




一.项目内容
根据已有的训练集去训练模型,再在验证集上验证模型的结果,用准确率来判断模型的好坏
训练集为带标签的数据
如:标签为00的图片如下

此时根据带标签数据280*11,即每类图片各有280张。去验证30*11的验证集,即每类图片30张的准确率情况。
二.代码实现
2.1导入python包
import random
import torch
import torch.nn as nn
import numpy as np
import os
from tqdm import tqdm
from PIL import Image #读取图片数据
from torch.utils.data import Dataset,DataLoader
from torchvision import transforms
import time
2.2设计一个函数固定随机数
#作用是为了固定随机数
def seed_everything(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark=False
torch.backends.cudnn.deterministic=True
random.seed(seed)
np.random.seed(seed)
os.environ['PYTHONHASHSEED']=str(seed)
######################################################
seed_everything(1)
######################################################
**函数定义 seed_everything**:这个函数用于设置随机数种子,确保实验的可重复性。它包括 PyTorch 和 NumPy 的随机种子设置,以及 Python 内部 hash 的种子设置。
2.3定义图片的高度和宽度
HW=224
定义处理图片的高度和宽度为 224 像素(一般用在卷积神经网络中,如 ResNet)
2.4定义存储图片的空间大小
def read_file(path):
for i in tqdm(range(11)):
# tqdm 用来显示循环的进度
file_dir=path+"/%02d"%i
file_list=os.listdir(file_dir) # 列出文件夹下所有的文件名字
xi=np.zeros((len(file_list),HW,HW,3),dtype=np.uint8)
yi=np.zeros(len(file_list),dtype=np.uint8)
**函数定义 read_file**:读取指定路径中的数据。
tqdm用于显示读取文件的进度。os.listdir列出指定文件夹中的所有文件。xi和yi分别用于存储图像数据和对应标签。在这里,xi是一个 4D 数组,yi是一个 1D 数组。
2.5将图片调整大小并装入到指定空间中
for j,img_name in enumerate(file_list):
img_path=os.path.join(file_dir,img_name)
img=Image.open(img_path)
img=img.resize((HW,HW))
xi[j,...]=img
yi[j]=i
读取图片和标签:遍历每个图像文件名,加载图像并调整为 224x224 像素,然后将其存入 xi 和相应的类别标签存入 yi。
2.6将每类数据进行拼接
if i==0:
X=xi
Y=yi
else:
X=np.concatenate((X,xi),axis=0)
Y=np.concatenate((Y,yi),axis=0)
组合数据:如果是第一个类别,直接将数据赋值给 X 和 Y;如果不是,将当前类别的数据拼接到已有数据上。
2.7显示读取数据的进度
print("读到了%d个数据"%len(Y))
return X,Y
2.8数据增强和预处理
train_transform=transforms.Compose(
[
transforms.ToPILImage(),
transforms.RandomResizedCrop(224),
transforms.RandomRotation(50),
transforms.ToTensor()
]
)
训练时的数据增强:定义一个数据处理管道,用于对训练图像进行数据增强。这包括将 NumPy 数组转换为 PIL 图像、随机裁切、旋转,以及转换为 PyTorch 张量。
val_transform=transforms.Compose(
[
transforms.ToPILImage(),
transforms.ToTensor()
]
)
验证时的数据处理:定义验证时的处理流程,仅包括转换为张量,因为验证数据不需要增强。
2.9Dataset 类定义
class food_Dataset(Dataset):
def __init__(self,path,mode='train'):
self.X,self.Y=read_file(path)
self.Y=torch.LongTensor(self.Y) # 标签转为长整形
if mode=="train":
