






👨🎓博主简介
🏅优快云博客专家
🏅云计算领域优质创作者
🏅华为云开发者社区专家博主
🏅阿里云开发者社区专家博主
💊交流社区:运维交流社区 欢迎大家的加入!
🐋 希望大家多多支持,我们一起进步!😄
🎉如果文章对你有帮助的话,欢迎 点赞 👍🏻 评论 💬 收藏 ⭐️ 加关注+💗
文章目录
一、环境准备
| 服务器类型 | IP地址 | 组件 | 开放端口 |
|---|---|---|---|
Prometheus 服务端、node_exporter 客户端1、Grafana 可视化界面 | 172.16.11.230 | Prometheus、node_exporter、Grafana | 9090、9100、3000 |
node_exporter 客户端2 | 172.16.11.231 | node_exporter | 9100 |
node_exporter 客户端3 | 172.16.11.232 | node_exporter | 9100 |
如果有防火墙需开启如下端口:9090(Prometheus)、9100(node_exporters)、3000(Grafana)
二、Prometheus 简介
Prometheus是由SoundCloud开发的开源监控报警系统和时序列数据库(TSDB),基于Go语言开发,是Google BorgMon监控系统的开源版本。Prometheus在2016年加入了云原生计算基金会,成为继Kubernetes之后的第二个项目。
Prometheus是一个开源的监控系统,它可以帮助用户监控各种不同类型的系统和应用程序。Prometheus采用的是pull模型,即它定期从目标系统中拉取指标数据并存储在本地数据库中。这些指标数据可以用于生成图表、警报和报告,以帮助用户了解他们系统的运作状况和性能表现。
Prometheus通过多种数学算法能实现强大的监控需求,原生支持K8S服务发现,能监控容器的动态变化。并且结合Grafana能绘出漂亮图形,然后使用alertmanager或Grafana实现报警。它与其他监控相比有以下主要优势:
-
1>数据格式是
Key/Value形式,简单、速度快;采用多维数据模型(由指标名称和键/值维集定义的timeseries) -
2>timeseries收集是通过HTTP上的拉取(pull mode)模型进行,通过中间网关支持timeseries的推送,通过服务发现或静态配置来发现目标,监控数据的精细程度可达到秒级(数据采集精度高情况下,对磁盘消耗大,存在性能瓶颈,且不支持集群,但可以通过联邦能力进行扩展);,
-
3>不依赖分布式存储,数据直接保存在本地,单节点是自治的,可独立运行管理,可以不需要额外的数据库配置。但是如果对历史数据有较高要求,可以结合OpenTSDB;支持分层和水平联合。
-
4> 周边插件丰富,如果对监控要求不是特别严格的话,默认的几个成品插件已经足够使用;支持多种图形和仪表板。
-
5>本身基于数学计算模型,有大量的函数可用,可以实现很复杂的监控(故学习成本高,需要有一定数学思维,独有的数学命令行很难入门);
-
6>可以嵌入很多开源工具的内部去进行监控,数据更可信。
-
7>使用PromQL,它是一种强大而灵活的查询语言,PromQL作为Prometheus强大的查询语言,可以灵活地处理监视数据。
Prometheus最初是由SoundCloud开发的,现在已经成为了Cloud Native Computing Foundation(CNCF)旗下的一个项目。它有很多优点,包括易于安装和配置、支持动态发现、具有高可用性和灵活的查询语言等。此外,Prometheus集成了一个强大的警报系统,可以根据用户自定义的规则进行警报通知,并支持多种通知方式,如Email、Slack和PagerDuty等。
在现代应用程序和微服务架构的时代,Prometheus已经成为了一个被广泛采用的监控解决方案。
【Prometheus的3大局限性】
- 更多地展示的是趋势性的监控
Prometheus作为一个基于度量的系统,不适合存储事件或者日志等,它更多地展示的是趋势性的监控。如果用户需要数据的精准性,可以考虑ELK或其他日志架构。另外,APM更适用于链路追踪的场景。- Prometheus本地存储不适合大量历史数据存储
Prometheus认为只有最近的监控数据才有查询的需要,所有Prometheus本地存储的设计初衷只是保存短期(如一个月)的数据,不会针对大量的历史数据进行存储。如果需要历史数据,则建议使用Prometheus的远端存储,如OpenTSDB、M3DB等。- 成熟度没有InfluxDB高
Prometheus在集群上不论是采用联邦集群还是采用Improbable开源的Thanos等方案,都没有InfluxDB成熟度高,需要解决很多细节上的技术问题(如耗尽CPU、消耗机器资源等问题),部分互联网公司拥有海量业务,出于集群的原因会考虑对单机免费但是集群收费的InfluxDB进行自主研发。
总之,使用Prometheus一定要了解它的设计理念:它并不是为了解决大容量存储问题,TB级以上数据建议保存到远端TSDB中;它是为运行时正确的监控数据准备的,无法做到100%精准,存在由内核故障、刮擦故障等因素造成的微小误差。
Prometheus它可使用联合模型(federation mode)进行扩展,该模型使得一个 Prometheus 服务器能够抓取另一个 Prometheus 服务器的数据。这允许创建分层拓扑,其中中央系统或更高级别的 Prometheus 服务器可以抓取已从下级实例收集的聚合数据。你可以将 Prometheus 作为后端,配置 Grafana 来提供数据可视化和仪表板功能。
2.1 工作原理
Prometheus直接从目标主机上运行的代理程序中抓取指标,并将收集的样本集中存储在自己服务器上(主要以拉模式为主)。也可以使用像 collectd_exporter 这样的插件推送指标,尽管这不是 Promethius 的默认行为,但在主机位于防火墙后面或位于安全策略禁止打开端口的某些环境中它可能很有用。另外,它可通过HTTP协议周期性抓取被监控组件的状态,任意组件只要提供对应的HTTP接口就可以接入监控。不需要任何SDK或者其他的集成过程。这样做非常适合做虚拟化环境监控系统,比如:VM、Docker、Kubernetes等;它以给定的时间间隔从已配置的目标收集指标,评估规则表达式,显示结果,并在发现某些情况为真时触发警报。
2.2 Prometheus的主要构成
1、服务端
Prometheus服务端以一个进程方式启动,如果不考虑参数和后台运行的话,只需要解压安装包之后运行 ./prometheus脚本 即可启动,程序默认监听在9090端口。每次采集到的数据叫做metrics。这些采集到的数据会先存放在内存中,然后定期再写入硬盘,如果服务重新启动的话会将硬盘数据写回到内存中,所以对内存有一定消耗。Prometheus不需要重视历史数据,所以默认只会保留15天的数据。
2、客户端
Prometheus客户端分为pull和push两种方式。如果是pull形式的话则是服务端主动向客户端拉取数据,这样需要客户端上安装exporters(导出器)作为守护进程,官网上也提供了很多exporters可以下载使用,比如使用最多的node_exporters,几乎把系统自身相关数据全部采集了,非常全面,node_exporter默认监听9100端口。
如果是push形式的话客户端需要安装pushgateway插件,然后需要运维人员用脚本把监控数据组织成键值形式提交给pushgateway,再由它提交给服务端。它适合于现有exporters无法满足需求时,自己灵活定制。
2.3 prometheus 相关核心概念
a)、指标
prometheus 所有的监控指标(Metric) 被统一定义为
<metric name >{
<label name>=<label value>,
...
