






1.问题描述
sql server位于A机器,windows10操作系统
mysql位于B机器,windows10操作系统
B机器上使用mysql workbench,导入的时候每次仅仅导入2574条数据之后便中断了,csv中有2686365条数据
csv文件无论是使用记事本还是sublime都能正常打开,中英文正常显示,没有乱码
但是就是导入mysql会中断
使用python的时候没法使用utf8打开,只能使用gbk编码打开,而且读取到2576行的时候,显示
UnicodeDecodeError: 'gbk' codec can't decode byte 0xaa in position 5450: illegal multibyte sequence
曾将csv转为xlsx文件,再转为csv,仍旧是读取到2576行的时候报解码错误。
2.UTF-8-BOM编码
使用notepad++打开以后发现编码方式不是gbk也不是utf-8,而是UTF-8-BOM

在notepad++中点击“编码”,转换为UTF-8编码以后,再导入mysql报错:
UnicodeDecodeError: 'gbk' codec can't decode byte 0xa1 in position 4: illegal multibyte sequence
一条数据都导入不了了。

至于为什么python使用gbk读取utf-8-bom编码文件,我猜想应该是gbk和utf-8-bom编码有交集
3.解决办法
最后:使用Python读取notepad++将utf-8-bom编码转换为utf-8编码后的文件,转换为sql脚本

4.新的解决办法
过几天又发现了一个解决办法:使用python将utf8编码的csv文件转换为gbk编码的文件:
