



Pytorch模型定义与训练技巧

1.模型定义方式——Sequential、ModuleList、ModuleDict
一、Sequential(两种方式——Direct List & Ordered Dict):
#Sequential是手动一层层排列,较直接,且有顺序,定义简单模型的时候用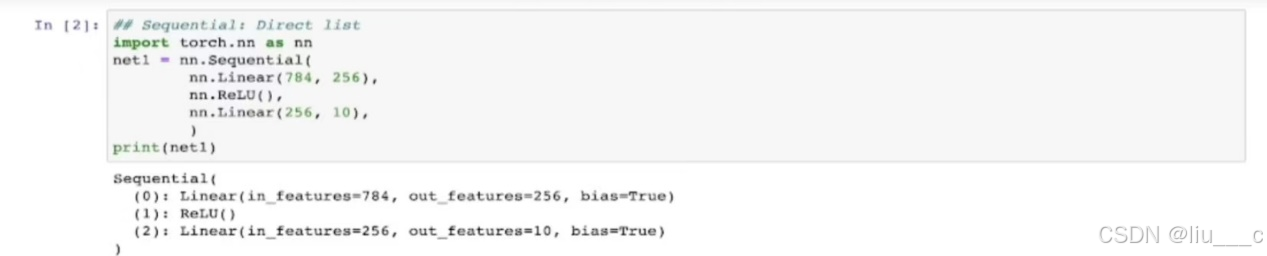
#类似直接创建一个列表,并依次写上每一层
#类似创建一个字典,每一层都有“键”相对应,可以给每一层标注一个名字
二、ModuleList(像建立一个列表,有一些列表的功能,如append):
#ModuleList只定义了一个存储了各个层的列表,但没有定义层与层之间的先后顺序,因此要想定义出一个模型,还需用forward定义一个向前传播的方式,如下图: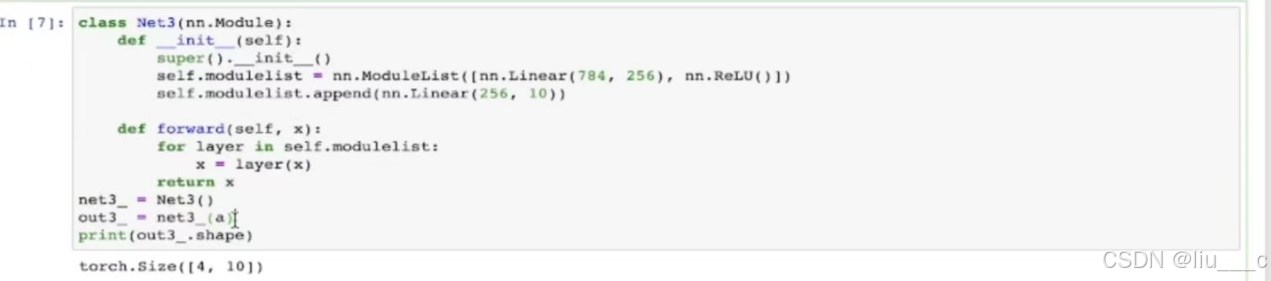
三、ModuleDict(像是ModuleList+Ordered Dict):