}
指标名称: 说明指标的含义,例如 tcp_request_total 代表 tcp 的请求总数,指标名称必须由 字母、数值、下画线或者冒号 组成,符合正则表达式,如 [a-zA-Z:][a-zA-Z0-9:]*。标签(label) 则用于过滤和聚合;
b)、数据采集
prometheus默认采用pull 方式采集监控数据,和push 方式采集监控数据不同;
- pull 方式:master 按固定周期(默认 15 s,可配)主动请求 agent 的 /metrics 接口,agent 仅实时暴露当前值,无需本地落盘;master 只维护目标列表及最后一次抓取是否成功。
- push 方式:agent 主动将当前指标立即 POST 到监控中心,本地不存历史数据,agent 无状态;中心需记录“谁推过、多久未推”等上下文。
c)、数据处理
Prometheus 在抓取和告警阶段都支持 relabeling,可对标签做 replace、keep、drop、hashmod、labelkeep、labeldrop、lowercase、uppercase 等处理,用于过滤目标、修改或精简标签。
d)、数据存储
prometheus 支持本地存储和远程存储两种方式
Prometheus 采用本地时序数据库存储,同时提供 remote_write/remote_read 接口,可将数据桥接到外部长期存储系统,实现“本地+远程”两级方案。
e)、数据查询
Prometheus 内置 PromQL(Prometheus Query Language),支持对时序数据进行实时查询、聚合、统计、预测,并用于 Grafana 可视化、告警规则和录制规则。
f)、告警
prometheus 本身不会对报警进行处理、需要借助一个组件alertmanager ,prometheus 会配置alertmanager 地址,这样prometheus 发出的告警记录变可以发送到alertmanager 进行处理
Prometheus 自身只负责按告警规则生成 Alert 事件并发送 HTTP 通知,不进行静默、聚合、路由、抑止等后续处理。它通过配置 alertmanager.yml 中的地址将告警批量推送给 AlertManager,由后者完成分组、路由、去重、静默及邮件、钉钉、Slack 等渠道的发送。
2.4 系统架构


三、部署 Prometheus(普罗米修斯)
3.1 下载安装包(两种方式)
3.1.1 直接在官网下载
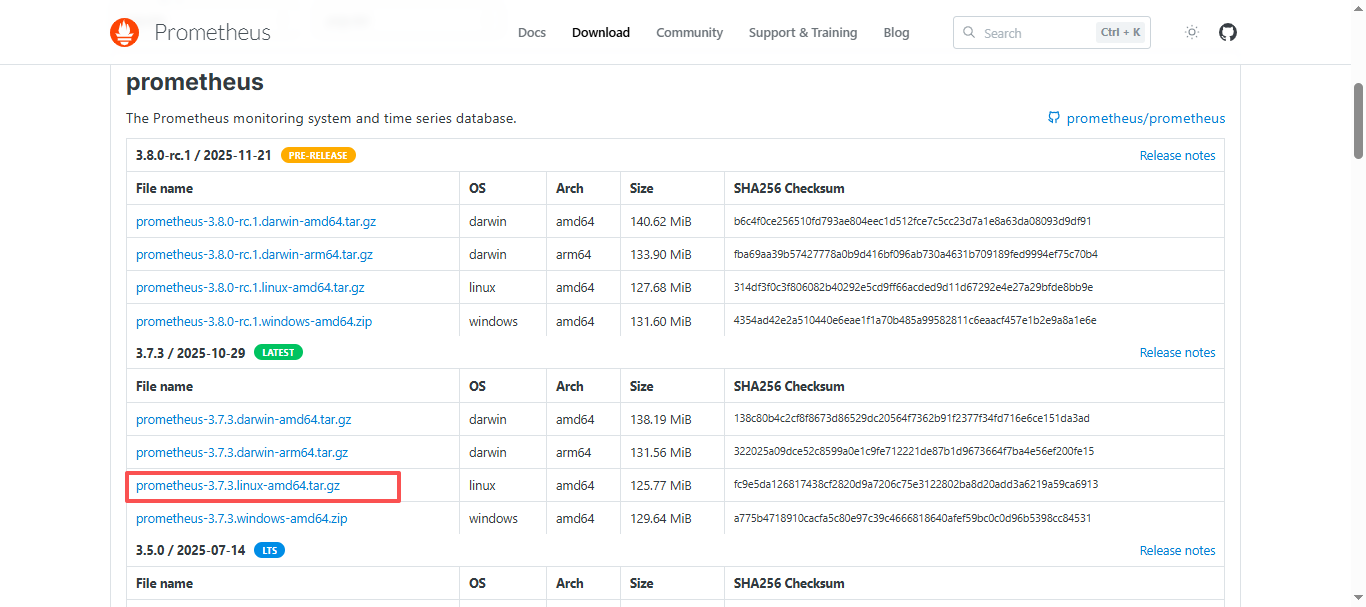
选择版本,根据自己需求选择下载版本,例如我现在是在linux x86架构上部署,所以,选择linux-amd64.tar.gz即可;
三种标签颜色代表的意义:
| 标签颜色 | 含义 | 说明 |
|---|---|---|
| 橙色 Pre-release | 预发布/候选版 | 功能已冻结但尚未经过广泛验证,可能仍有 bug,不建议生产直接使用。 |
| 绿色 Latest | 当前最新稳定版 | 官方推荐下载的正式版本,生产环境可放心使用。 |
| 紫色 LTS | 长期支持版 | 官方会为此版本提供长达 1 年的 bugfix 与安全补丁,适合对稳定性要求极高的场景。 |
点击,等待下载完成,上传到服务器中;
3.1.2 服务器上直接使用wget下载
官网下载地址:https://prometheus.io/download/,找到自己要下载的版本,右击点击复制连接,复制到linux中使用
wget命令下载;
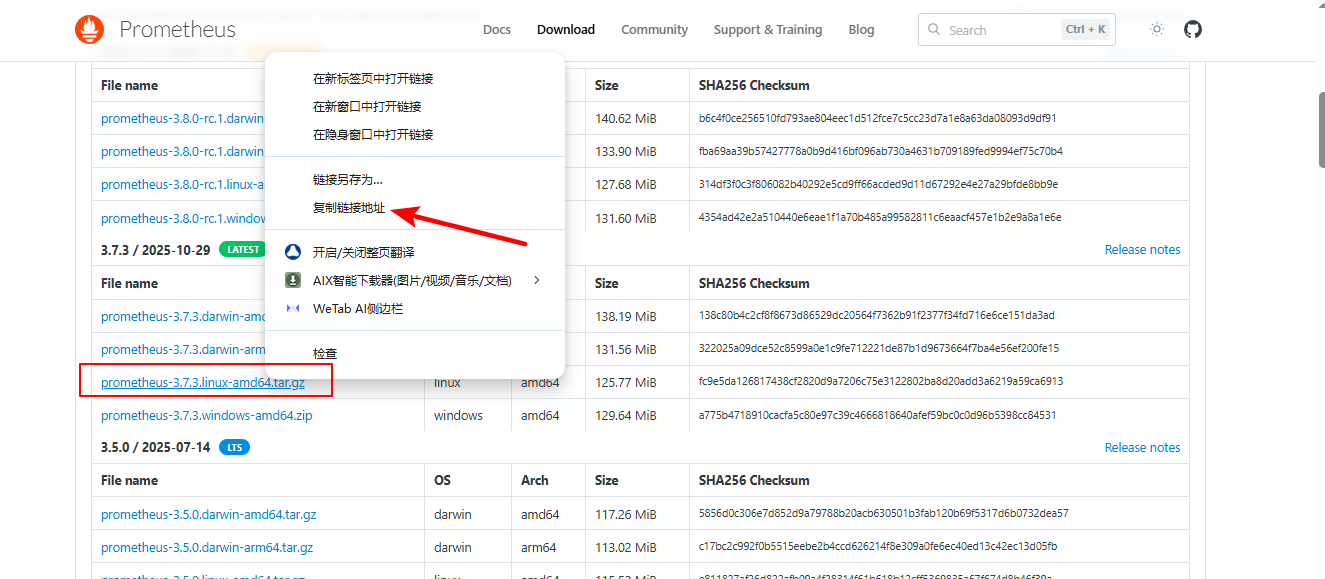
在服务器上使用wget命令下载
wget https://github.com/prometheus/prometheus/releases/download/v3.7.3/prometheus-3.7.3.linux-amd64.tar.gz
