对应的新数据库中,每个新数据库中只包含自己业务的表。
代码改造方案
如果一个接口中操作了多张表,之前这些表属于同一个库,数据库拆分后可能会分属于不同的库。所以需要针对代码进行相应的改造。
目前存在问题的位置:
-
数据源选择:系统之前是支持多数据源切换的,在service上添加注解来选择数据源。数据库拆分后出现的情况是同一个service中操作的多个mapper从属于不同的库。
-
事务:事务注解目前是存在于service上的,并且事务会缓存数据库链接,一个事务内不支持同时操作多个数据库。
改造点梳理:
-
同时写入多个库,且是同一事务的接口6个:需改造数据源,需改造事务,需要关注分布式事务;
-
同时写入多个库,且不是同一事务的接口50+:需改造数据源,需改造事务,无需关注分布式事务;
-
同时读取多个库 或 读取一个库写入另一个库的接口200+:需改造数据源,但无需关注事务;
-
涉及多个库的表的联合查询8个:需进行代码逻辑改造
梳理方式:
采用部门中的切面工具,抓取入口和表的调用关系(可识别表的读/写操作),找到一个接口中操作了多个表,并且多个表分属于不同业务库的情况;
分布式事务:
进行应用拆分和数据访问权限收口之后,是不存在分布式事务的问题的,因为操作第二个库会调用对应系统的RPC接口进行操作。所以本次不会正式支持分布式事务,而是采用代码逻辑保证一致性的方式来解决;
方案一
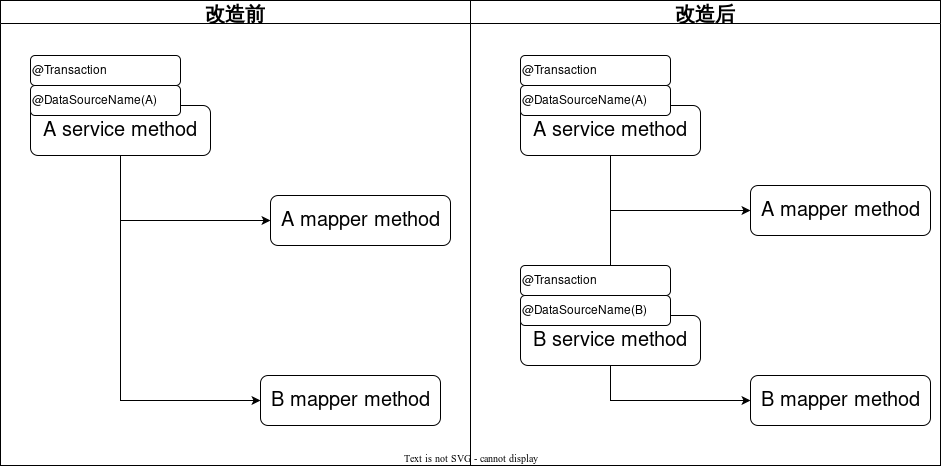
将service中分别操作多个库的mapper,抽取成多个Service。分别添加切换数据源注解和事务注解。
问题:改动位置多,涉及改动的每个方法都需要梳理历史业务;service存在很多嵌套调用的情况,有时难以理清逻辑;修改200+位置改动工作量大,风险高;
方案二
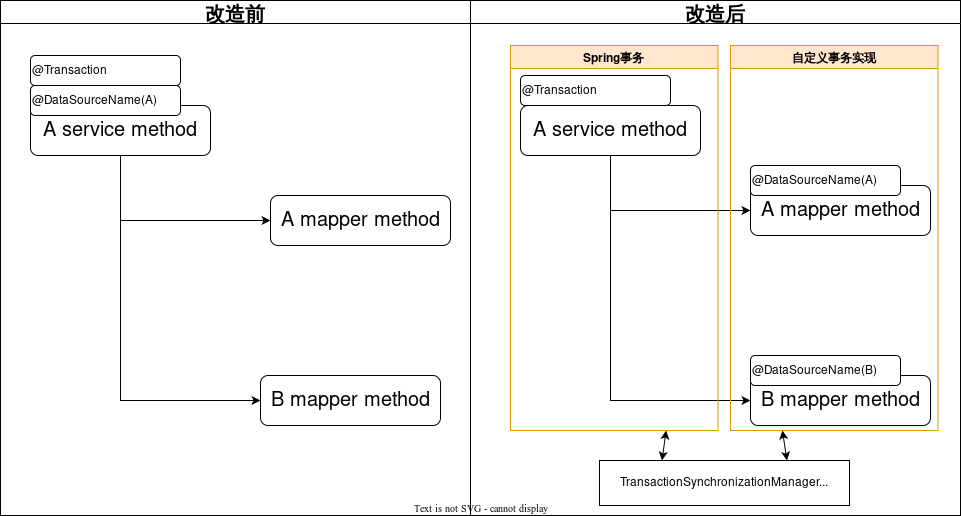
如图所示,方案二将数据源注解移动到Mapper上,并使用自定义的事务实现来处理事务。
将多数据源注解放到Mapper上的好处是,不需要梳理代码逻辑,只需要在Mapper上添加对应数据源名称即可。但是这样又有新的问题出现,
-
问题1:如上图,事务的是配置在Service层,当事务开启时,数据源的连接并没有获取到,因为真正的数据源配置在Mapper上。所以会报错,这个错误可以通过多数据源组件的默认数据源功能解决。
-
问题2:mybatis的事务实现会缓存数据库链接。当第一次缓存了数据库链接后,后续配置在mapper上的数据源注解并不会重新获取数据库链接,而是直接使用缓存起来的数据库链接。如果后续的mapper要操作其余数据库,会出现找不到表的情况。鉴于以上问题,我们开发了一个自定义的事务实现类,用来解决这个问题。
下面将对方案中出现的两个组件进行简要说明原理。
多数据源组件
多数据源组件是单个应用连接多个数据源时使用的工具,其核心原理是通过配置文件将数据库链接在程序启动时初始化好,在执行到存在注解的方法时,通过切面获取当前的数据源名称来切换数据源,当一次调用涉及多个数据源时,会利用栈的特性解决数据源嵌套的问题。
/**
* 切面方法
*/
public Object switchDataSourceAroundAdvice(ProceedingJoinPoint pjp) throws Throwable {