#ModuleDict和ModuleList一样,都只是存储了各个层,却没有定义层与层之间的先后顺序,因此它也要用forward定义一个向前传播方式,同上)
# 注意ModuleDict和Ordered Dict定义上也有一些区别。‘ , ’、‘ : ’。(可和上面Ordered Dict那张图对比着看以体会区别)
2.如何利用模型块快速搭建复杂网络(先分别定义各模块,最后再拼接起来)
一、U-Net网络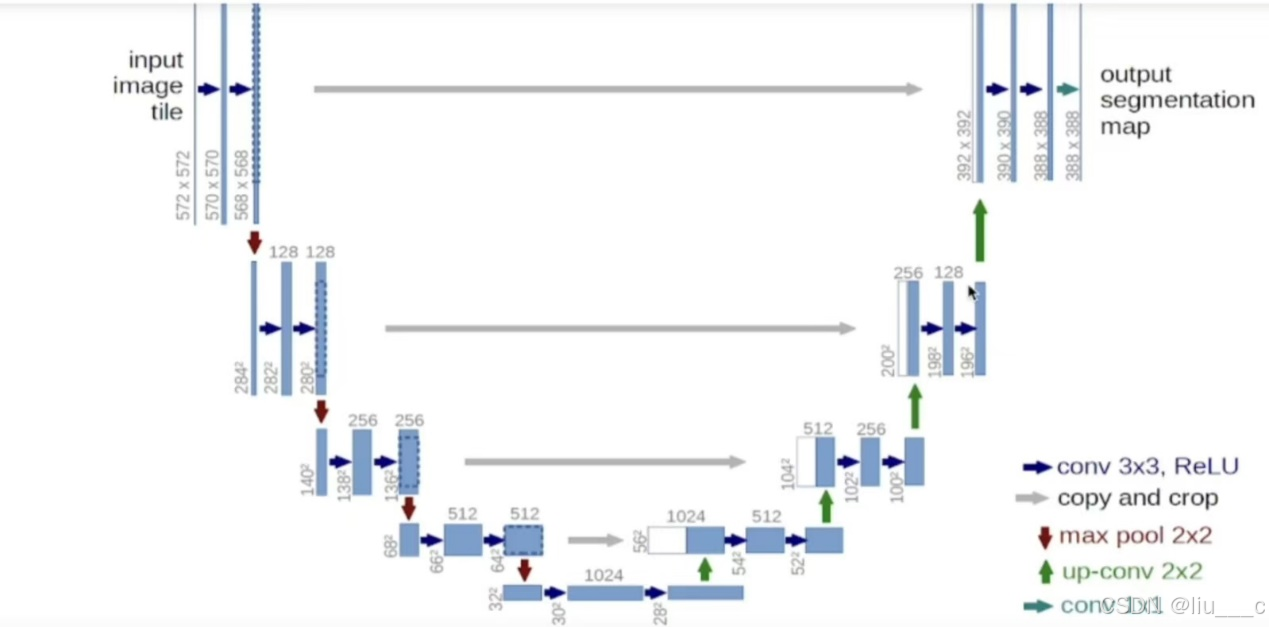

#下采样连接:保留有效信息的同时减少特征图的尺寸,从而降低计算量,提高模型的运行效率。
#上采样连接:下采样连接的逆操作,通过放大特征图或图像尺寸来提高模型的性能和准确性。
二、以U-Net网络为例,了解利用模型块快速搭建复杂网络的过程:
i导入要用的包
j定义双重卷积模块: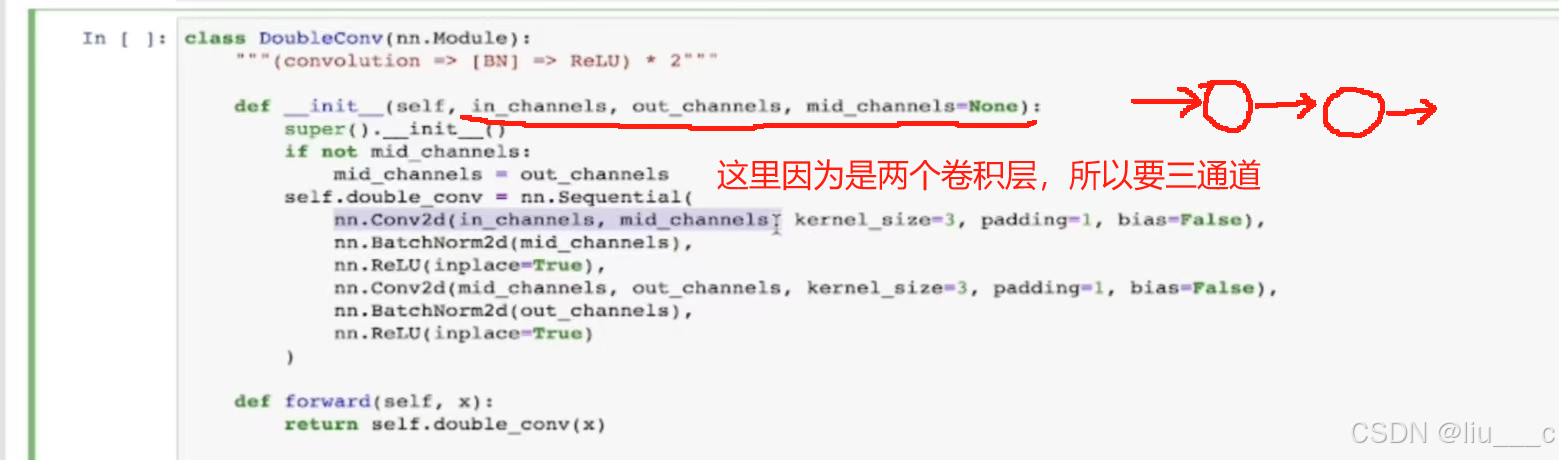
k定义下采样连接模块:
l定义上采样连接模块: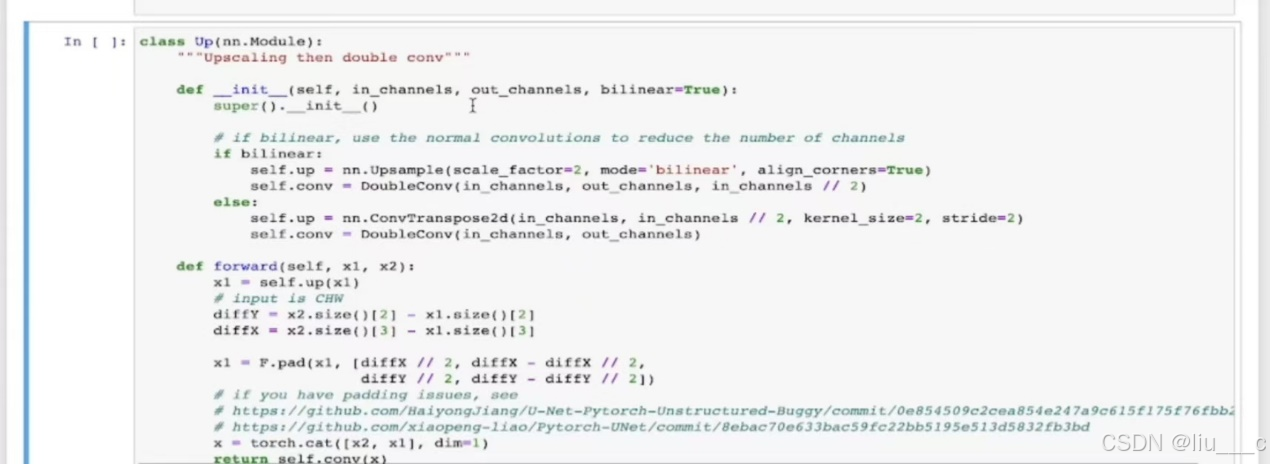
m定义输出模块:
