







 本文记录了在GTX10606g和8g内存的配置下,进行深度学习模型训练的参数调整过程及结果。通过调整batchSize、epochs和max_queue_size,以适应有限的硬件资源,并探讨了这些参数对模型训练的影响。
本文记录了在GTX10606g和8g内存的配置下,进行深度学习模型训练的参数调整过程及结果。通过调整batchSize、epochs和max_queue_size,以适应有限的硬件资源,并探讨了这些参数对模型训练的影响。
接下来我来训练然后做一些实验。
我的机器是GTX1060 6g,8g内存。ubutu16.04,anaconda
2019.2.25
由于我的硬件是比较差的,我调整了三个参数,batchSize,epochs和max_queue_size。
trainGen = HDF5DatasetGenerator(config.TRAIN_HDF5, 32, aug=aug,
preprocessors=[pp, mp, iap], classes=2)#128
# train the network
model.fit_generator(
trainGen.generator(),
steps_per_epoch=trainGen.numImages // 128,
validation_data=valGen.generator(),
validation_steps=valGen.numImages // 128,
epochs=25,#75
max_queue_size=5,#10
callbacks=callbacks, verbose=1)#mix max_queue_size smaller ,since my macine can't afford
batchSize :尝试了128 64最后调整为32才能跑得起来。现象是刚开始还好,后面越来越卡。
epochs:调整为了25,因为一开始不确定能不能跑起来,先设置小一点。
max_queue_size:这个参数我查了下,是缓存batch的,max_queue_size是多少就缓存几个batch。
跑了一晚上的结果:
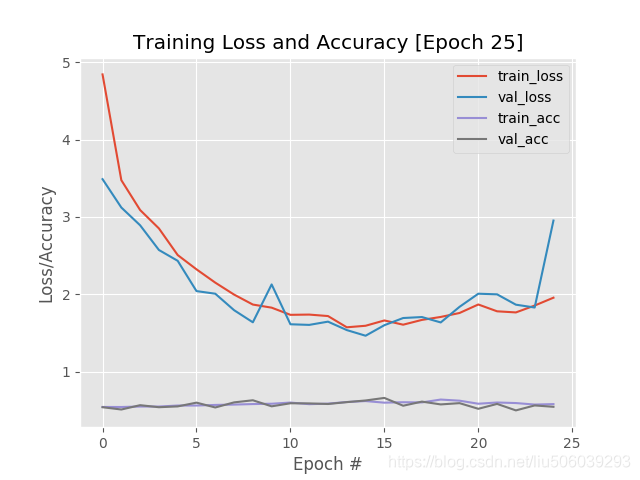
分析:可以看到准确度基本没怎么变化,loss忽高忽低。loss下不去应该是batch设置的太低的原因,然后epochs太小。
改善:今天晚上我把epochs设置回到75,batch没办法就先32试试。另外用下实验室服务器(两块1080ti)试试原来的参数。
2019.2.27
调整epochs为90,batchsize:32。结果训练了54轮挂了。效果比昨天好多了,这也验证了batchsize小的话会增加随机性,不容易收敛。
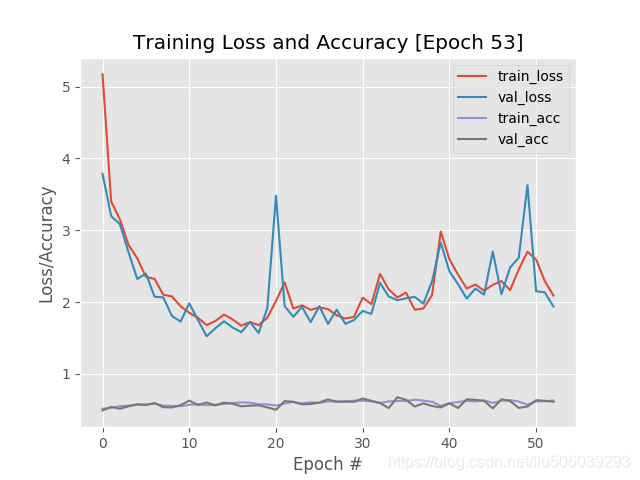
昨天服务器被另一个学长用了,今天晚上这台电脑跑一下resnet的结果。然后借隔壁实验室的用一下,不知道能不能借到。
2019.2.28
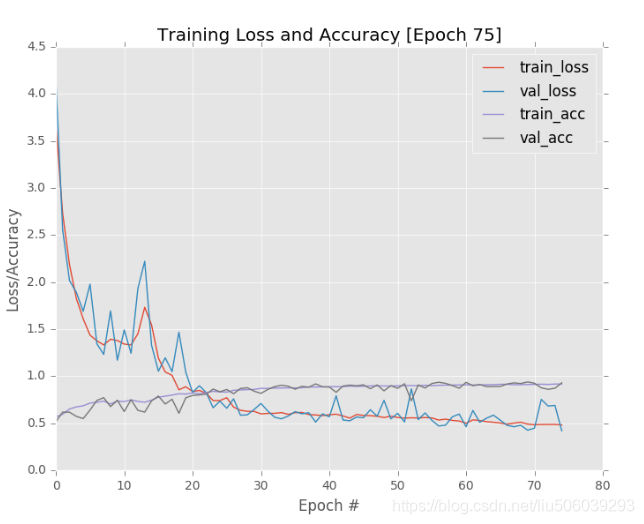
titan v跑了5个小时左右,参数跟作者一样,结果87%

作者的结果:


















 4426
4426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