//获取数据源的名字
String dsName = getDataSourceName(pjp);
boolean dataSourceSwitched = false;
if (StringUtils.isNotEmpty(dsName)
&& !StringUtils.equals(dsName, StackRoutingDataSource.getCurrentTargetKey())) {
// 见下一段代码
StackRoutingDataSource.setTargetDs(dsName);
dataSourceSwitched = true;
}
try {
// 执行切面方法
return pjp.proceed();
} catch (Throwable e) {
throw e;
} finally {
if (dataSourceSwitched) {
StackRoutingDataSource.clear();
}
}
}
public static void setTargetDs(String dbName) {
if (dbName == null) {
throw new NullPointerException();
}
if (contextHolder.get() == null) {
contextHolder.set(new Stack<String>());
}
contextHolder.get().push(dbName);
log.debug("set current datasource is " + dbName);
}
StackRoutingDataSource继承 AbstractRoutingDataSource类,AbstractRoutingDataSource是spring-jdbc包提供的一个了AbstractDataSource的抽象类,它实现了DataSource接口的用于获取数据库链接的方法。
自定义事务实现
从方案二的图中可以看到默认的事务实现使用的是mybatis的SpringManagedTransaction。
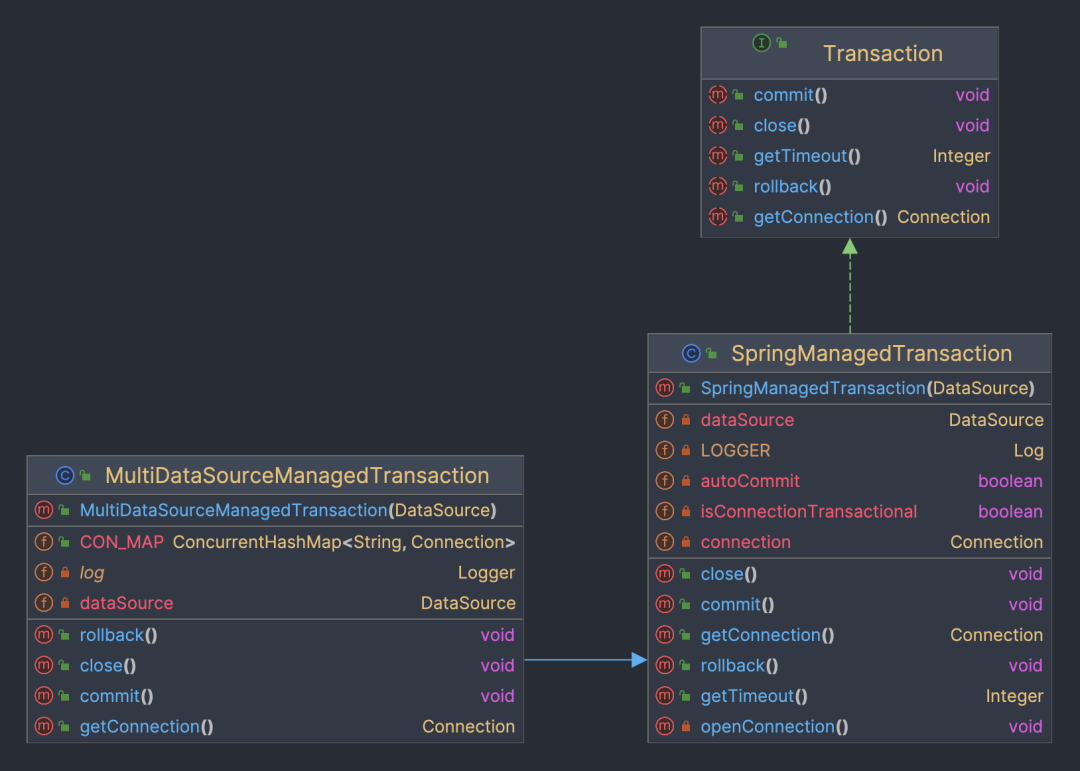
如上图,Transaction和SpringManagedTransaction都是mybatis提供的类,他提供了接口供SqlSession使用,处理事务操作。通过下边的一段代码可以看到,事务对象中存在connection变量,首次获得数据库链接后,后续当前事务内的所有数据库操作都不会重新获取数据库链接,而是会使用现有的数据库链接,从而无法支持跨库操作。
public class SpringManagedTransaction implements Transaction {
private static final&nb 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 223
223

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