n拼接各模块: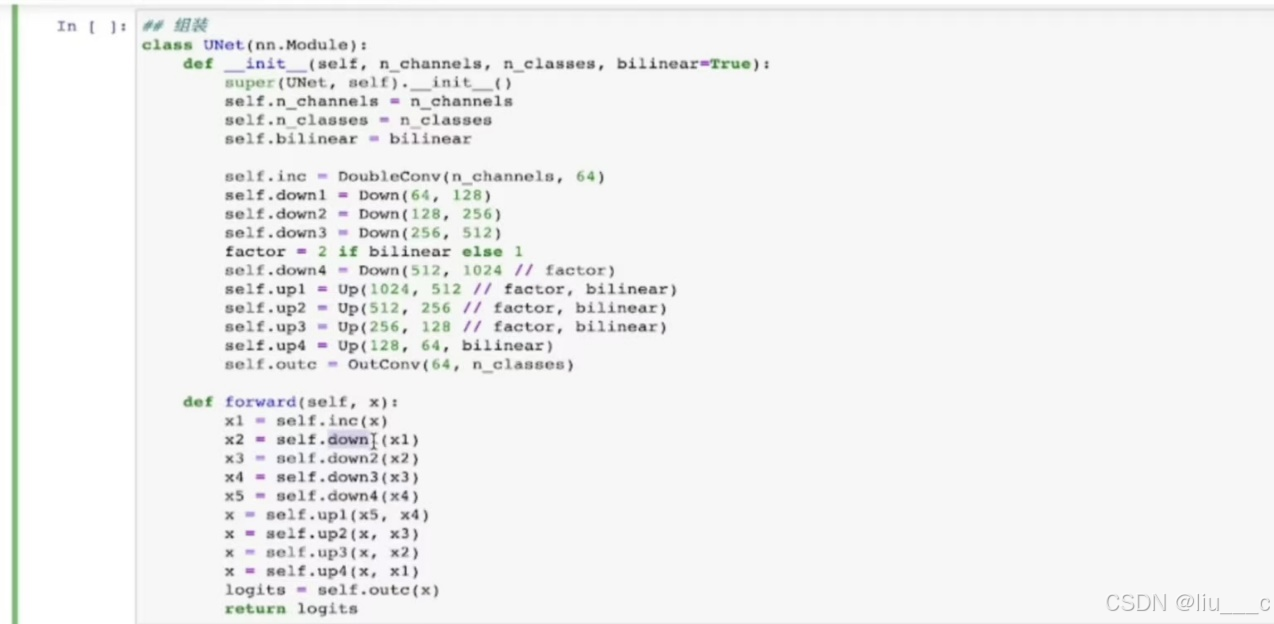
3.模型修改(怎样修改特定层,怎样更灵活地使用模型):
一、修改特定层:
#这里的unet1.outc能够从unet1模型中提取出outc层,=后面是对该层进行的修改,这里是将输出通道数进行了修改(其他层的通道数修改也类似这样)。
二、添加额外输入(在原模型上修改两个点):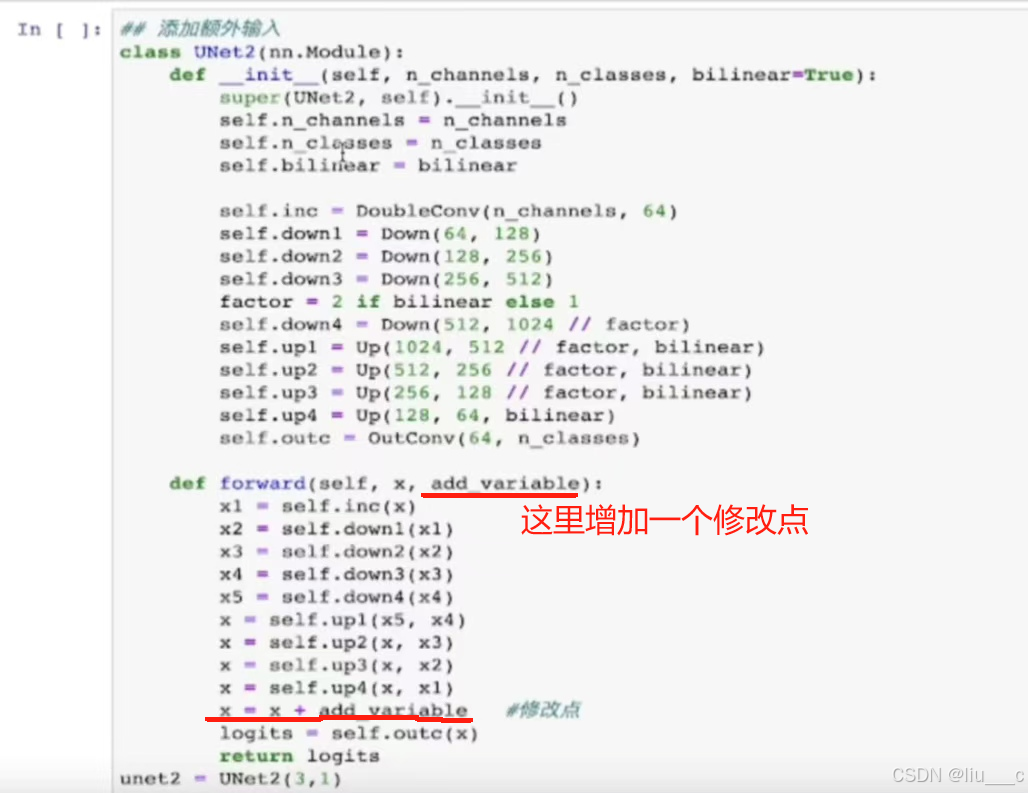
#后续对修改点进行调整即可添加额外输入了
#注意修改层输入后还要对模型定义进行修改,即模型定义中,该层的输入要+1。
三、添加额外输出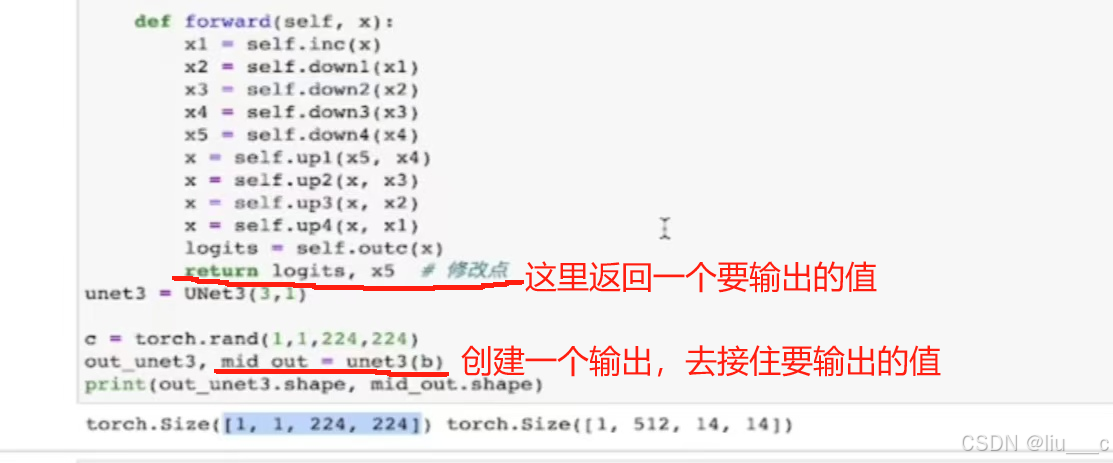
4.模型的保存和读取
#需要考虑两种训练模式(单卡或多卡)下的两种保存类型——4种情况
#保存类型分为保存模型和保存权重
#模型的保存格式有三种,无太大差别,用pth就好了
j单卡模式下保存和读取整个模型:
k单卡模式下保存和读取权重:
#保存方面,和模型的保存无区别;读取方面,要先将权重放到一个预存变量中,再去加载这个变量。
