



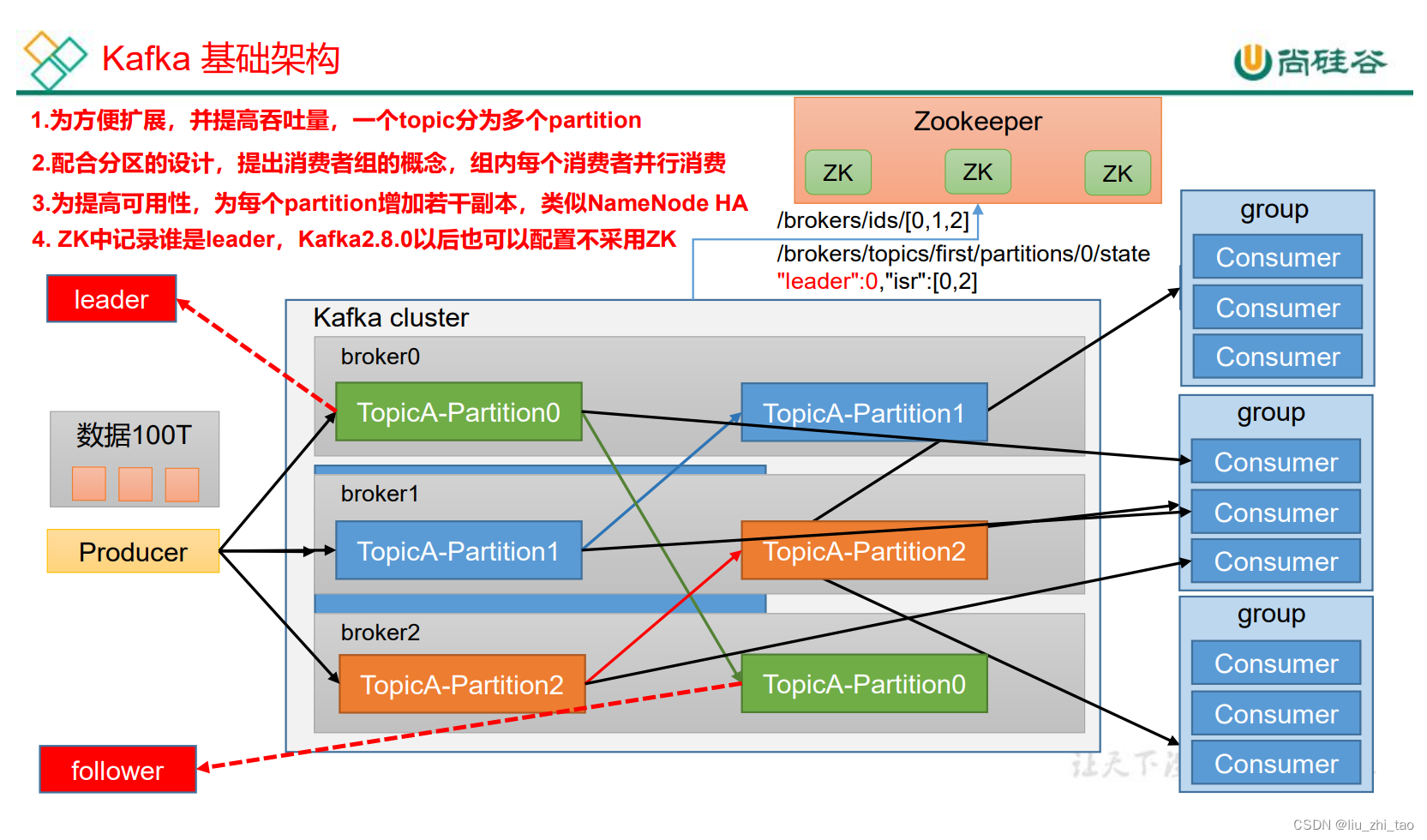
首先讲一下整个kafka的整体架构,kafka有三个很重要的部分,生产者、Broker(3个集群模式)、消费者
1.生产者发送数据到broker,但在大数据环境下,比如说100T的数据,而硬盘容量在8-96T之间,对于100T的数据,我们的做法是分块,也就是broker进行分区处理,从图中可以看出分了三个区,每一个区存放33T数据,这样问题就得以解决,但是如果broker一个结点挂了怎么办,这里就引入了副本,副本的作用就是在leader结点挂了才会起作用,生产者发送消息,消费者消费消息都是在leader里面。对于消费者而言,当然可以一个消费者消费,但是这种方式消费能力太弱。这里会有消费者组的概念,一个分区的消息只能由一个组里面的一个消费者消费。可以保证消费者顺序消费。当然,还有一部分信息在zookeeper里面,主要记录的是节点信息在、brokers/ids/[0,1,2] .还有一个是分区的leader, 这里面还有一个isr。
这是一个基本的流程,当然这里面会有一些细节,比如生产者如何发送数据,leader宕机了,follower怎么选lead,zookeeper里面是如何存放的.这些问题都将在接下来的章节一一解答

















 1141
1141

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