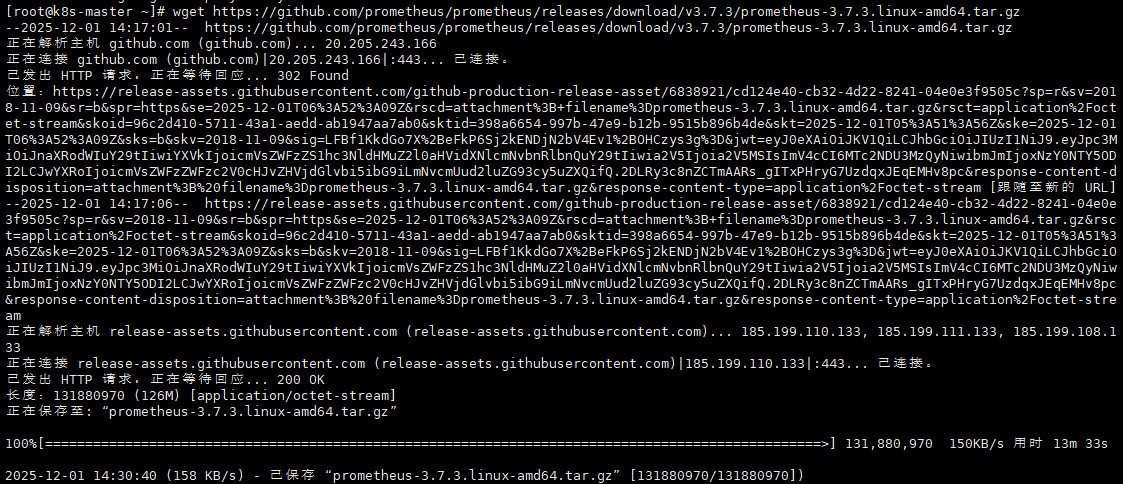
等待下载完成。。。
3.2 解压安装包并放到指定目录
#解压安装包
tar xf prometheus-3.7.3.linux-amd64.tar.gz
#移动到/usr/local/目录,并修改名字
mv prometheus-3.7.3.linux-amd64 /usr/local/prometheus
3.3 修改 Prometheus 配置文件
#进入Prometheus目录
cd /usr/local/prometheus/
#备份默认配置文件
cp -ar prometheus.yml prometheus.yml-bak
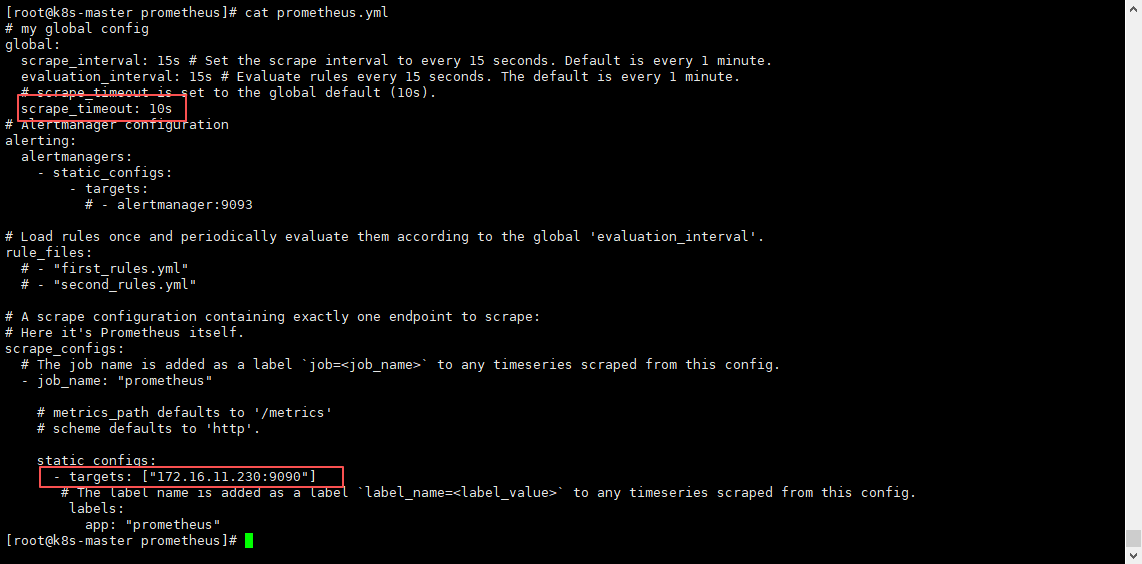
#修改配置文件
## 第六行添加:单次 HTTP 拉取的超时时间
scrape_timeout: 10s
## 找到最后的targets:吧localhost改为本机的ip(其实不改也可以,为了分辨,建议修改)
- targets: ["172.16.11.230:9090"]
修改两处配置:
3.4 配置系统启动文件,设置开机自启 (两种方式:推荐第一种)
3.4.1 第一种:配置系统启动文件,启动并设置开机自启
#进入这个文件,默认是没有的,直接进入就行
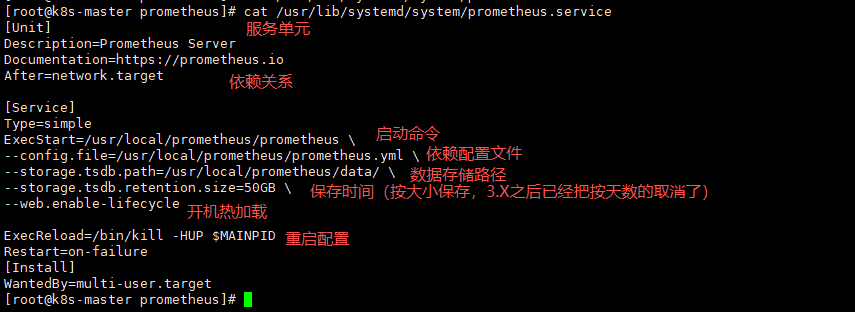
vim /usr/lib/systemd/system/prometheus.service
#将下面的全部写进去
[Unit]
Description=Prometheus Server
Documentation=https://prometheus.io
After=network.target
[Service]
Type=simple
ExecStart=/usr/local/prometheus/prometheus \
--config.file=/usr/local/prometheus/prometheus.yml \
--storage.tsdb.path=/usr/local/prometheus/data/ \
--storage.tsdb.retention.size=50GB \
--web.enable-lifecycle
ExecReload=/bin/kill -HUP $MAINPID
Restart=on-failure
[Install]
WantedBy=multi-user.target
# 给此service可执行权限
chmod 775 /usr/lib/systemd/system/prometheus.service
# 配置开机自启并启动服务
systemctl enable --now prometheus
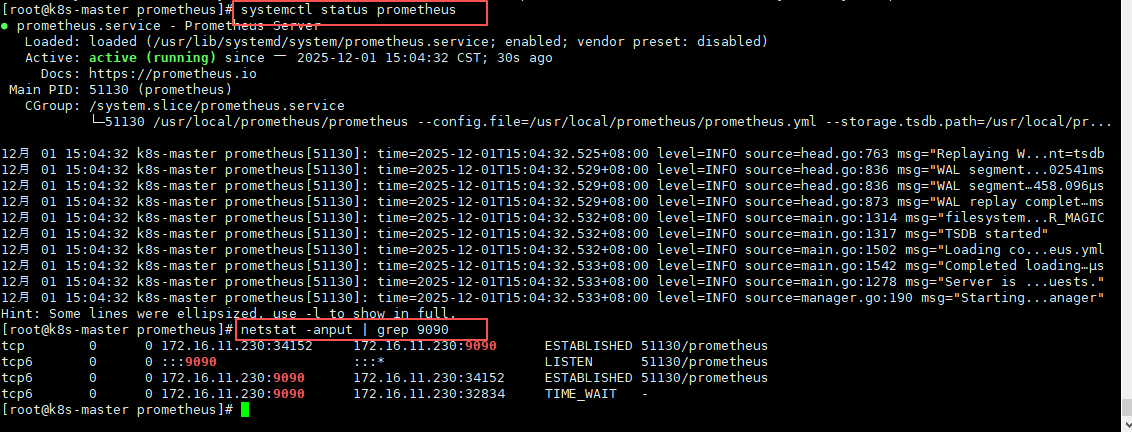
# 查看服务状态(是否启动成功)
systemctl status prometheus
#查看端口是否启动9090
netstat -anput | grep 9090
3.4.2 第二种:进入解压目录,挂后台执行./prometheus
#进入解压目录
cd /usr/local/prometheus
#挂后台执行./prometheus
./prometheus &
#查看端口是否启动
netstat -anput | grep 9090

也是可以启动的,但是不好的是,不能设置开机自启,如果想要开机自启,还是需要手动写一个启动服务器去执行他的命令或者周期性计划任务,所以不推荐使用方法二;推荐使用第一种。
3.5 页面访问
浏览器访问:
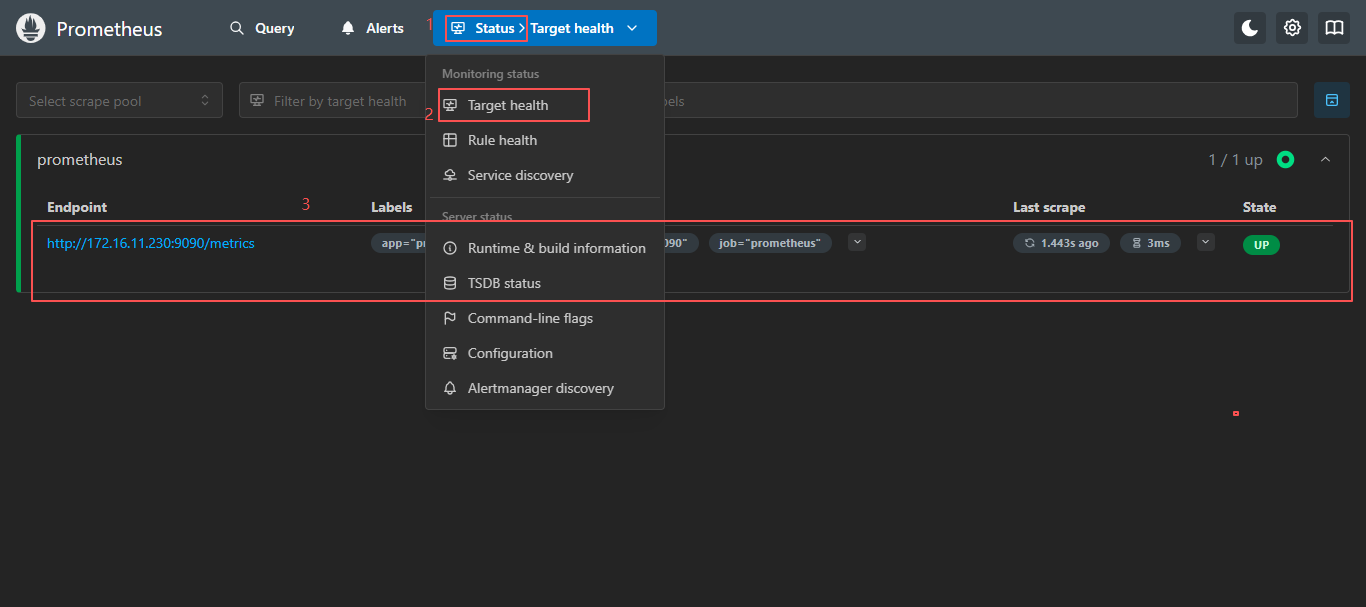
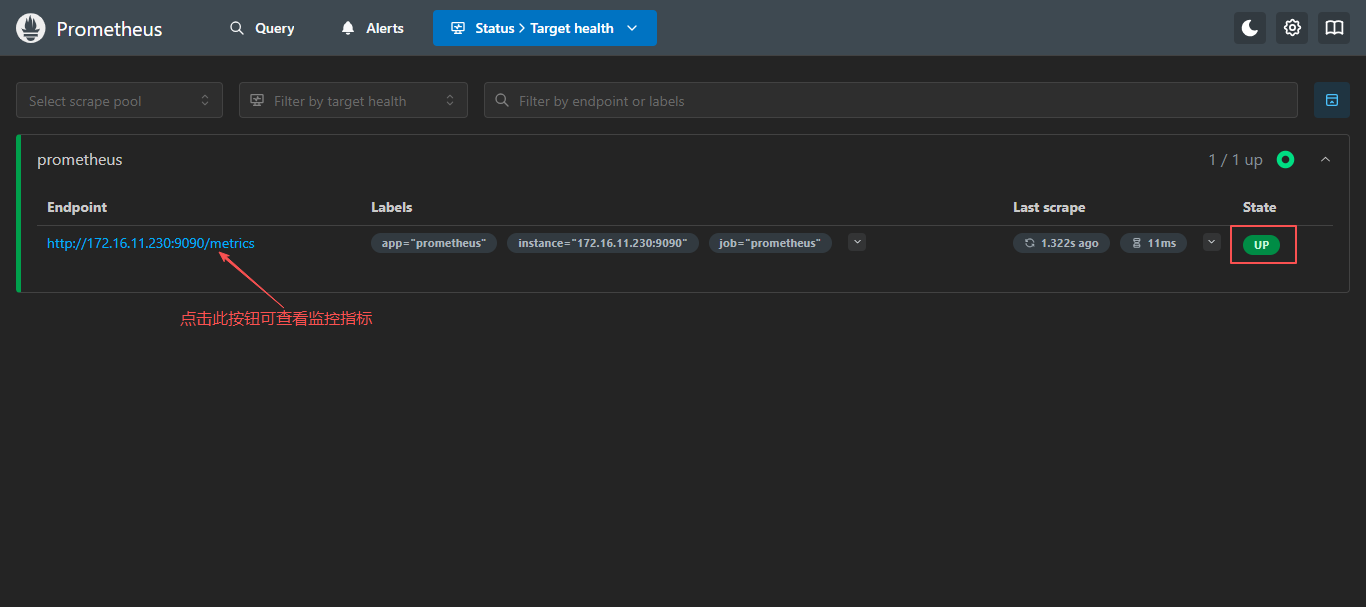
http://172.16.11.230:9090,访问到 Prometheus 的 Web UI 界面