#单卡模型下其实直接保存模型即可,因为单卡模式下,整个模型较权重多出的部分其实很少。
l多卡模式下保存和读取整个模型:
#因为多卡模式下创立的模型是分布在多张卡上的,保存整个模型的话,很可能会导致换台机器模型运行不了的情况发生
m多卡模型下保存和读取模型权重(建议使用):
5.自定义损失函数(这里以定义DiceLoss为例)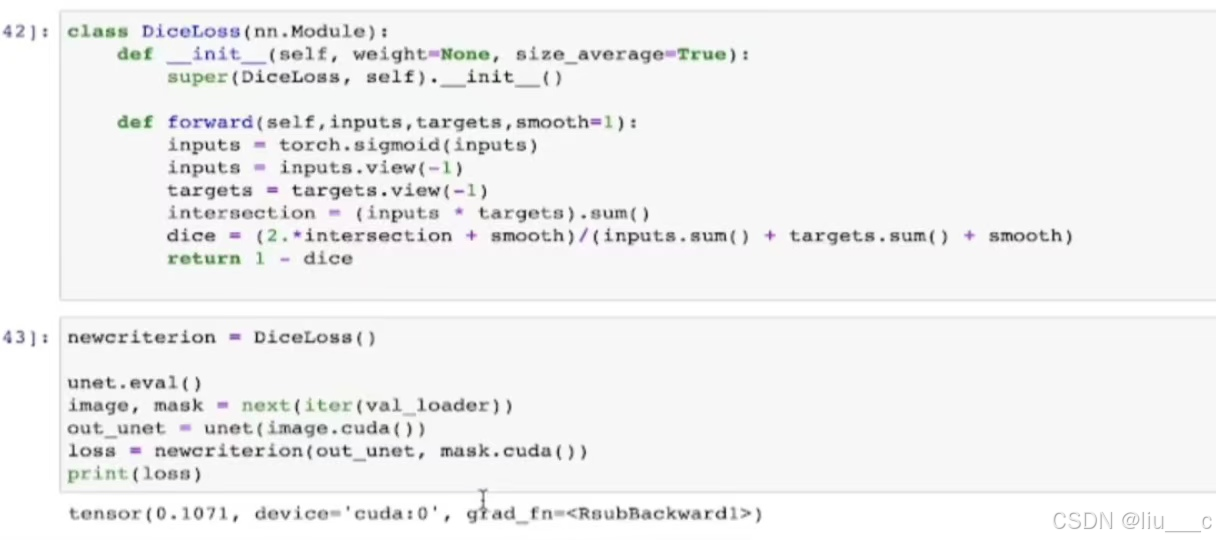
DiceLoss是一个继承自nn.Module的PyTorch类,用于定义一种特定的损失函数,这种损失函数通常用于图像分割等二元分类问题。
__init__ 方法
- __init__(self, weight=None, size_average=True): 这是类的初始化方法。
- weight: 权重参数,这里设置为None,表示默认不使用权重。
- size_average: 一个布尔值,用于指定是否对损失进行平均。
- super(DiceLoss, self).__init__(): 调用父类nn.Module的初始化方法。
