







网站选择
首先我看了下,腾讯的数据并不是很全,只有一天的,或者说我技艺不精,没发现其他的数据,后来观察了很久,发现丁香医生的数据有各个国家的历史数据,因此选用丁香医生的网址进行爬取
丁香医生网址
观察网站结构

在getListByCountryTypeService2true栏中有各个国家的当前感染人数的数据,
其中statisticsData中的.json文件里含有各个国家的历史数据。
同样fetchRecentStat里面也有中国各个省市的历史数据(我只爬了国家的,其实原理一样,稍微改一下即可)
知识预备
如果看不懂的话需要学习一下库的基本使用,代码并不是很难。没有加其他的东西,看不懂的复制方法百度即可。
需要了解的python的库
numpy
pandas
json
requests
BeautifulSoup
HTML网站的基本结构
爬虫要用到的一些网站数据。
python的基本使用。
代码
代码本人均跑通,报错注意更改写入文件的地址
爬取到的数据(之后改成了excel格式并进行了汇总,也可以写入数据库,稍作更改即可)
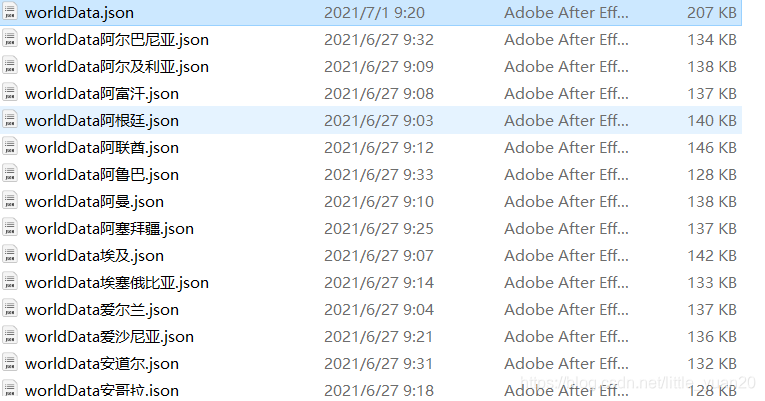
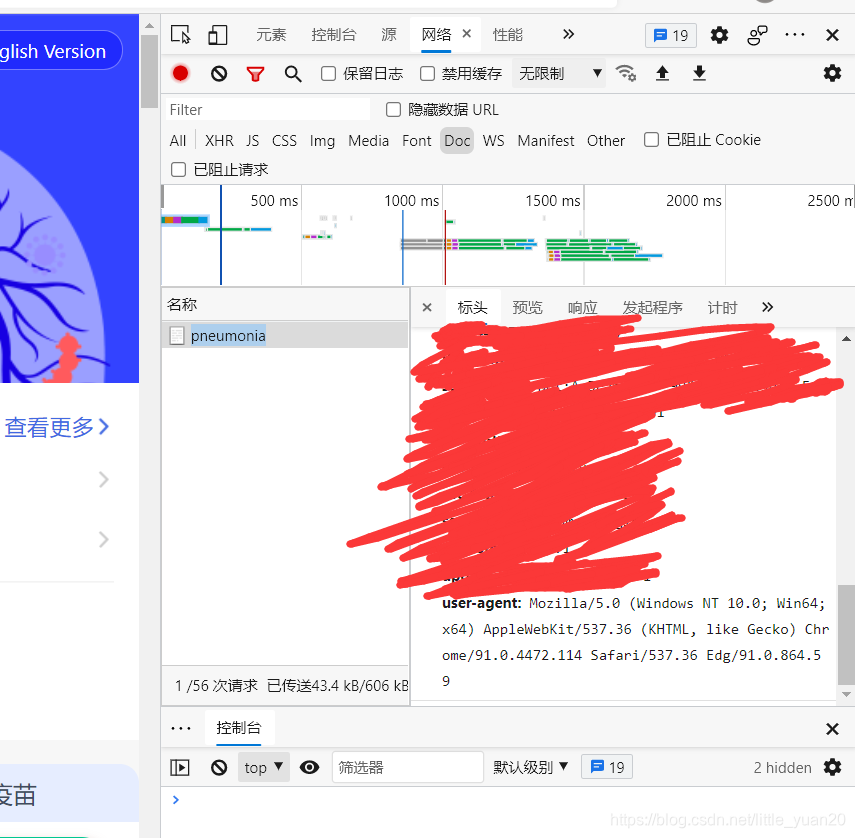
代码里的header可以网页自己提取,也可以用我的。
右键检查->选择网络->运行->双击名称->滚动到最底下复制粘贴。
共分为四个文件
#本块代码获取到的是总世界的json数据
import requests
import re
import json
from bs4 import BeautifulSoup
def getOriHtmlText(url,code='utf-8'):
try:
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36 Edg/91.0.864.54'
}
r=requests.get(url,timeout=30,headers=headers)
r.raise_for_status()
r.encoding=code
return r.text
except:
return "There are some errors when get the original html!"
def getTheList(url):
html=getOriHtmlText("https://ncov.dxy.cn/ncovh5/view/pneumonia")
soup=BeautifulSoup(html,'xml')
# script=soup.find_all('script',{"id":"getListByCountryTypeService2true"})
# print(script.find(''))
htmlBodyText=soup.body.text
# 获取国家数据
worldDataText=htmlBodyText[htmlBodyText.find('window.getListByCountryTypeService2true = '):]
worldDataStr = worldDataText[worldDataText.find('[{'):worldDataText.find('}catch')]
worldDataJson=json.loads(worldDataStr)
with open(r"F:\I_love_learning\junior\机器学习\课程设计\data\worldData.json","w",errors='ignore') as f:
json.dump(worldDataJson,f)
print("写入国家数据文件成功!")
'''
provinceDataText = htmlBodyText[htmlBodyText.find('window.getAreaStat = '):]
provinceDataStr = provinceDataText[provinceDataText.find('[{'):provinceDataText.find('}catch')]
provinceDataJson=json.loads(provinceDataStr)
with open("../data/provinceData.json","w") as f:
json.dump(provinceDataJson,f)
print("写入省份数据文件成功!")
'''
getTheList("https://ncov.dxy.cn/ncovh5/view/pneumonia")
#本段代码是提取刚刚获得的worlddata里面各个国家的数据,并写入json
import json
import requests
import time
def deal_worlddatalist():
with open("F:\I_love_learning\junior\机器学习\课程设计\data\worldData.json",'r') as f:
worldDataJson=json.load(f)
# print(len(worldDataJson))
# print(worldDataJson)
for i in range(0,len(worldDataJson)):
print(worldDataJson[i]['provinceName']+" "+worldDataJson[i]['countryShortCode']+" "+worldDataJson[i]['countryFullName']+" "+worldDataJson[i]['statisticsData'])
return worldDataJson
def get_the_world_data():
# 获取每个国家对应的json
worldDataJson=deal_worlddatalist()
# 记录错误数量
errorNum=0
for i in range(0,len(worldDataJson)):
provinceName=worldDataJson[i]['provinceName']
try:
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36 Edg/91.0.864.54'
}
r = requests.get(worldDataJson[i]['statisticsData'], timeout=30, headers=headers)
r.raise_for_status()
r.encoding = 'utf-8'
everCountryDataJson = json.loads(r.text)
toWriteFilePath="F:\I_love_learning\junior\机器学习\课程设计\data\worldData"+provinceName+".json"
with open(toWriteFilePath,'w') as file:
json.dump(everCountryDataJson, file)
print(provinceName + " 数据得到!")
time.sleep(10)
except:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4976
4976

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