点击页面的Status-->Target health,如看到 Target 状态都为 UP,说明 Prometheus 可以正常采集到数据
3.6 服务端安装完成
至此,Prometheus 服务端安装完成。
四、部署 node_exporter(被监控节点组件 - 客户端)
node_exporter是装在被监控节点本地的轻量级代理/指标出口,类似于客户端;
node_exporter只是Prometheus中一种被监控节点,还有其他的,都负责各自不同的领域,例如:node_exporter主要负责监控 Linux系统级 CPU、内存、磁盘、网络、负载等硬件与内核指标;还有其他的如下:
- 常见官方/社区 Exporter
| Exporter | 用途 |
|---|---|
| node_exporter | Linux/Unix 系统级 CPU、内存、磁盘、网络、负载等硬件与内核指标。 |
| blackbox_exporter | 黑盒探活:HTTP、HTTPS、TCP、ICMP、DNS 探测,可测延迟、证书过期等。 |
| mysqld_exporter | MySQL/MariaDB 连接数、慢查询、QPS、主从延迟等。 |
| redis_exporter | Redis 内存、命中率、连接、慢日志、集群信息。 |
| kafka_exporter | Kafka 各 topic 消费延迟、leader 分布、副本缺失等。 |
| snmp_exporter | 网络设备(交换机、防火墙、打印机)SNMP OID 指标。 |
| pushgateway | 短周期脚本/批任务 push 指标的中转站,供 Prometheus 拉取。 |
| statsd_exporter | 接收 StatsD 格式 UDP/TCP 指标并转换为 Prometheus 格式。 |
| memcached_exporter | Memcached 命中率、内存用量、连接数、命令统计等。 |
| consul_exporter | Consul 集群节点健康、KV 数量、Leader 状态、服务数等。 |
| graphite_exporter | 接收 Graphite 明文/ pickles 协议指标并转 Prometheus 格式。 |
4.1 下载安装包(两种方式)
4.1.1 直接在官网下载
官网下载地址:https://prometheus.io/download/
使用ctrl+f快捷键搜索node_exporter。
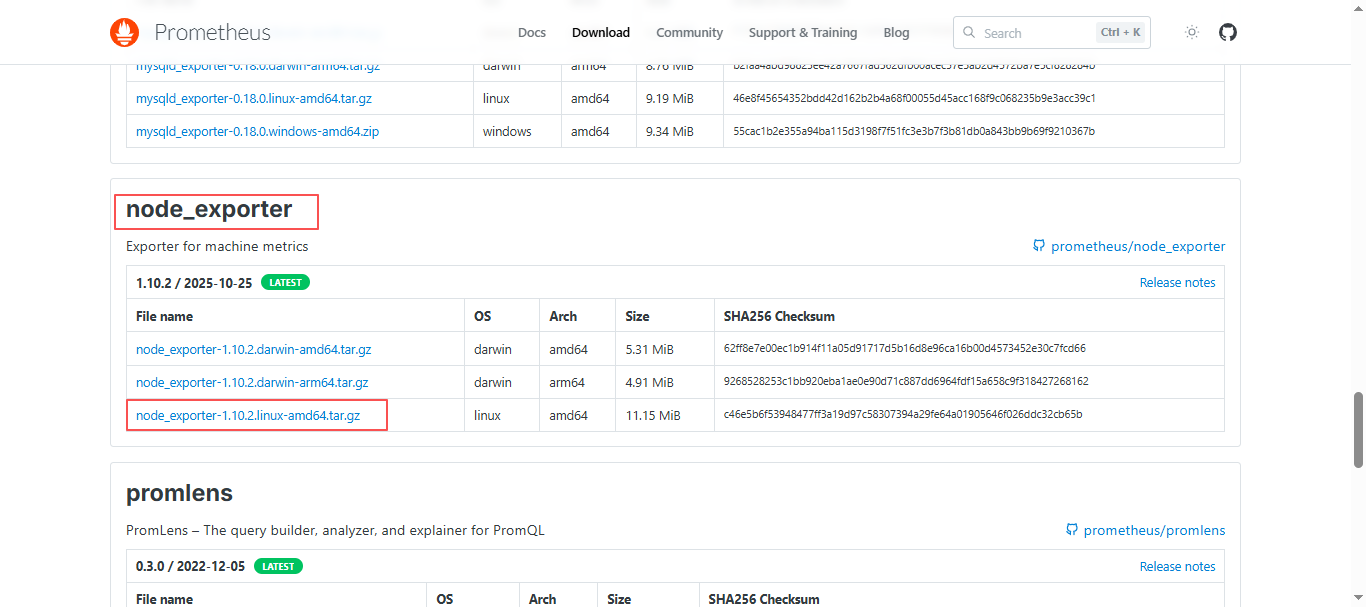
同样也是下载linux x86 版本;点击,等待下载完成,上传到服务器中;
4.1.2 服务器上直接使用wget下载
官网下载地址:https://prometheus.io/download/,使用
ctrl+f快捷键搜索node_exporter,右击点击复制连接,复制到linux中使用wget命令下载;
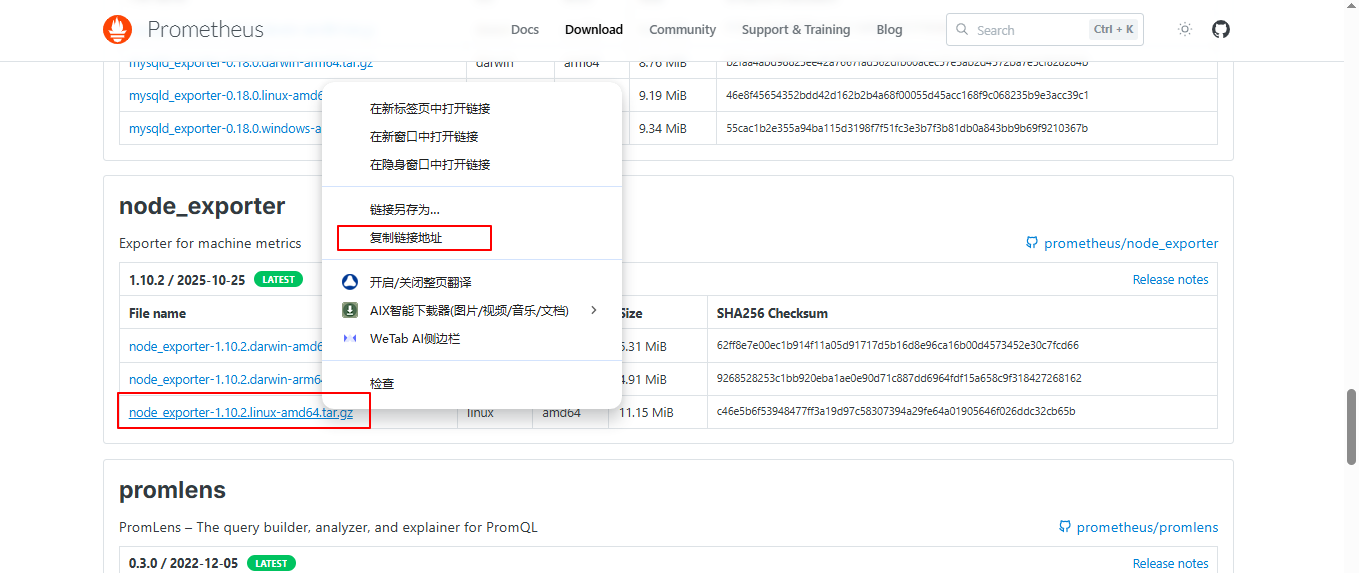
在服务器上使用wget下载
wget https://github.com/prometheus/node_exporter/releases/download/v1.10.2/node_exporter-1.10.2.linux-amd64.tar.gz
4.2 解压安装包并放到指定目录
#解压安装包
tar xf node_exporter-1.10.2.linux-amd64.tar.gz
#移动到/usr/local/目录,并修改名字
mv node_exporter-1.10.2.linux-amd64 /usr/local/node_exporter
4.3 配置系统启动文件,设置开机自启 (两种方式:推荐第一种)
4.3.1 第一种:配置系统启动文件,启动并设置开机自启
#进入这个文件,默认是没有的,直接进入就行