forward 方法
- forward(self, inputs, targets, smooth=1): 这是类的前向传播方法,用于计算损失。
- inputs: 模型的预测输出。
- targets: 真实的目标标签。
- smooth: 一个平滑项,用于避免除以零的错误,通常设置为一个非常小的数(如1)。
- torch.sigmoid(inputs): 将inputs通过Sigmoid函数转换为0到1之间的值。
- inputs = inputs.view(-1): 将inputs展平为一维向量。
- targets = targets.view(-1): 将targets也展平为一维向量。
- intersection = (inputs * targets).sum(): 计算预测值和真实值之间的交集。
- dice = (2. * intersection + smooth) / (inputs.sum() + targets.sum() + smooth): 根据Dice系数公式计算损失。Dice系数是一种衡量两个样本相似度的指标,其值范围在0到1之间。在这里,通过1减去Dice系数来得到损失值,因为损失值通常希望越大越好(表示预测越准确)的度量方式在这里被转换为越小越好(表示损失越小)。
- return -dice: 返回损失值(注意这里取了负号,因为通常我们希望最小化损失函数)
6.动态调整学习率
#随着优化的进行,固定的学习率可能无法满足需求,因此需要动态调整学习率
#这里的步就是循环数
7.模型微调(核心在于让一些requires_grad=false):
假设认定一层的参数已经能达到足够好的效果,不想再调整那一层的参数的话,可以把那一层的requires_grad=false。
8.半精度训练:即用一些16位浮点数代替32位浮点数进行训练,可以减少计算量,提高速度,减少显存占用。半精度训练在深度学习领域具有广泛的应用场景,特别是在需要加速训练和减少内存占用的场景中



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