self.transform=train_transform
else:
self.transform=val_transform
**自定义数据集 food_Dataset**:继承 PyTorch 的 Dataset 类。
- 在初始化方法中读取数据,并确定数据处理方式(增强或标准处理)。
def __getitem__(self,item):
return self.transform(self.X[item]),self.Y[item]
返回数据集大小:实现 __len__ 方法,返回数据集长度。
train_path=r"C:\Users\AIERXUAN\PycharmProjects\machinelearning\deep learning\food-11\training\labeled"
val_path=r"C:\Users\AIERXUAN\PycharmProjects\machinelearning\deep learning\food-11\validation"
训练和验证数据路径:定义训练和验证数据集的路径。
train_set=food_Dataset(train_path,"train")
val_set=food_Dataset(val_path,"val")
实例化数据集:分别创建训练集和验证集的实例。
train_loader=DataLoader(train_set,batch_size=16,shuffle=True)
val_loader=DataLoader(val_set,batch_size=16,shuffle=True)
数据加载器:使用 DataLoader 将数据集封装成可迭代的加载器,设置批次大小为 16,并打乱数据。
2.10定义模型
class myModel(nn.Module):
def __init__(self,num_class): #num_class为分类的个数
super(myModel,self).__init__()
#3*224*224->512*7*7->拉直->全连接分类
self.conv1=nn.Conv2d(3, 64, 3, 1, 1) # ->64*224*224
self.bn1=nn.BatchNorm2d(64) # 归一化
self.relu=nn.ReLU() # 激活
self.pool1=nn.MaxPool2d(2) # 池化 64*112*112
self.layer1=nn.Sequential(
nn.Conv2d(64, 128, 3, 1, 1), # ->128*112*112
nn.BatchNorm2d(128), # 归一化
nn.ReLU(), # 激活
nn.MaxPool2d(2) # 池化 128*56*56
)
self.layer2=nn.Sequential(
nn.Conv2d(128, 256, 3, 1, 1), # ->256*112*112
nn.BatchNorm2d(256) , # 归一化
nn.ReLU(), # 激活
nn.MaxPool2d(2) # 池化 256*28*28
)
self.layer3 = nn.Sequential(
nn.Conv2d(256, 512, 3, 1, 1), # ->512*28*28
nn.BatchNorm2d(512), # 归一化
nn.ReLU(), # 激活
nn.MaxPool2d(2) # 池化 512*14*14
)
self.pool2=nn.MaxPool2d(2) #512*7*7
self.fc1=nn.Linear(25088,1000) #25088->1000
self.relu2=nn.ReLU()
self.fc2 = nn.Linear(1000, num_class) #1000-11
def forward(self,x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.pool1(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.pool2(x)
x = x.view(x.size()[0],-1) #保持第一维不变,剩下的维全部加到第一维上去
x = self.fc1(x)
x = self.relu2(x)
x = self.fc2(x)
return x
**定义模型 myModel**:继承自 PyTorch 的 nn.Module,在初始化方法中定义网络的各层结构。
前向传播:实现 forward 方法,定义输入数据如何通过网络传播,从输入到输出的过程。
2.11定义训练和验证函数
def train_val(model,train_loader,val_loader,device,epochs,optimizer,loss,save_path):
model=model.to(device)
plt_train_loss=[]
plt_val_loss=[]
# 分类任务使用准确率来判断模型的好坏
plt_train_acc =[]
plt_val_acc = []
#保存准确率较高的模型
max_acc=0.0
for epoch in range(epochs): #冲锋的号角
