







 本文介绍如何使用Python爬虫技术抓取指定网站的蔬菜品名、价格区间等信息,并将其整理为CSV文件,过程中遇到的编码问题及解决方案也一并分享。
本文介绍如何使用Python爬虫技术抓取指定网站的蔬菜品名、价格区间等信息,并将其整理为CSV文件,过程中遇到的编码问题及解决方案也一并分享。
目录
需求分析:
1.获取蔬菜品名、最低价、最高价等信息并将其保存为csv文件
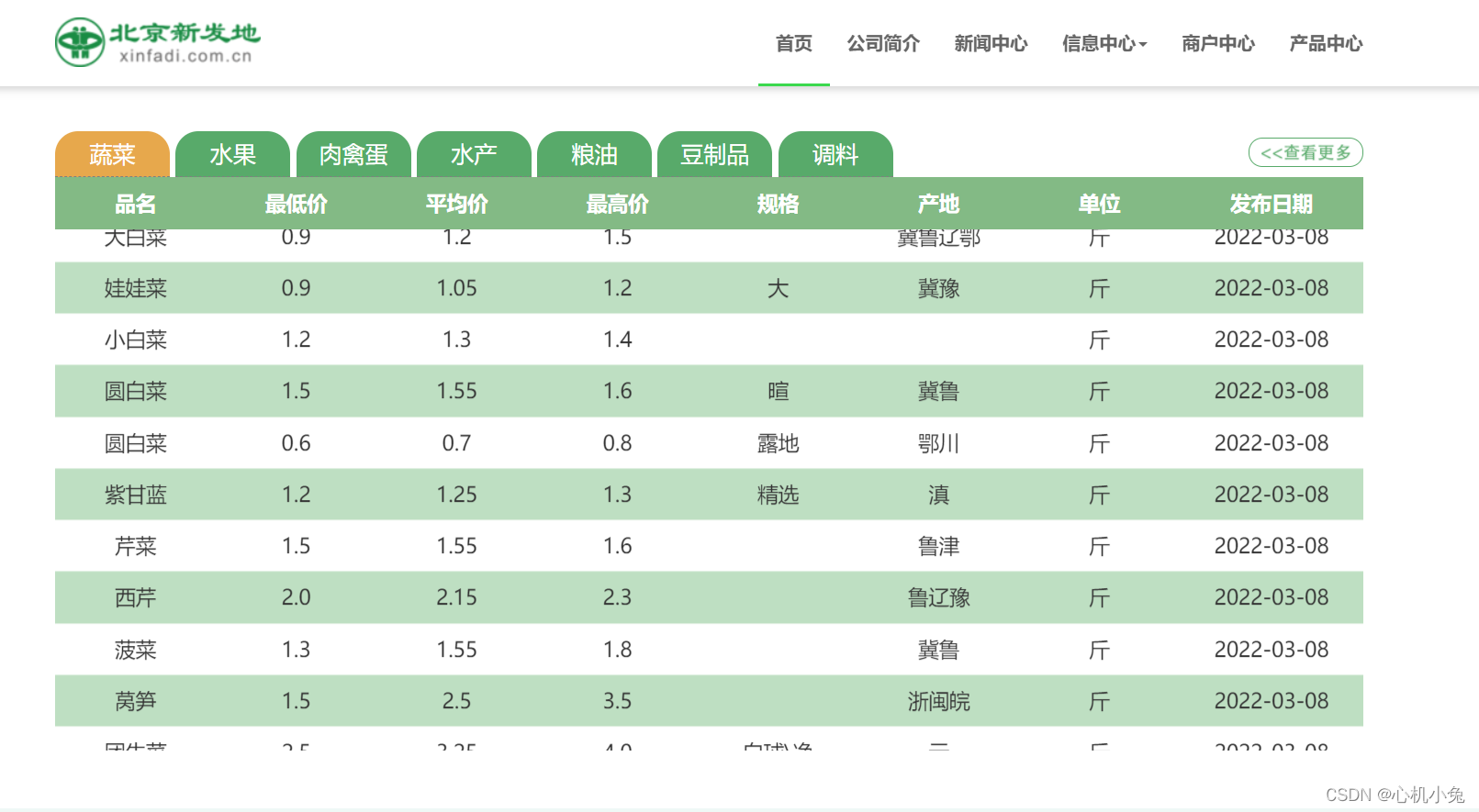
网页分析
F12查看网页源码
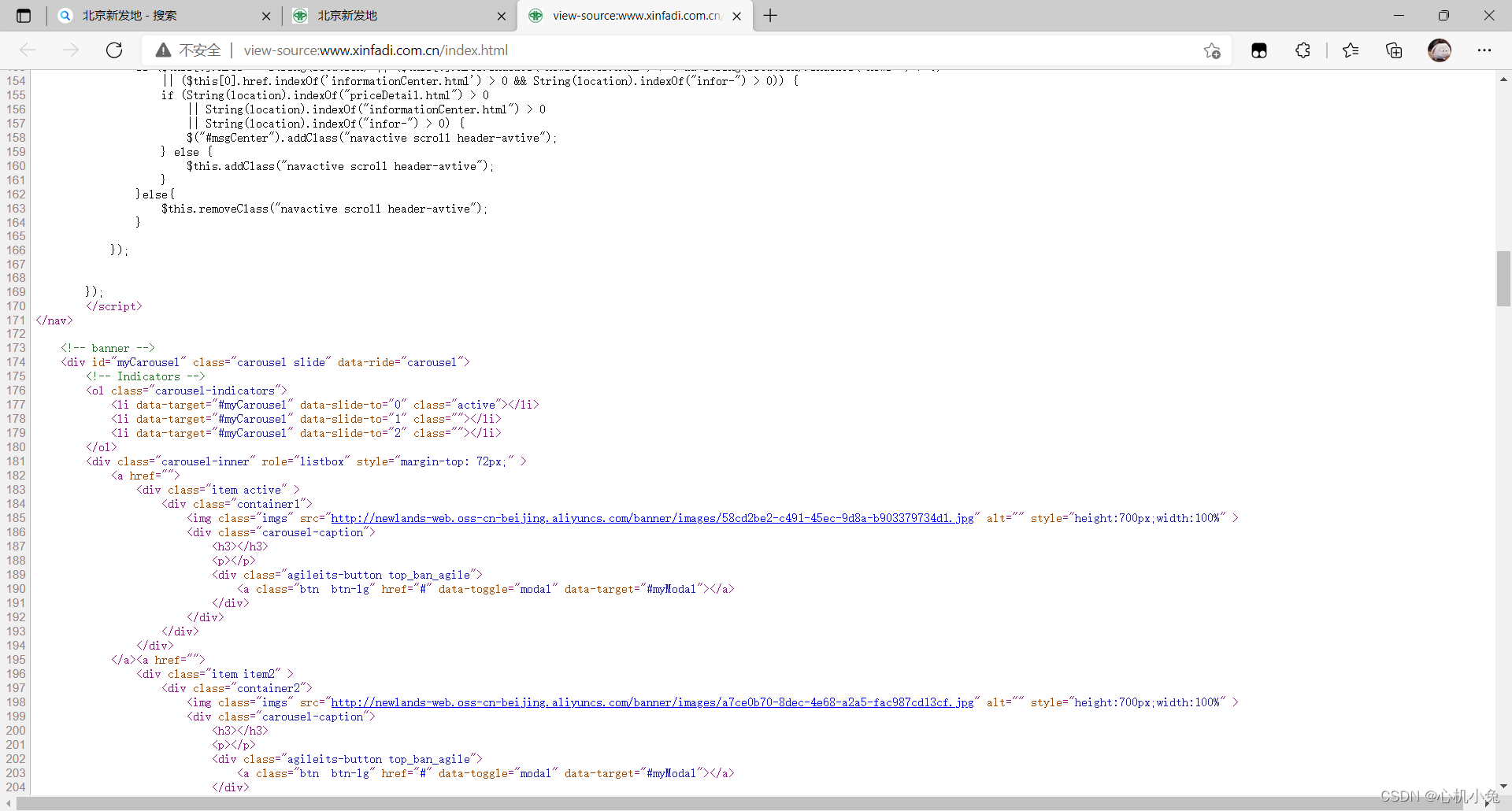