def csv_encoding_transform(src,dst):
with open(src, 'r', encoding='utf8') as csvfile:
content = csvfile.read()
with open(dst, 'w', encoding='gbk') as csvfile2:
csvfile2.write(content)
这个代码是生效的,之前写了一个转编码方式的代码不生效:
def csv_encoding_transform(src,dst):
with open(src, 'r', encoding='utf8') as csvfile:
content = csvfile.read()
with open(dst, 'wb') as csvfile2:
csvfile2.write(content.encode("gbk"))5.新发现
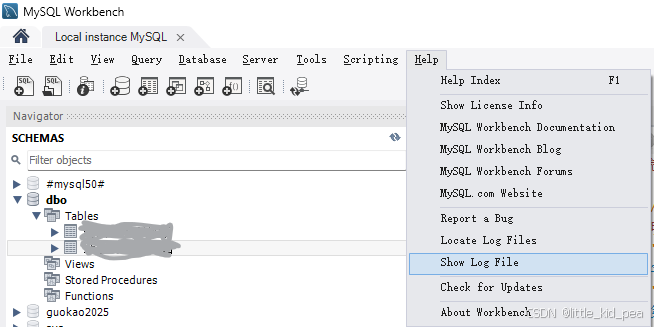
通过点击Help/Show Log File发现日志文件内容:
15:00:29 [ERR][ pymforms]: Unhandled exception in Python code:
Traceback (most recent call last):
File "C:\Program Files\MySQL\MySQL Workbench 8.0 CE\workbench\wizard_page_widget.py", line 97, in go_next
self.main.go_next_page()
File "C:\Program Files\MySQL\MySQL Workbench 8.0 CE\workbench\wizard_form.py", line 76, in go_next_page
