






pytorch自己定义数据集加载到深度学习模型
我们并不想只使用pytorch提供的mnist、cifar10、cifar100等公开数据集,有的时候我们也想使用自己的数据集训练模型,那么问题来了,如何把我们自己的数据集封装成深度学习可以使用的格式就成了一个脑袋的问题。本文就是记录一下自己是如何解决这个问题的,提供一个实例,大家就可以照葫芦画瓢实现自己心中所想。
import torch
import torch.utils.data as Data
import numpy as np
x = torch.ones(3,32,32) # 假设自己定义的数据集为x
y = torch.zeros(3,32,32) # 假设自己定义的数据集标签为y
dataset1 = Data.TensorDataset(x,y) # 将数据x和标签y封装在一起
loader = Data.DataLoader(
dataset=dataset1, # 数据,封装进Data.TensorDataset()类的数据
batch_size=1, # 每块的大小
shuffle=True, # 要不要打乱数据 (打乱比较好)
num_workers=2, # 多进程(multiprocess)来读数据
)
# 模型训练经常见到的代码,是不是很熟悉
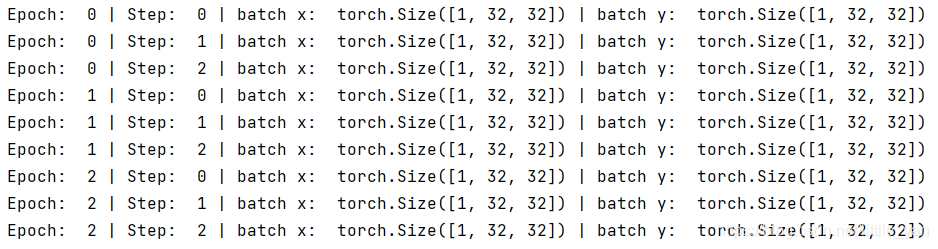
for epoch in range(3):
for step, (batch_x, batch_y) in enumerate(loader):
print('Epoch: ', epoch, '| Step: ', step, '| batch x:
batch_x.shape, '| batch y: ', batch_y.shape)
运行结果下图所示:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