发现没有需要找的元素相关的信息,不要慌,找到相应数据接口就行了,在开发者工具中就能找到
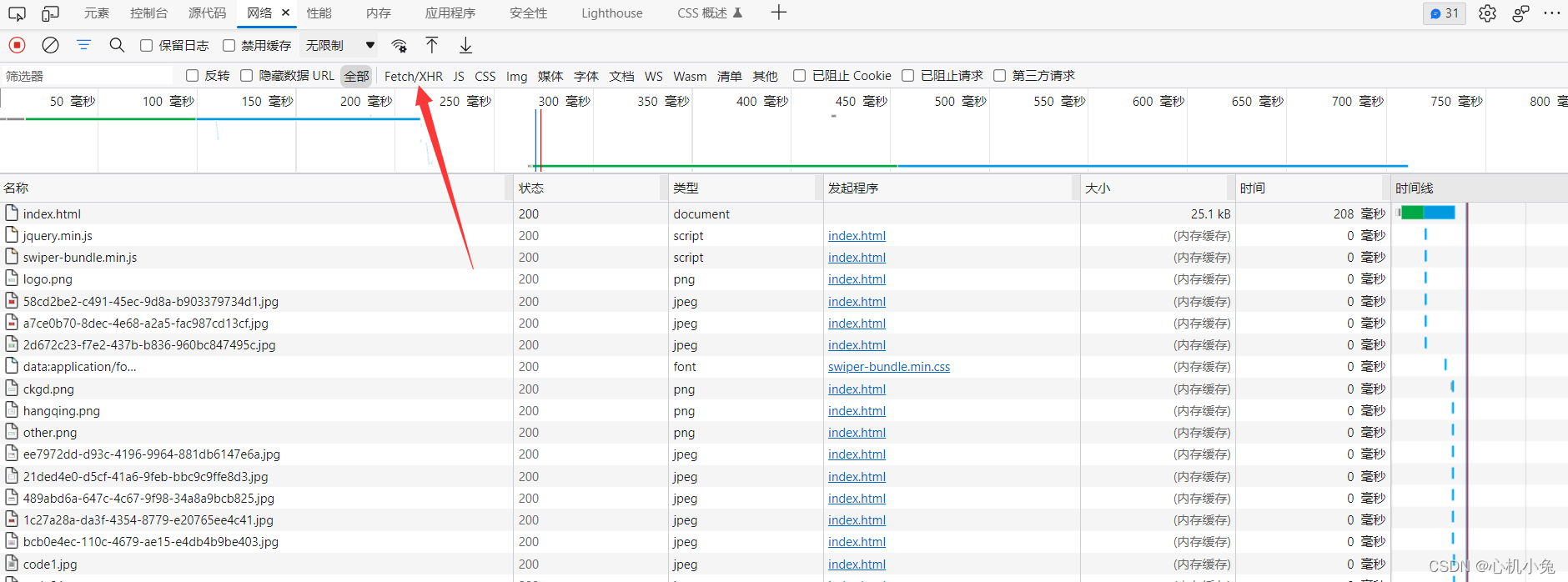
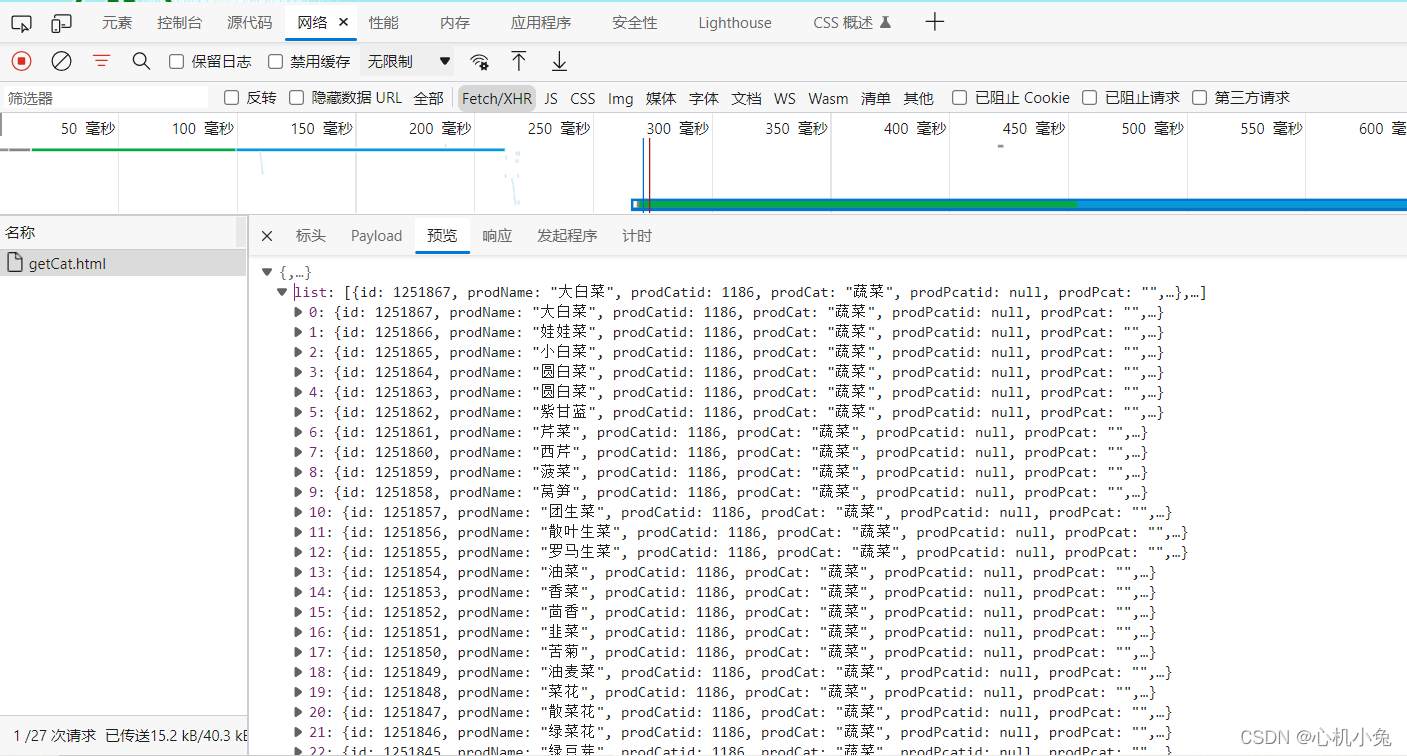
如果网页返回的东西比较多的话,没办法,一个一个去找吧,我也不会,会的大哥麻烦留言指点一下
然后就是把这个页面的url复制下来开始敲
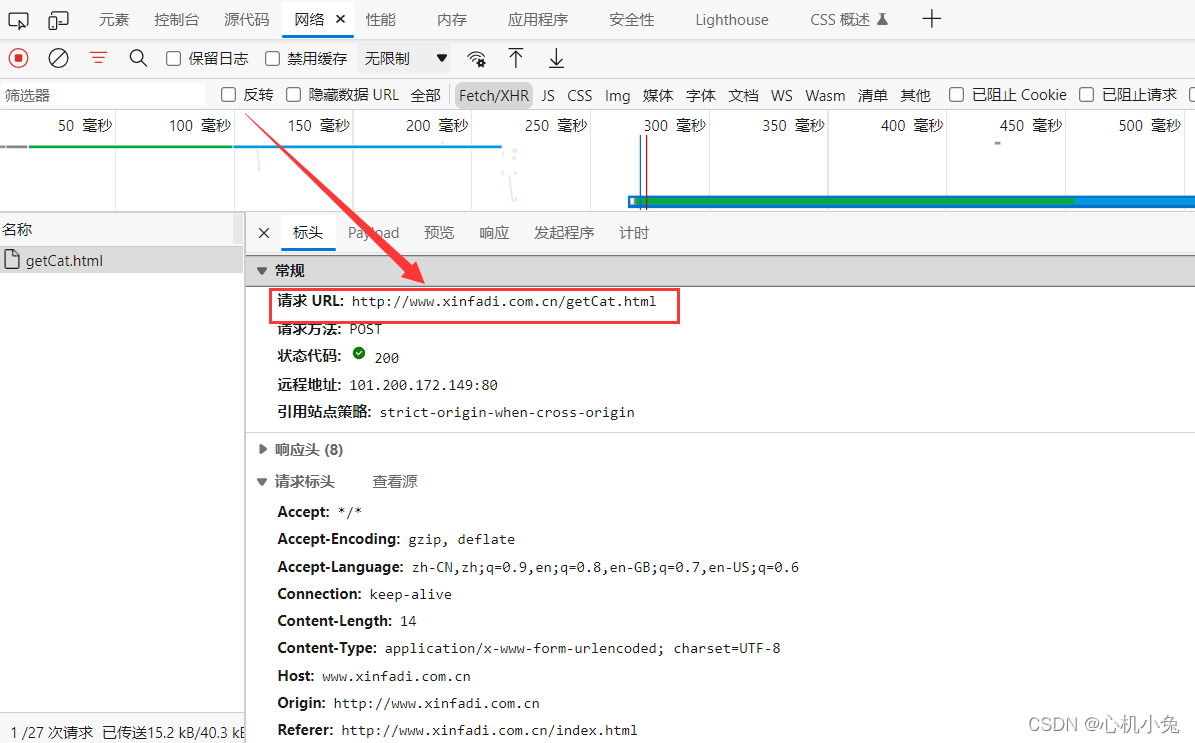
代码实现
比较简单,不需要定义函数或者类啥的,简单粗暴一点
# 这个网页还是比较简单好爬的,不需要很大的解析量,不需要导入正则或者bs4之类的包
import requests