self.pages[index].page_activated(True)
File "C:\Program Files\MySQL\MySQL Workbench 8.0 CE\modules\sqlide_power_import_wizard.py", line 185, in page_activated
self.call_create_preview_table()
File "C:\Program Files\MySQL\MySQL Workbench 8.0 CE\modules\sqlide_power_import_wizard.py", line 343, in call_create_preview_table
self.create_preview_table(self.call_analyze())
^^^^^^^^^^^^^^^^^^^
File "C:\Program Files\MySQL\MySQL Workbench 8.0 CE\modules\sqlide_power_import_wizard.py", line 352, in call_analyze
if not self.active_module.analyze_file():
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Program Files\MySQL\MySQL Workbench 8.0 CE\modules\sqlide_power_import_export_be.py", line 505, in analyze_file
line = csvfile.readline()
^^^^^^^^^^^^^^^^^^
UnicodeDecodeError: 'gbk' codec can't decode byte 0xa1 in position 5: illegal multibyte sequence
原来MySQL Workbench的Data Import Wizard 是通过python脚本导入文件的
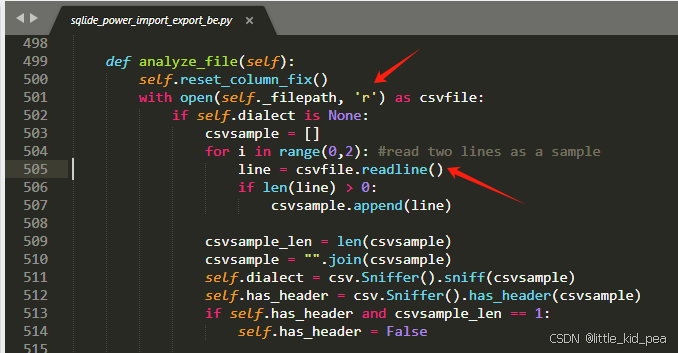
open函数并没有指定encoding参数,使用的是默认编码
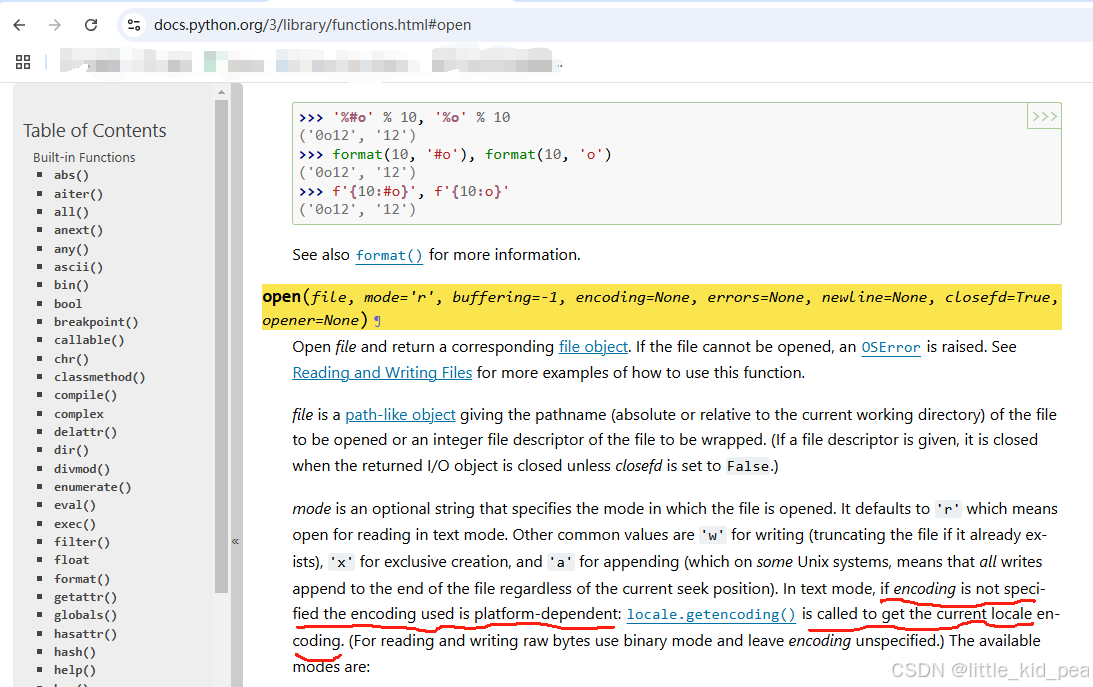
查看Python官方文档得知,encoding默认编码与平台相关


MySQL Workbench有自己的python.exe
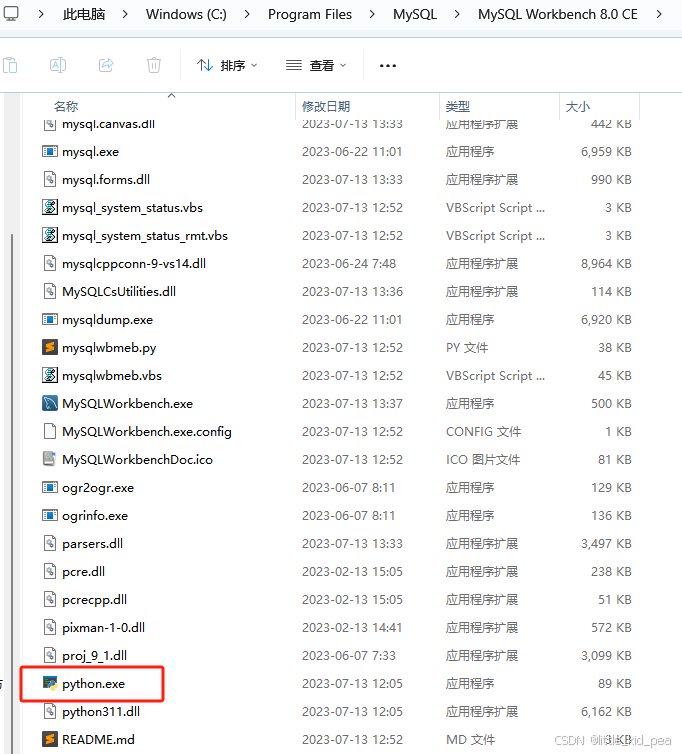
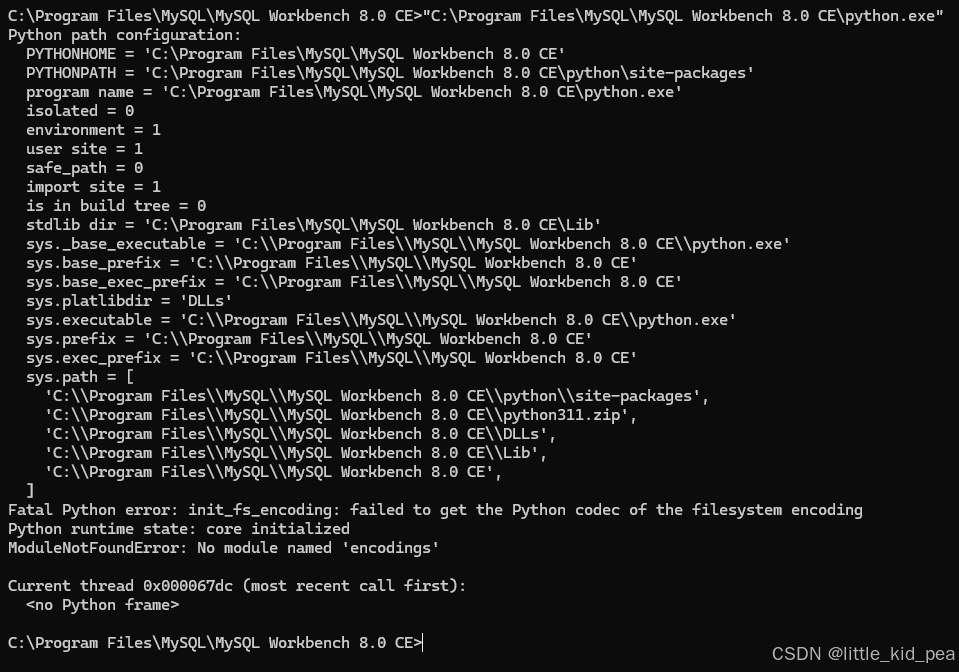
但是直接运行这个python.exe是不行的
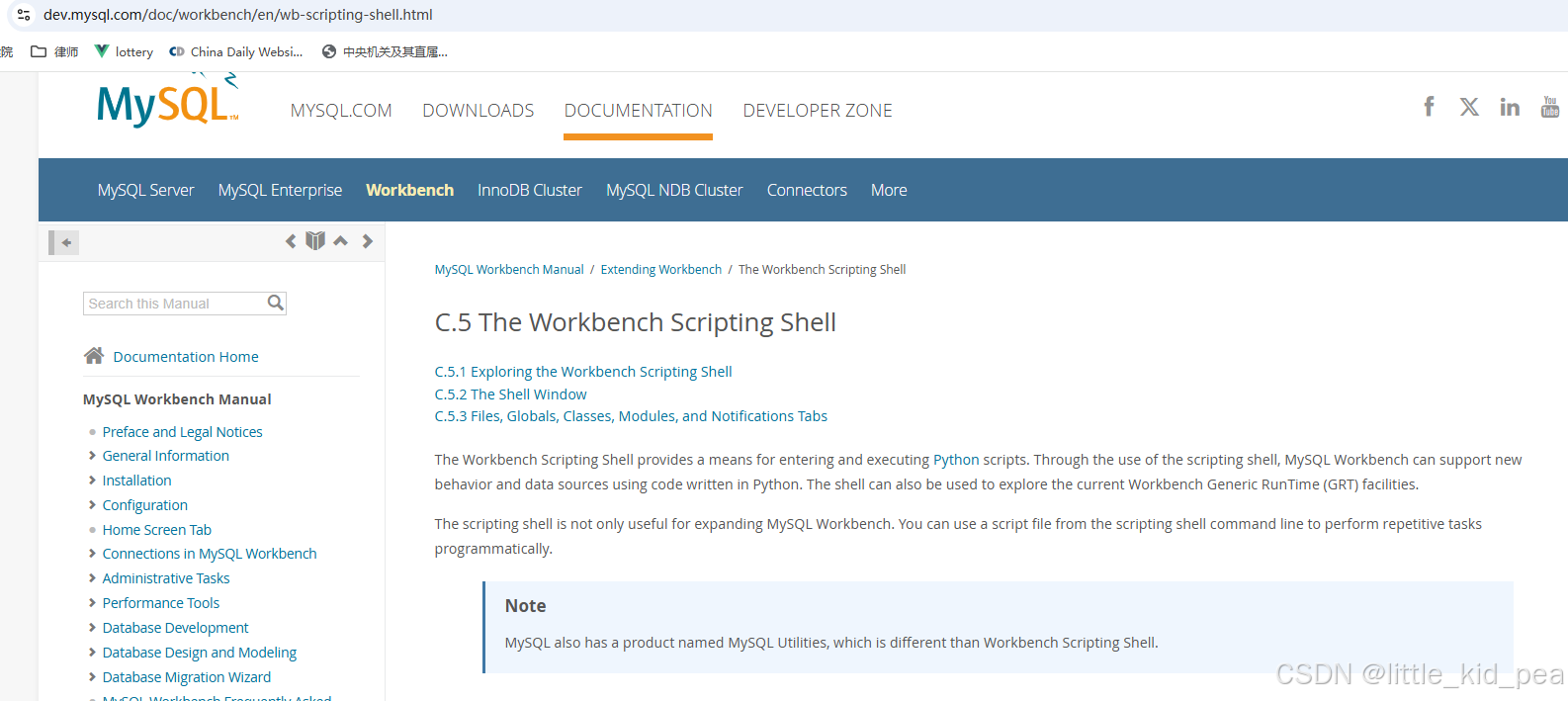
MySQL 文档中提供了一个运行python代码的方法:Scripting Shell,快捷键 ctrl+f3
需要新建一个python script
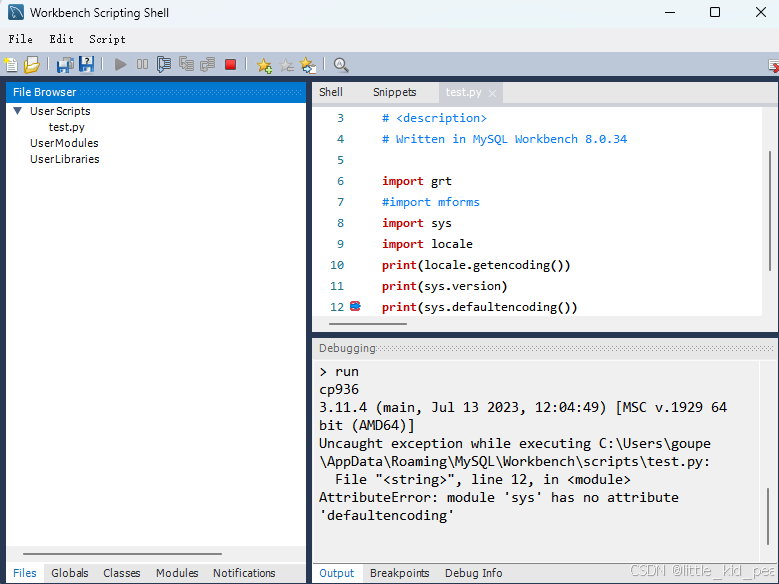
可以看到locale.getencoding()输出的是cp936,Python的版本号是3.11.4
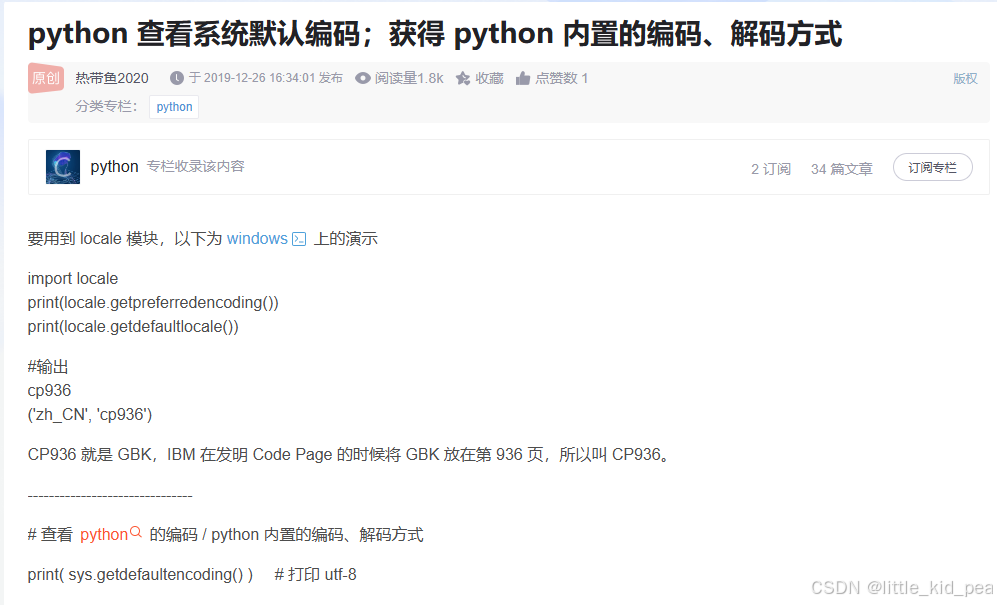
而cp936就是GBK

















 1302
1302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