train_loss=0.0
val_loss=0.0
train_acc= 0.0
val_acc = 0.0
start_time=time.time()
model.train() #模型调为训练模式
for batch_x,batch_y in train_loader:
x,target=batch_x.to(device),batch_y.to(device)
pred=model(x)
train_bat_loss=loss(pred,target)
train_bat_loss.backward()
optimizer.step() #更新模型的作用
optimizer.zero_grad()
train_loss += train_bat_loss.cpu().item()
train_acc+=np.sum(np.argmax(pred.detach().cpu().numpy(),axis=1)==target.cpu().numpy())
plt_train_loss.append(train_loss/train_loader.__len__())
plt_train_acc.append(train_acc/train_loader.dataset.__len__()) #记录准确率
model.eval() #验证模式
with torch.no_grad():
#所有在模型上的训练会计算梯度,而在验证集上是不需要更新模型的
for batch_x,batch_y in val_loader:
x, target = batch_x.to(device), batch_y.to(device)
pred = model(x)
val_bat_loss = loss(pred, target)
val_loss+=val_bat_loss.cpu().item()
val_acc += np.sum(np.argmax(pred.detach().cpu().numpy(), axis=1) == target.cpu().numpy())
plt_val_loss.append(val_loss / val_loader.__len__())
plt_val_acc.append(val_acc / val_loader.dataset.__len__()) # 记录准确率
if val_acc>max_acc:
torch.save(model,save_path)
max_acc=val_acc
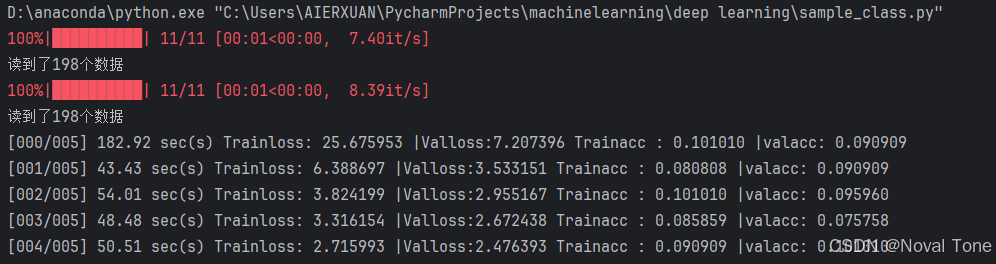
print("[%03d/%03d] %2.2f sec(s) Trainloss: %.6f |Valloss:%.6f Trainacc : %.6f |valacc: %.6f"%\
(epoch,epochs,time.time()-start_time,plt_train_loss[-1],plt_val_loss[-1],plt_train_acc[-1],
plt_val_acc[-1]))
# 画图呈现
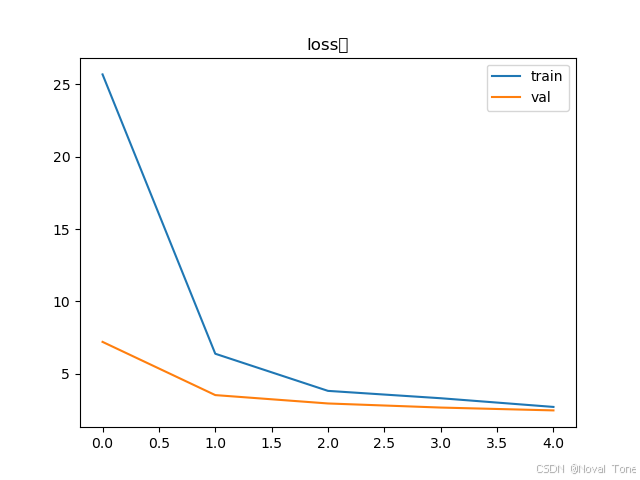
plt.plot(plt_train_loss)
plt.plot(plt_val_loss)
plt.title("loss图")
plt.legend(["train", "val"])
plt.show()
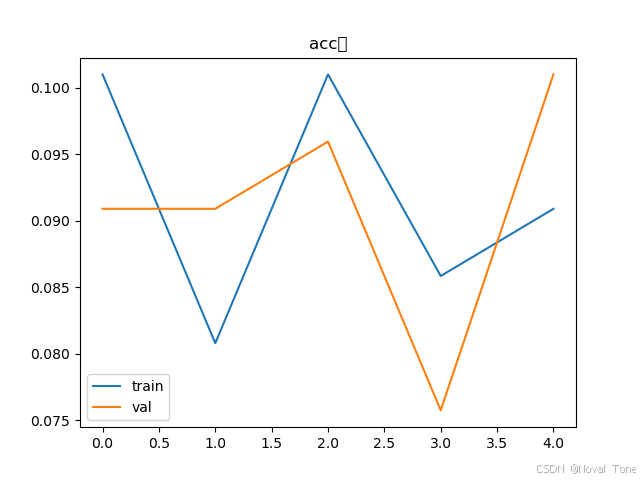
plt.plot(plt_train_acc)
plt.plot(plt_val_acc)
plt.title("acc图")
plt.legend(["train", "val"])
plt.show()
2.12模型实例化和超参数设置
model=myModel(11) #定义一个模型
# from torchvision.models import resnet18
# model=resnet18(pretrained=True) #表示模型即继承架构又继承既有的参数
# in_features=model.fc.in_features
# model.fc=nn.Linear(in_features,11) #设计分类头的大小
#定义超参
lr=0.001
loss=nn.CrossEntropyLoss()
optimizer=torch.optim.AdamW(model.parameters(),lr=lr,weight_decay=1e-4)
device="cuda" if torch.cuda.is_available() else "cpu"
save_path="model_save/sample_class_model.pth"
epochs=5
train_val(model,train_loader,val_loader,device,epochs,optimizer,loss,save_path)
2.13结果呈现


















 1091
1091

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