vim /usr/lib/systemd/system/node_exporter.service
#将下面的全部写进去
[Unit]
Description=node_exporter
Documentation=https://prometheus.io/
After=network.target
[Service]
Type=simple
ExecStart=/usr/local/node_exporter/node_exporter \
--collector.ntp \
--collector.mountstats \
--collector.systemd \
--collector.tcpstat
ExecReload=/bin/kill -HUP $MAINPID
Restart=on-failure
[Install]
WantedBy=multi-user.target
# 给此service可执行权限
chmod 775 /usr/lib/systemd/system/node_exporter.service
# 配置开机自启并启动服务
systemctl enable --now node_exporter
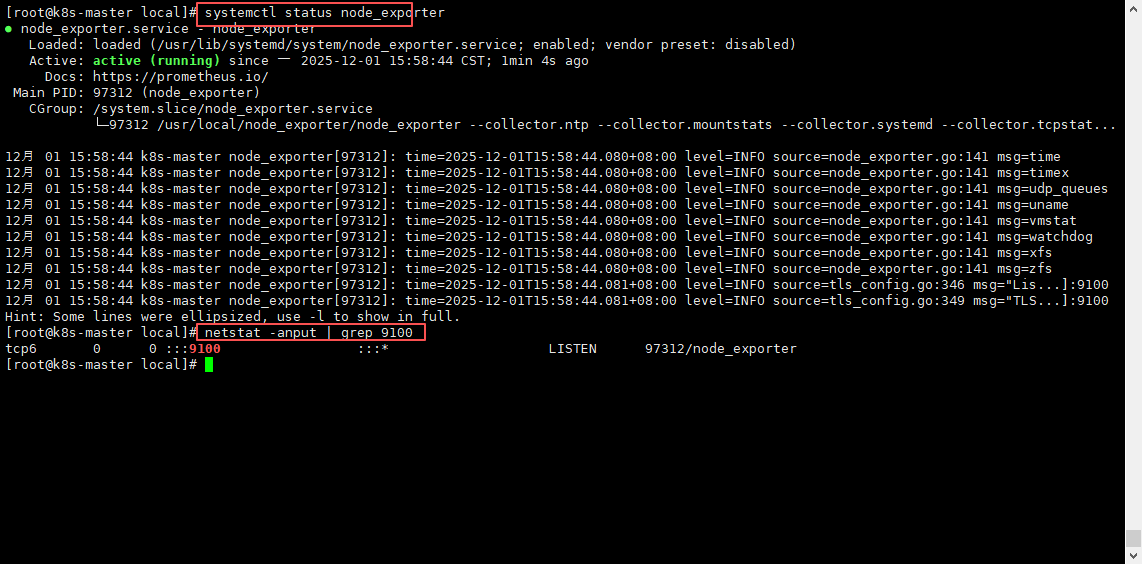
# 查看服务状态(是否启动成功)
systemctl status node_exporter
#查看端口是否启动9100
netstat -anput | grep 9100
4.3.2 第二种:进入解压目录,挂后台执行./node_exporter
#进入解压目录
cd /usr/local/node_exporter
#挂后台执行./prometheus
./node_exporter &
#查看端口是否启动
netstat -anput | grep 9100
也是可以启动的,但是不好的是,不能设置开机自启,如果想要开机自启,还需要手动写一个启动服务器去执行他的命令或者周期性计划任务,所以不推荐使用方法二;推荐使用第一种。
4.4 页面访问
页面访问:
ip:9100
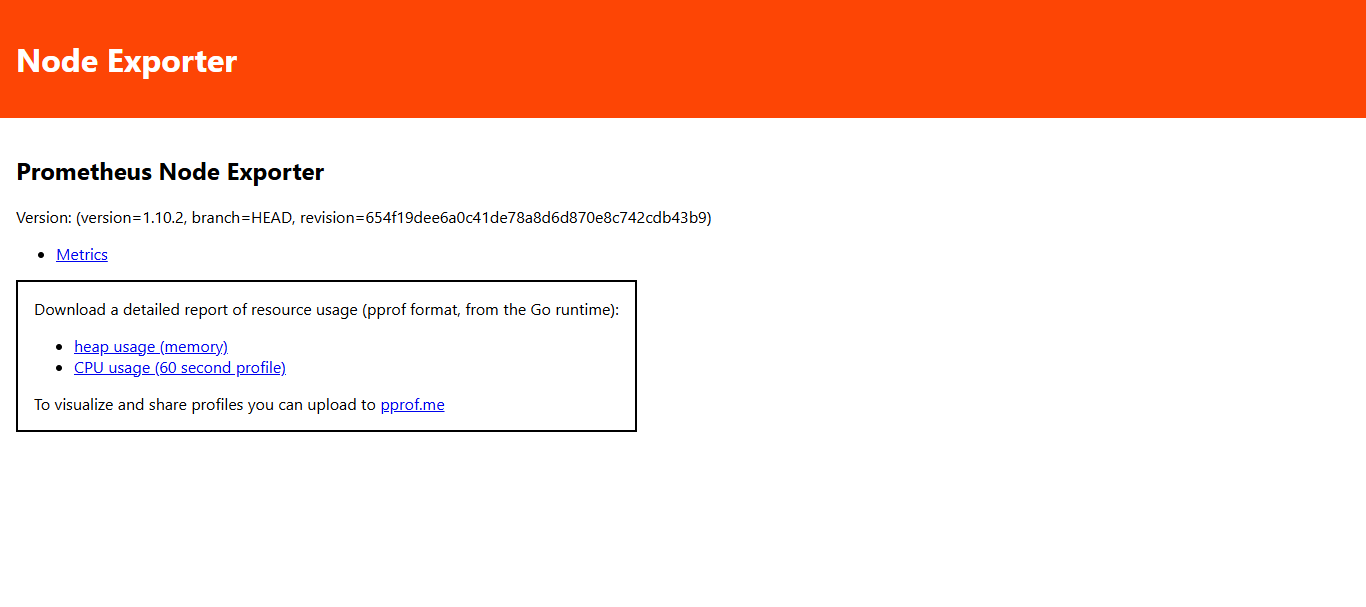
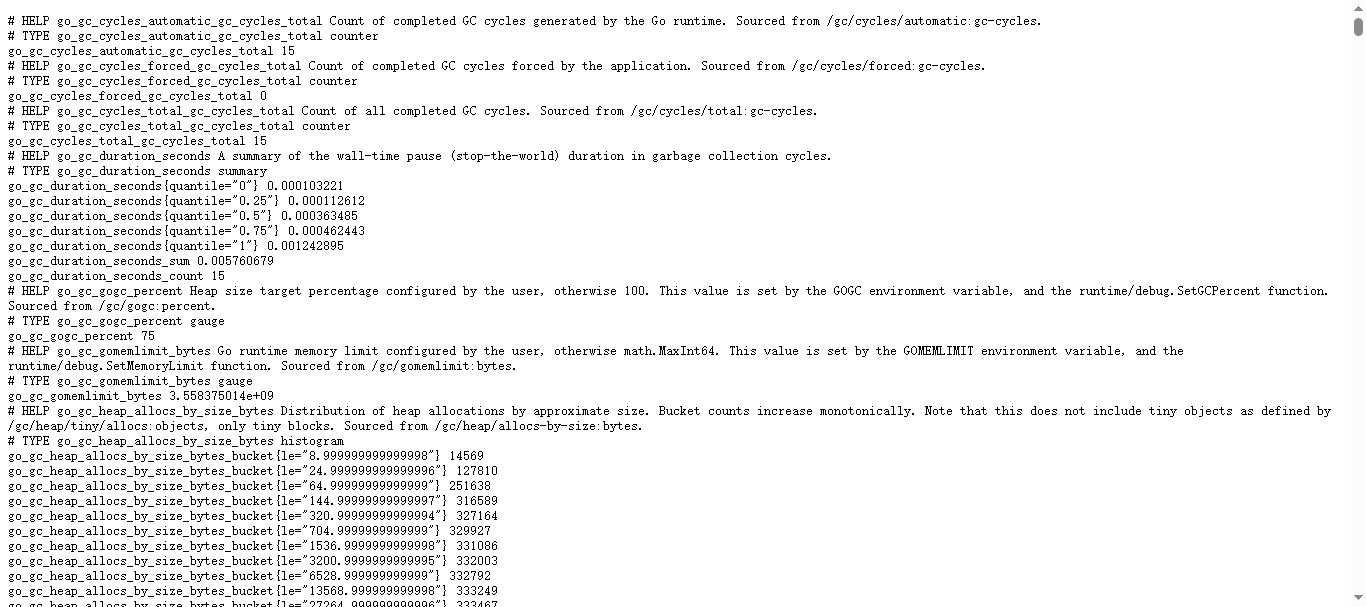
点击Metrics可以查看node_exporter 在被监控端收集的监控信息:

4.5 node_exporter 安装完成
安装完成之后需要等待将此客户端加入到
Prometheus的配置中,方可在Prometheus页面中查看到;
4.6 常见官方/社区 Exporter
| Exporter | 用途 |
|---|---|
| node_exporter | Linux/Unix 系统级 CPU、内存、磁盘、网络、负载等硬件与内核指标。 |
| blackbox_exporter | 黑盒探活:HTTP、HTTPS、TCP、ICMP、DNS 探测,可测延迟、证书过期等。 |
| mysqld_exporter | MySQL/MariaDB 连接数、慢查询、QPS、主从延迟等。 |
| redis_exporter | Redis 内存、命中率、连接、慢日志、集群信息。 |
| kafka_exporter | Kafka 各 topic 消费延迟、leader 分布、副本缺失等。 |
| snmp_exporter | 网络设备(交换机、防火墙、打印机)SNMP OID 指标。 |
| pushgateway | 短周期脚本/批任务 push 指标的中转站,供 Prometheus 拉取。 |
| statsd_exporter | 接收 StatsD 格式 UDP/TCP 指标并转换为 Prometheus 格式。 |
| memcached_exporter | Memcached 命中率、内存用量、连接数、命令统计等。 |