url = 'http://www.xinfadi.com.cn/getCat.html'
# 养成好习惯,先加个头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 Edg/98.0.1108.62'
}
resp = requests.post(url,headers=headers).json() # requests模块中带有将html转换成字典的方法
# print(resp['list'])
# 提取需要的键值对
data = resp['list']
# print(data)
# 文件保存
with open('蔬菜价格.csv', 'w', encoding='utf-8') as f:
f.write('名称,类型,最低价,最高价,平均价,来源,单位,日期'+'\n')
for i in data:
final = {
'蔬菜名': i['prodName'],
'类型': i['prodCat'],
'最低价': i['lowPrice'],
'最高价': i['highPrice'],
'平均价': i['avgPrice'],
'来源': i['place'],
'单位': i['unitInfo'],
'日期': i['pubDate']
}
final = '{蔬菜名},{类型},{最低价},{最高价},{平均价},{来源},{单位},{日期}'.format(**final)
with open('蔬菜价格.csv', 'a', encoding='utf-8') as f:
f.write(final + '\n')效果
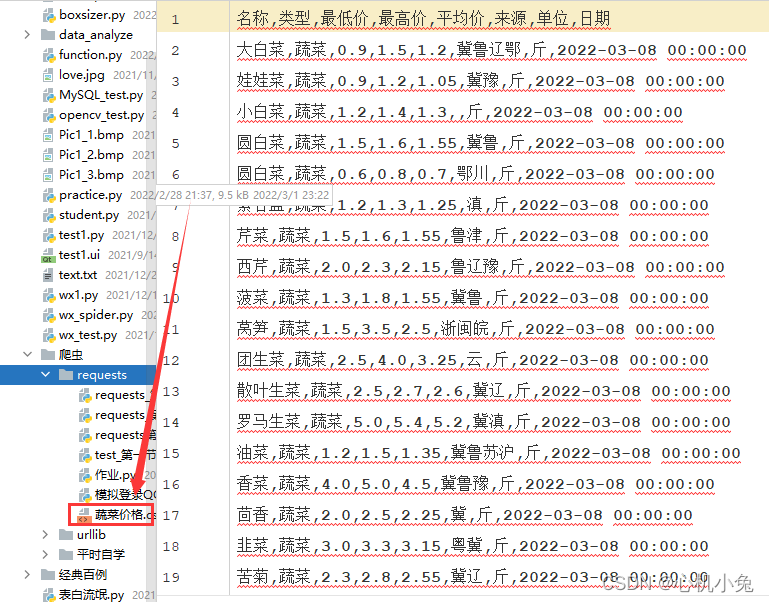
在excel中打开出现了乱码,未解决 ,发现原因的大佬麻烦留言教教小弟


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











