






 这篇文章描述了一个SQL查询任务,要求根据date_id和make_name对销售数据进行分组,计算每个组合下的不同lead_id和partner_id数量。使用Pandas库中的groupby、nunique、rename和reset_index方法实现。
这篇文章描述了一个SQL查询任务,要求根据date_id和make_name对销售数据进行分组,计算每个组合下的不同lead_id和partner_id数量。使用Pandas库中的groupby、nunique、rename和reset_index方法实现。
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
Day1
每天的领导和合伙人
| Column Name | Type |
|---|---|
| date_id | date |
| make_name | varchar |
| lead_id | int |
| partner | int |
该表没有主键(具有唯一值的列)。它可能包含重复项。
该表包含日期、产品的名称,以及售给的领导和合伙人的编号。
名称只包含小写英文字母。
对于每一个 date_id 和 make_name,找出 不同 的 lead_id 以及 不同 的 partner_id 的数量。
按 任意顺序 返回结果表。
返回结果格式如下示例所示。
示例1:
输入:
DailySales 表:
+-----------+-----------+---------+------------+
| date_id | make_name | lead_id | partner_id |
+-----------+-----------+---------+------------+
| 2020-12-8 | toyota | 0 | 1 |
| 2020-12-8 | toyota | 1 | 0 |
| 2020-12-8 | toyota | 1 | 2 |
| 2020-12-7 | toyota | 0 | 2 |
| 2020-12-7 | toyota | 0 | 1 |
| 2020-12-8 | honda | 1 | 2 |
| 2020-12-8 | honda | 2 | 1 |
| 2020-12-7 | honda | 0 | 1 |
| 2020-12-7 | honda | 1 | 2 |
| 2020-12-7 | honda | 2 | 1 |
+-----------+-----------+---------+------------+
输出:
+-----------+-----------+--------------+-----------------+
| date_id | make_name | unique_leads | unique_partners |
+-----------+-----------+--------------+-----------------+
| 2020-12-8 | toyota | 2 | 3 |
| 2020-12-7 | toyota | 1 | 2 |
| 2020-12-8 | honda | 2 | 2 |
| 2020-12-7 | honda | 3 | 2 |
+-----------+-----------+--------------+-----------------+
解释:
在 2020-12-8,丰田(toyota)有领导者 = [0, 1] 和合伙人 = [0, 1, 2] ,同时本田(honda)有领导者 = [1, 2] 和合伙人 = [1, 2]。
在 2020-12-7,丰田(toyota)有领导者 = [0] 和合伙人 = [1, 2] ,同时本田(honda)有领导者 = [0, 1, 2] 和合伙人 = [1, 2]。
题解
对于我来说拿到题目首先都是希望能够在自己的笔记本上演示多遍并debug,这里我们需要用pandas创建一共示例表格:
#引入pandas库
import as pd
#创建表格
activities = pd.DataFrame([['2020-06-25','Lipliner'],
['2020-06-25','Mortarboard'],
['2020-06-25','Primer'],
['2020-06-25','Scissors'],
['2020-06-25','Shirt'],
['2020-06-25','Thong'],
['2020-06-25','Vest'],
['2020-06-25','Watch']],
columns=['sell_date','product'])
daily_sales['date_id']=pd.to_datetime(daily_sales['date_id'])#将时间列转换为pandas内部的时间类型,方便后续进行操作
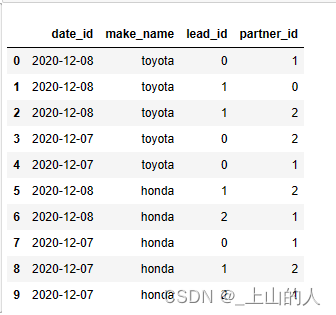
首先想到的就是需要对date_id和make_name这两列进行聚合,然后对后续的两列进行不同值的计数,操作的话就需要用到groupby,nunique,然后还需要对列名进行修改以及生成新的索引,就可以想到rename以及reset_index,这些放一起一行就可以把这个文件解决了,代码如下:
df=daily_sales.groupby(['make_name','date_id']).nunique().rename(columns={'lead_id':'unique_leads','partner_id':'unique_partners'}).reset_index()
这里可以不赋值给新变量df,直接在原数据上操作的话,将reset_index里面的inplace参数设置为True即可。
看看结果:
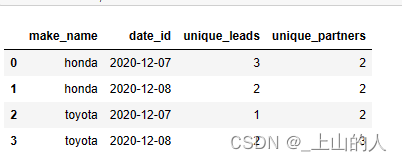
成功拿下,在力扣上提交后可以看到效果还是很不错的

欢迎各位继续关注后续的pandas操作。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