| consul_exporter | Consul 集群节点健康、KV 数量、Leader 状态、服务数等。 |
| graphite_exporter | 接收 Graphite 明文/ pickles 协议指标并转 Prometheus 格式。 |
五、添加客户端到服务端
回到 Prometheus 服务端的配置文件里添加被监控机器的配置段;
5.1 添加客户端到服务端(分为添加单个客户端与多个客户端两部分)
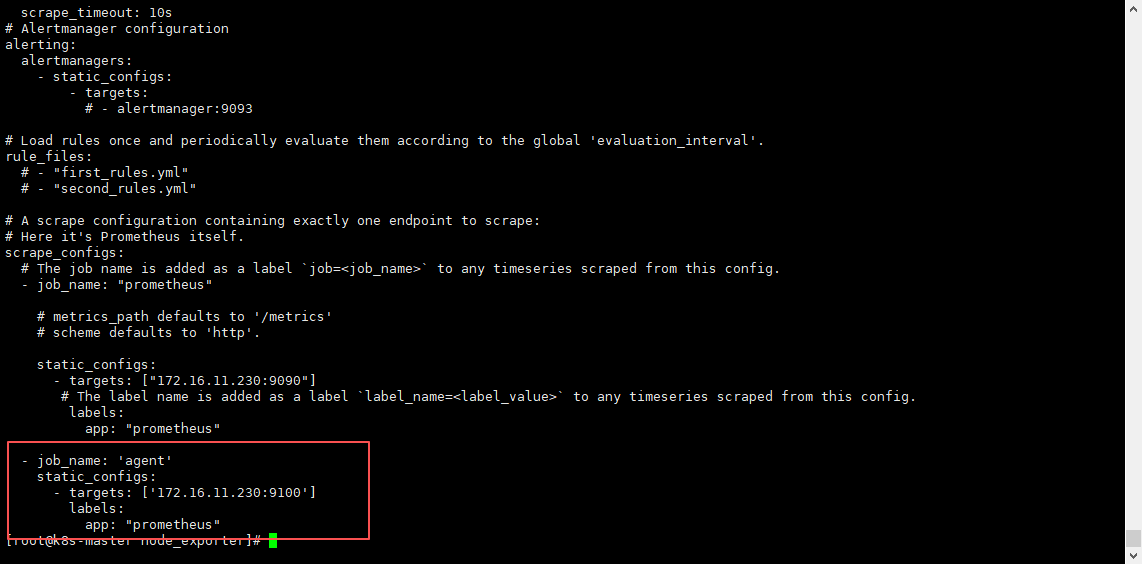
5.1.1 添加单个 客户端
#进入prometheus的配置文件中
vim /usr/local/prometheus/prometheus.yml
#添加以下几行,到最后(格式和上面的服务端一样,因为yml文件格式要求严格,所以必须一样,否则启动会报错)
- job_name: 'agent'
static_configs:
- targets: ['172.16.11.230:9100']
labels:
app: "prometheus"
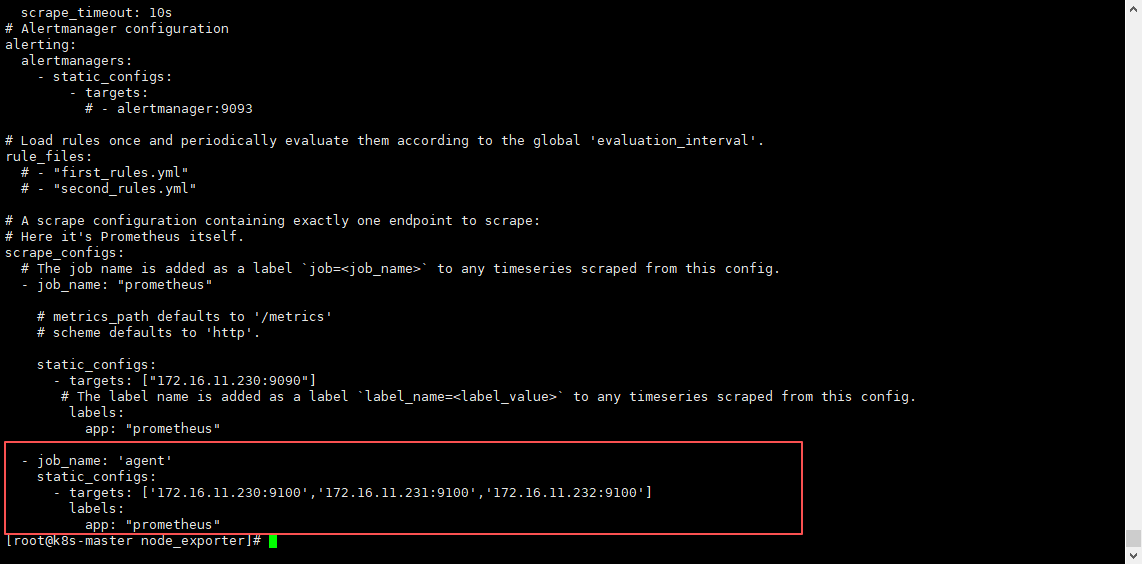
5.1.2 添加多个 客户端
需提前安装
node_exporter组件;
- job_name: 'agent'
static_configs:
- targets: ['172.16.11.230:9100','172.16.11.231:9100','172.16.11.232:9100']
labels:
app: "prometheus"
5.2 重启服务端
systemctl restart prometheus
等待重启完成,刷新一下服务端页面,如果还是没有可以清除一下缓存,在访问试试。
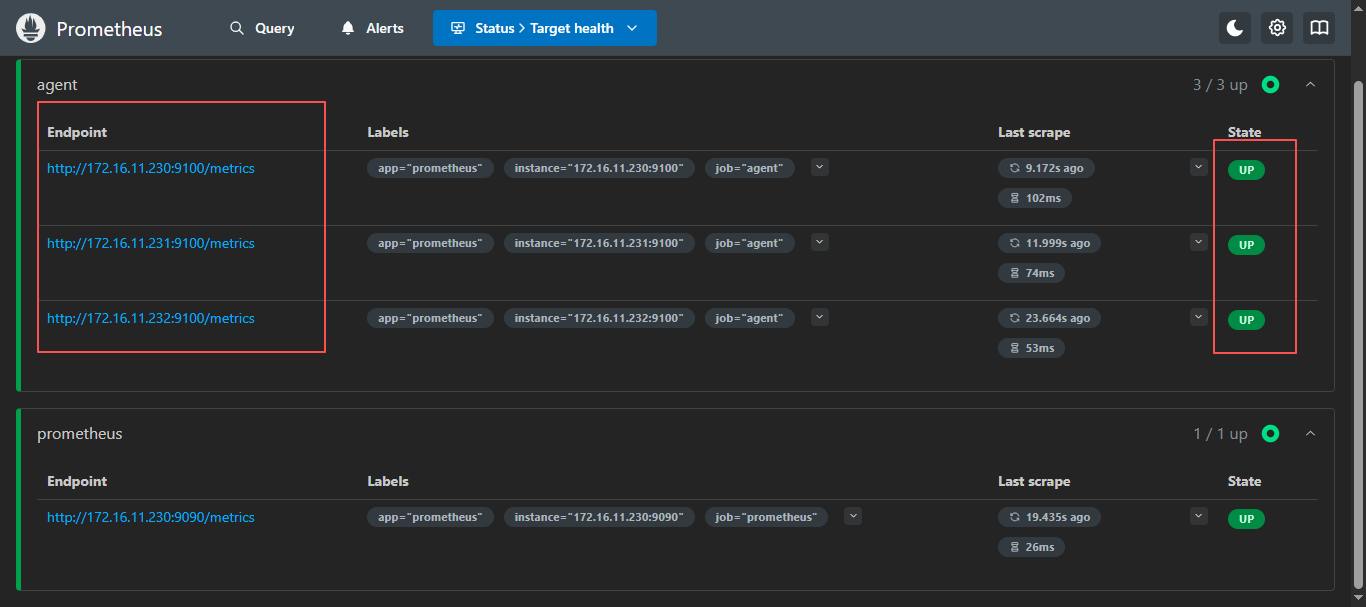
5.3 服务端添加客户端完成
5.4 附加:检测 Prometheus配置文件是否正确
#进入prometheus目录
cd /usr/local/prometheus/
#执行promtool,监测配置是否正确
./promtool check config prometheus.yml
正常状态返回:
Checking prometheus.yml
SUCCESS: prometheus.yml is valid prometheus config file syntax
失败状态返回:
Checking prometheus.yml
FAILED: parsing YAML file prometheus.yml: "172.16.11.230:9999/cs" is not a valid hostname
或其他错误,只有前面是FAILED:都是有问题的,则 SUCCESS:就是没问题的。
六、部署 Grafana(可视化)
6.1 Grafana 简介
Grafana 是一个开源的度量分析和可视化工具,可以通过将采集的数据分析,查询,然后进行可视化的展示,并实现告警。
Grafana是一个开源的数据可视化工具,它可以拉取各种不同的数据源并将它们呈现为漂亮而易于理解的图表。 Grafana可以用于监控和分析各种服务和应用程序的性能和状况,包括数据库、Web服务器、应用程序服务器等。Grafana具有可扩展性,可以支持许多不同的数据源和可视化库,例如Graphite、InfluxDB、Prometheus、Elasticsearch等。同时,Grafana还提供了丰富的插件和面板,帮助用户更好地理解和管理数据。
- 项目需求背景
随着公司业务的不断发展,紧接来的是业务种类的增加、服务器数量的增长、网络环境的越发复杂以及发布更加频繁,从而不可避免地带来了线上事故的增多,因此需要对服务器到应用的全方位监控,提前预警,急需一个工具来解决这个问题,而Grafana的出现完美的解决了这个问题。
-
更适合工业物联网场景数据
