







1.简介
FastDFS是分布式文件系统。使用 FastDFS很容易搭建一套高性能的文件服务器集群提供文件上传、下载等服务。
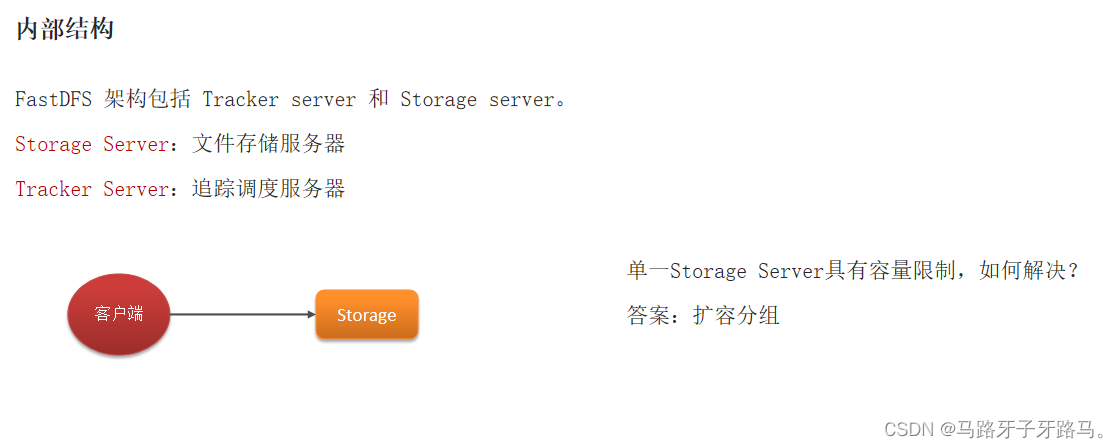
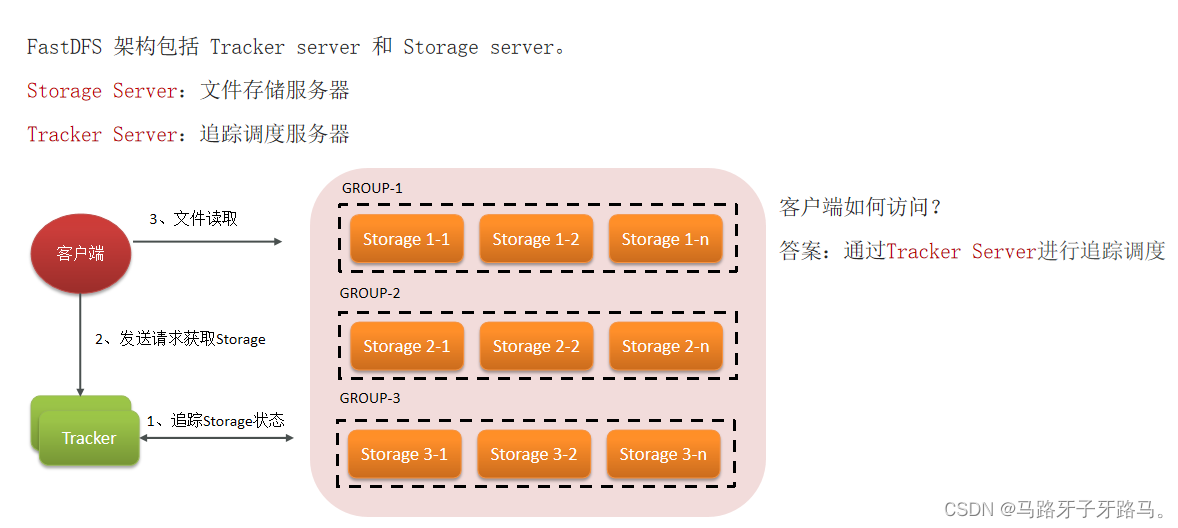
Tracker server
配置集群
Tracker server监控各个Storage server,调度存储服务
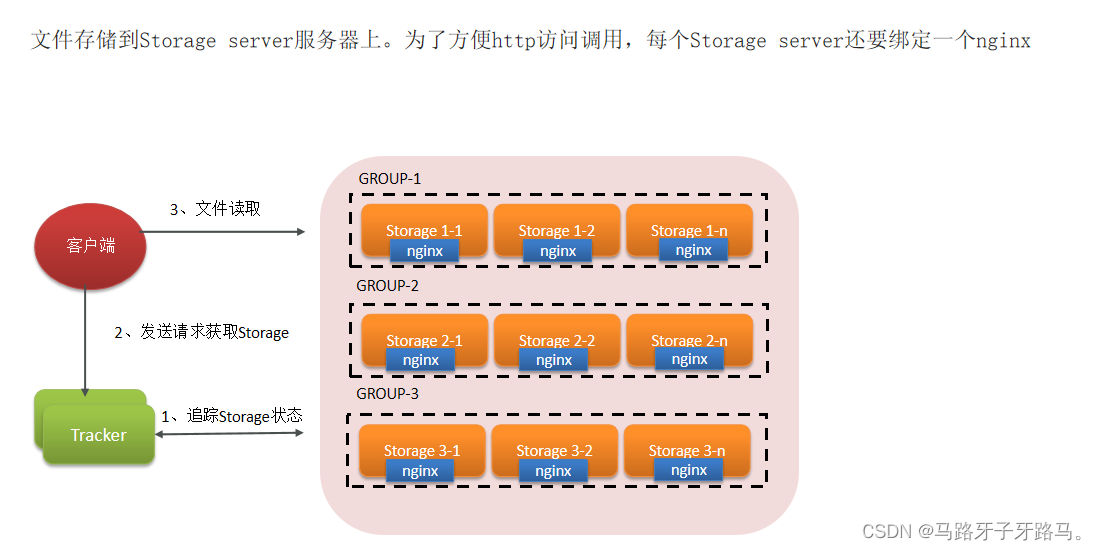
Storage server