IoT领域采集的数据较多是时间序列数据,各类传感器采集的工业现场数据可快速接入在众多panel上进行展现;Grafana 专注于时间序列数据的显示,对各类时序数据库都有很好的支持,显示插件对于时序数据的支持也是优先。 -
多租户和多维度的权限控制
支持多租户的场景,使用Org区分不同的用户,数据源和dashboard进行隔离。多种用户角色,除了支持用户也支持Team的管理。多维度的权限控制,支持org·folder·dashboard三层的权限控制,可满足各种使用场景。 -
仪表板和可视化
Grafana支持众多的显示panel,可帮助您快速构建各类显示效果,满足各类场景的需求,同时通过简单的拖拉缩放即可快速进行排版布局,操作简易方便。支持变量,注释的特性,可方便制作动态panel,同一张dashboard通过动态切换变量更换显示的数据。 -
数据源和集成
支持众多的数据源,内置集成Graphite·Prometheus·InfluxDB·MySQL·PostgreSQL和Elasticsearch等内置插件,另外支持众多的第三方数据源的插件,并可自行进行扩展。方便接入更多的数据来源并进行显示。每种数据源有自己特性化的查询编辑器,帮助用户简单方便掌握各类数据的查询配置。 -
警报和通知
Grafana附带内置警报引擎,允许用户设置一定的条件规则到特定的panel上,数据刷新警报触发之后,可产生一系列的事件,并内置插件支持显示,同时结合notification通知功能,警报触发之后自动发送通知,支持的方式众多(例如,Email,Slack,LINE,Telegram,自定义的webhook等) -
和Prometheus·Loki集成度高
Prometheus是一个领先的开源监控解决方案,属于一站式监控告警平台,依赖少,功能齐全。Loki是一个可水平伸缩、高可用、多租户的日志聚合系统。在grafana上都有高度的集成和方便的使用。 -
插件化的架构,更易于扩展
Grafana是插件化的架构,对于panel·data source·app都可以开发插件进行扩展,插件的开发轻量简易,放入指定插件目录下注册即可生效。对于显示效果的增加或是更多数据源的接入都可以轻松解决。 -
开源社区
拥有强大的用户社区和活跃的贡献者,它已拥有54个数据源,50个面板,17个应用程序和1732个仪表盘。在github上有25000多次提交,并且Star为35.6k之多;持续更新,快速进阶增加新功能。
主要特点
- grafana提供了快速灵活的可视化效果,可以让自己以任何想要的方式来可视化数据



- 支持众多插件 ,使用Grafana插件可以连接自己的工具和团队,数据源插件通过 API 挂接到现有数据源中,实时呈现数据,而无需迁移或引入数据。

- 告警系统,可以在一个简单的UI中创建,管理所有警报从而轻松整合和集中所有警报。


6.2 Grafana 部署
6.2.1 下载并安装 Grafana (安装分两种rpm或二进制)
Grafana 官网下载地址:Download Grafana | Grafana Labs
可以选择版本和系统,我们这里就直接选择最新版:12.3.0
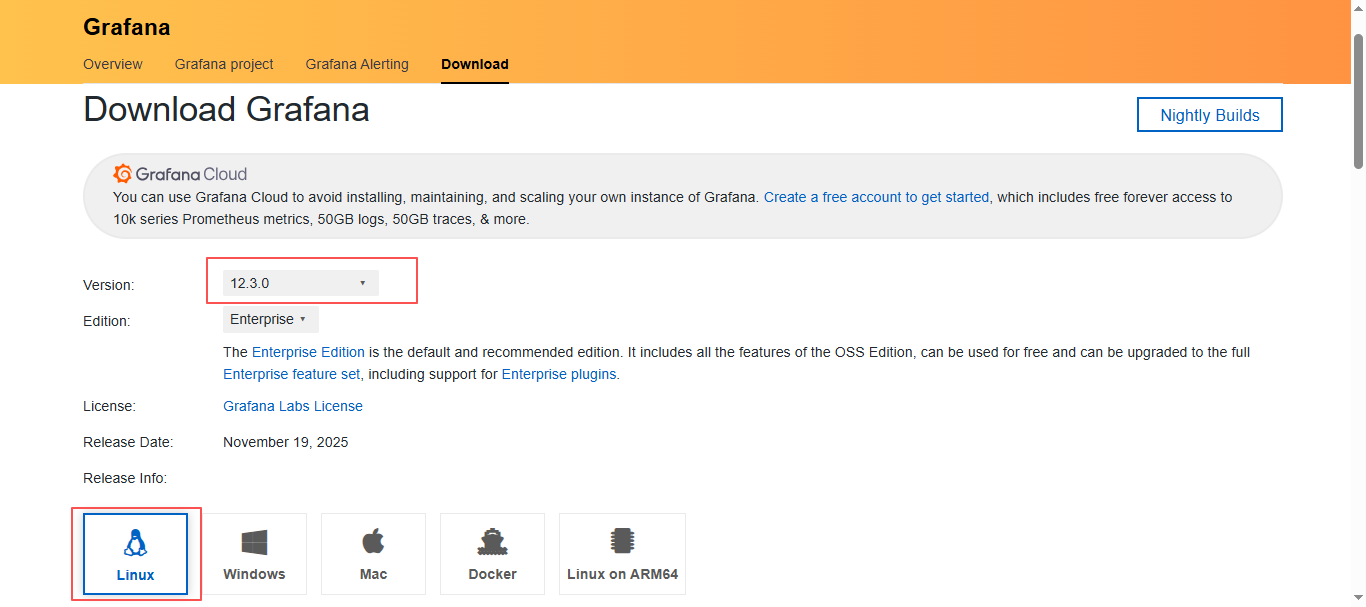
- rpm方式安装
往下翻,就可以看到如何下载,找到对应的操作系统下载方式,这里是centos,所以就可以使用rpm包下载;

等待下载完成…
如果是直接在服务器执行下载的,直接等待下载完成启动即可,如果是下载的rpm包,就需要上传到服务器上,然后使用
rpm -ivh grafana-enterprise-9.5.2-1.x86_64.rpm进行安装;
- 二进制安装,如果非要使用二进制安装,也不是不可以;
- 找到
Standalone Linux Binaries,点击tar.gz下载安装包,或者是直接使用命令在服务器下载安装包;
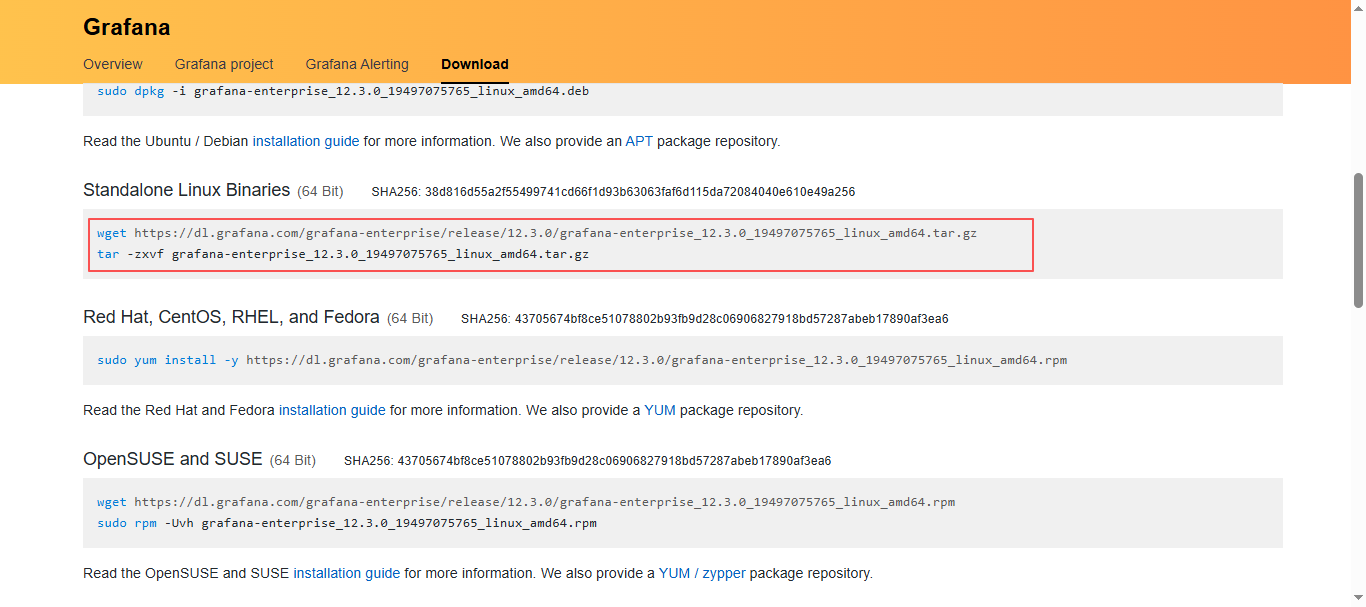
2. 下载完成到服务器上解压并放到指定目录
#解压安装包
tar xf grafana-enterprise_12.3.0_19497075765_linux_amd64.tar.gz
#移动到/usr/local/目录,并修改名字
mv grafana-12.3.0/ /usr/local/grafana
- 配置系统启动文件,设置开机自启
#进入这个文件,默认是没有的,直接进入就行
vim /usr/lib/systemd/system/grafana-server.service
#将下面的全部写进去
[Unit]
Description=Grafana instance
After=network.target
[Service]
Type=simple
WorkingDirectory=/usr/local/grafana/
ExecStart=/usr/local/grafana/bin/grafana-server
Restart=always
RestartSec=3
LimitNOFILE=65536
StandardOutput=syslog
StandardError=syslog
SyslogIdentifier=grafana
[Install]
WantedBy=multi-user.target
6.2.2 启动 grafana 并设置开机自启
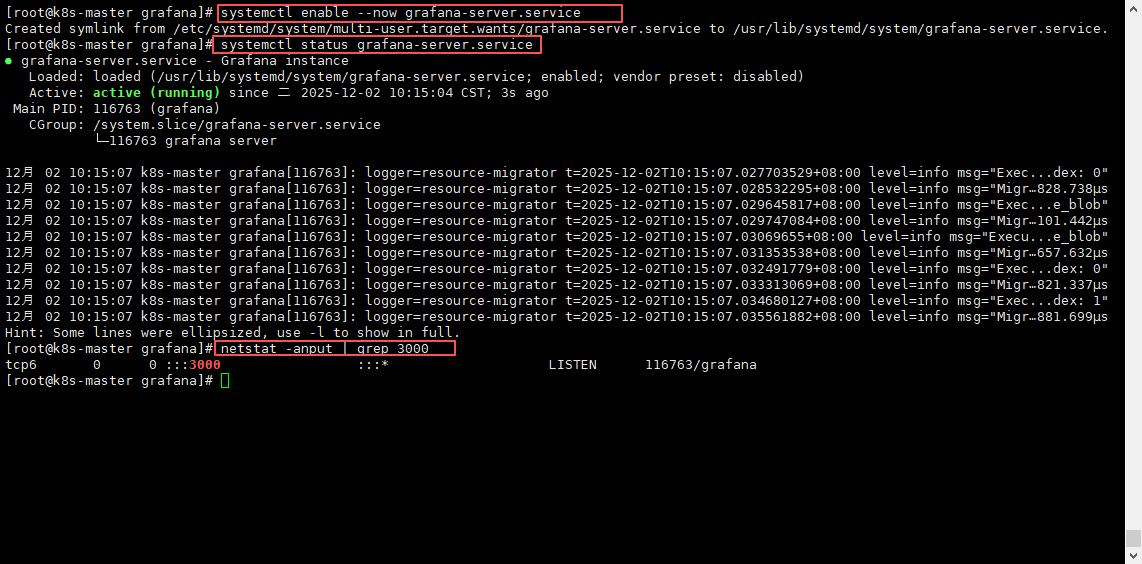
# 配置开机自启并启动服务
systemctl enable --now grafana-server.service
# 查看服务启动状态
systemctl status grafana-server.service
#查看端口是否启动3000
netstat -anput | grep 3000
6.2.3 页面访问
页面访问:
ip:3000
注意:默认账号密码为(可在配置中配置修改admin_user、admin_password):
账号:admin
密码:admin
rpm安装的grafana默认配置在: /etc/grafana/grafana.ini
二进制安装的grafana默认配置在:/usr/local/grafana/conf/defaults.ini
二进制安装的grafana数据存储在(可在配置中配置存储路径):/usr/local/grafana/data/
二进制安装的grafana日志存储在(可在配置中配置存储路径):/usr/local/grafana/data/log/
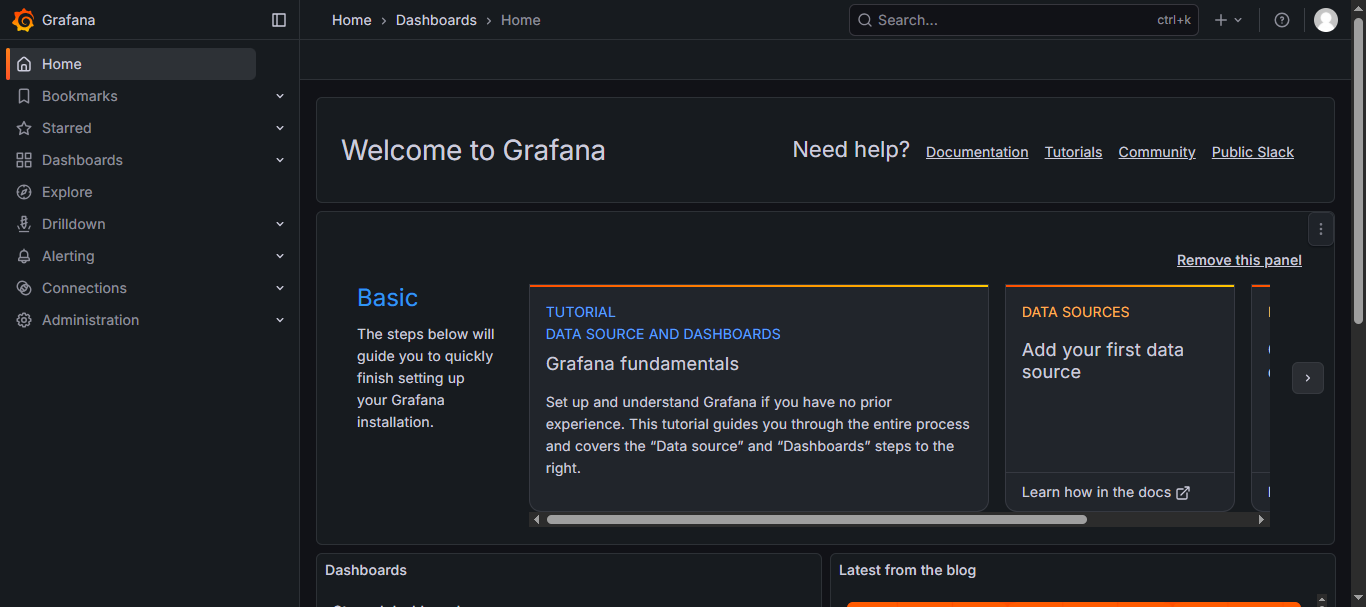
通过浏览器访问 http:// grafana 服务器 IP:3000 就到了登录界面,使用默认的 admin 用户,admin 密码就可以登陆了。

进来需要设置一个新密码,也可以跳过不设置,根据自己需求;

登录进来的页面
6.2.4 修改页面为中文
- 登录 Grafana 后,点击页面右上角的用户头像,在下拉菜单中选择「Profile」。
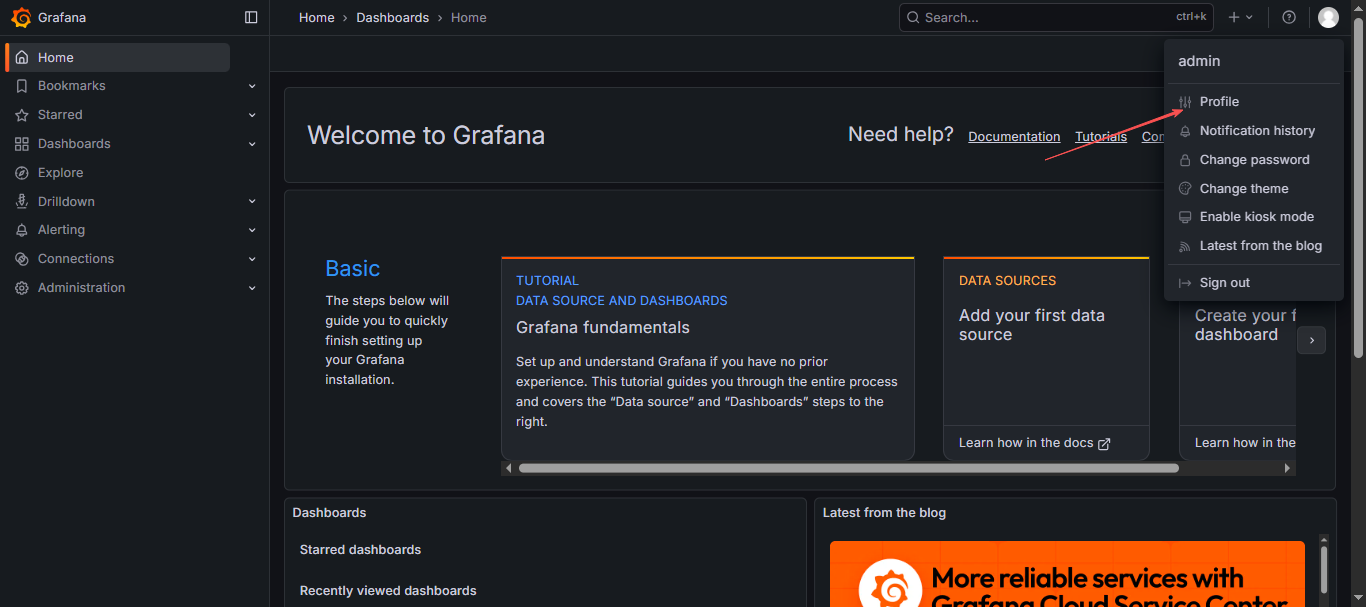
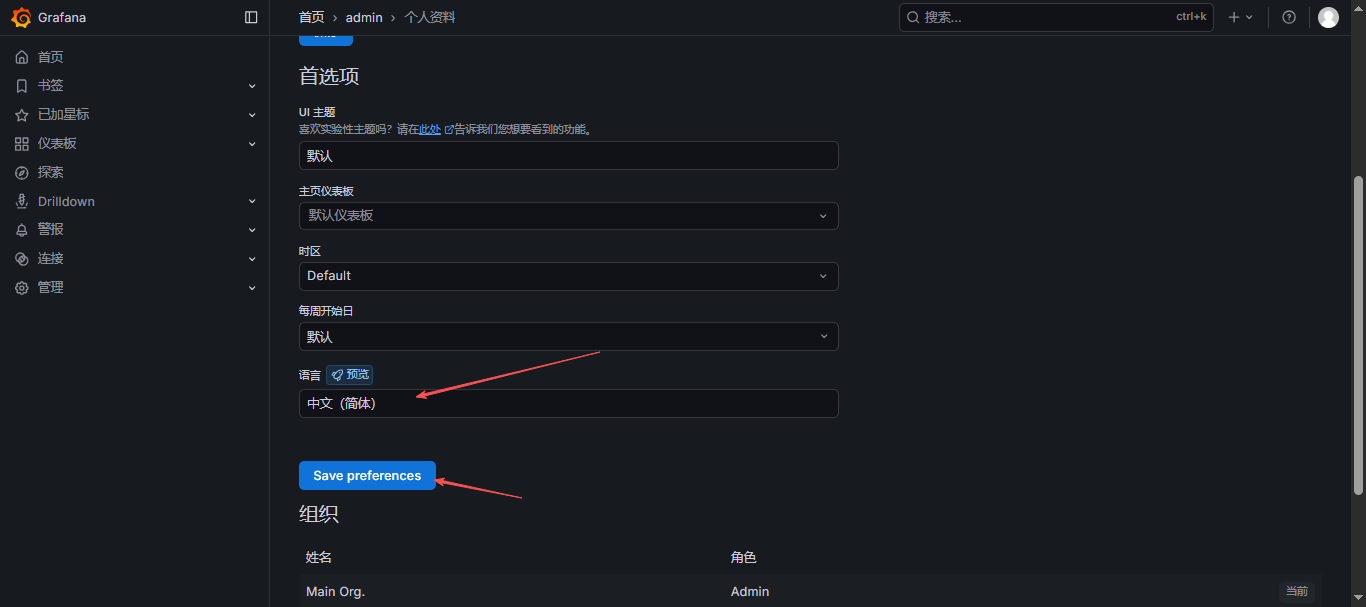
- 在「Preferences」设置页面中,找到「Language」选项;
- 从语言下拉菜单中选择「中文(简体)」;
- 点击「Save」按钮保存设置,界面将立即切换为中文。
6.2.6 Grafana 部署完成
七、相关文章
| 文章标题 | 文章链接 |
|---|---|
| 【Linux】Prometheus + Grafana的使用、监控及设置告警配置 | https://liucy.blog.youkuaiyun.com/article/details/155493459 |



















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