Storage server(存储服务器),文件最终存放的位置
通过Group(组),拓展文件存储容量
各个Group(组)中,通过集群解决单点故障
2.工作原理
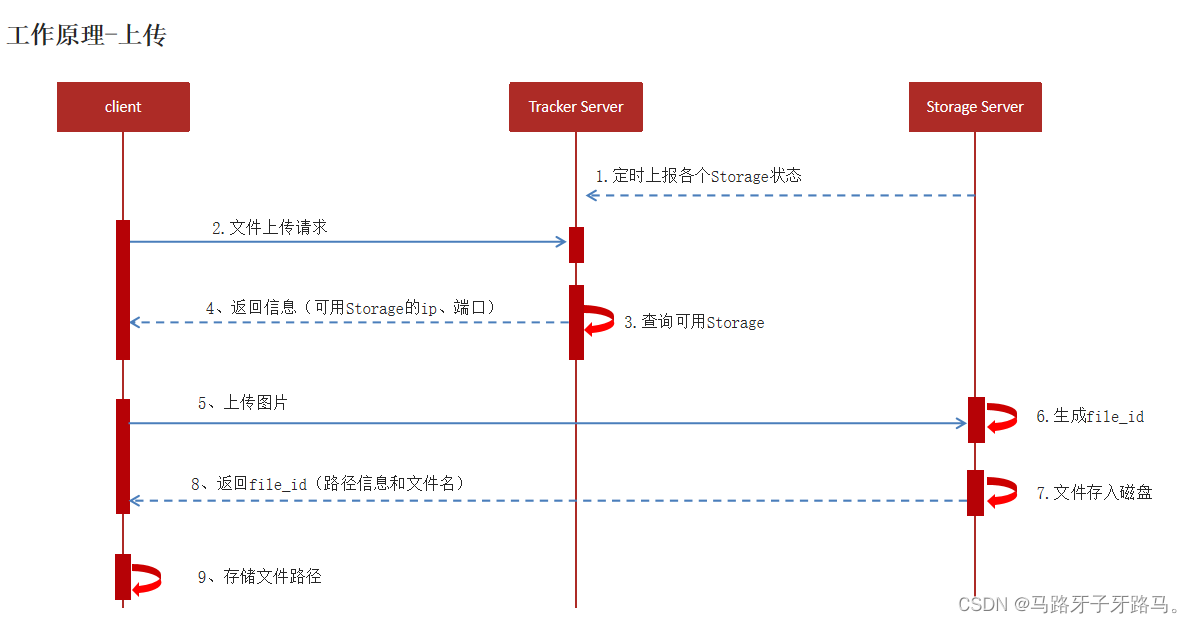
文件上传
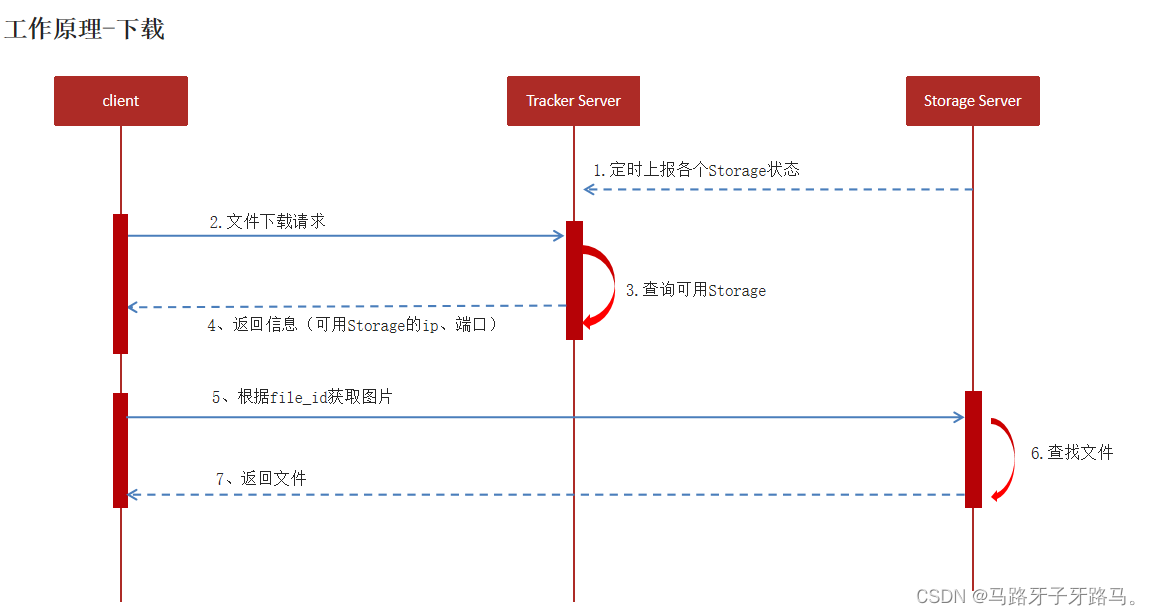
Storage Server 向Tracker Server, 汇报当前存储节点的状态信息(包括磁盘剩余空间、 文件同步状况等统计信息)
客户端程序连接Tracker Server发给上传请求
Tracker Server计算可用的Storage Server 节点,返回
客户端将文件上传到Storage Server,并获取返回的file_id(包括路径信息和文件名称)
客户端保存请求地址
文件下载
和文件上传类似
文件下载使用频率并不高,由于客户端记录的访问地址,直接拼接地址访问即可
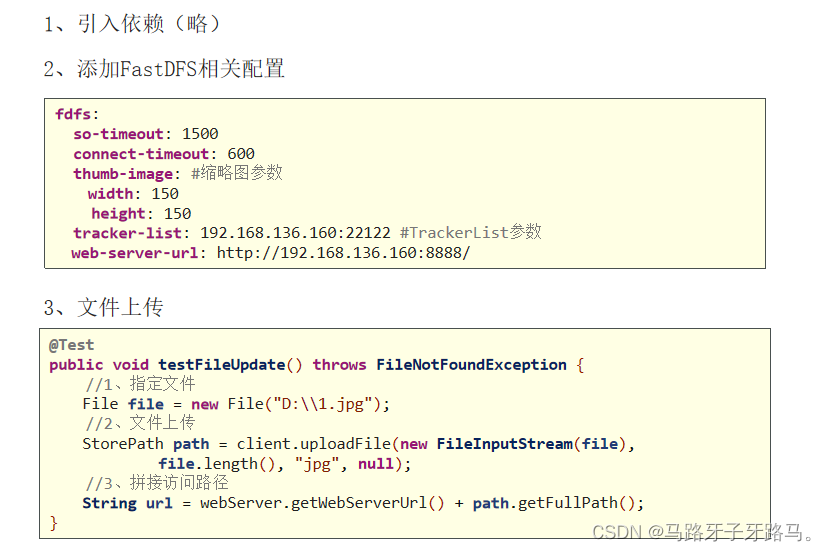
3.使用Java利用fastDFS完成文件上传

















 1998
1998

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









